목차

저희는 GLM-4.7, Z.ai의 최신 플래그십 Model을 SiliconFlow에서 Day 0 지원으로 사용할 수 있게 되었다는 소식을 전하게 되어 기쁩니다. 이전 모델인 GLM-4.6과 비교하여, 이번 릴리스는 코딩, 복잡한 추론, 도구 활용에 걸쳐 상당한 발전을 가져오며, Claude Sonnet 4.5와 GPT-5.1 같은 업계 선두주자와 경쟁할 수 있는 성능을 제공합니다.
현재, SiliconFlow는 GLM Model 시리즈 전체를 지원하며, GLM-4.5, GLM-4.5-Air, GLM-4.5V, GLM-4.6, GLM-4.6V, 그리고 이제 GLM-4.7을 포함합니다.
SiliconFlow Day 0 지원:
경쟁력 있는 가격: GLM-4.7 $0.6/M tokens (Input) 및 $2.2/M tokens (Output)
205K 컨텍스트 윈도우: 복잡한 코딩 작업, 깊은 문서 분석, 확장된 에이전틱 워크플로를 처리합니다.
Anthropic 및 OpenAI 호환 API: Claude Code, Kilo Code, Cline, Roo Code 및 기타 메인스트림 에이전트 워크플로에 원활하게 통합하여 SiliconFlow를 통해 배포합니다.
GLM-4.7의 특별함
GLM-4.7, 여러분의 새로운 코딩 파트너는 다음과 같은 기능을 제공합니다:
핵심 코딩 우수성
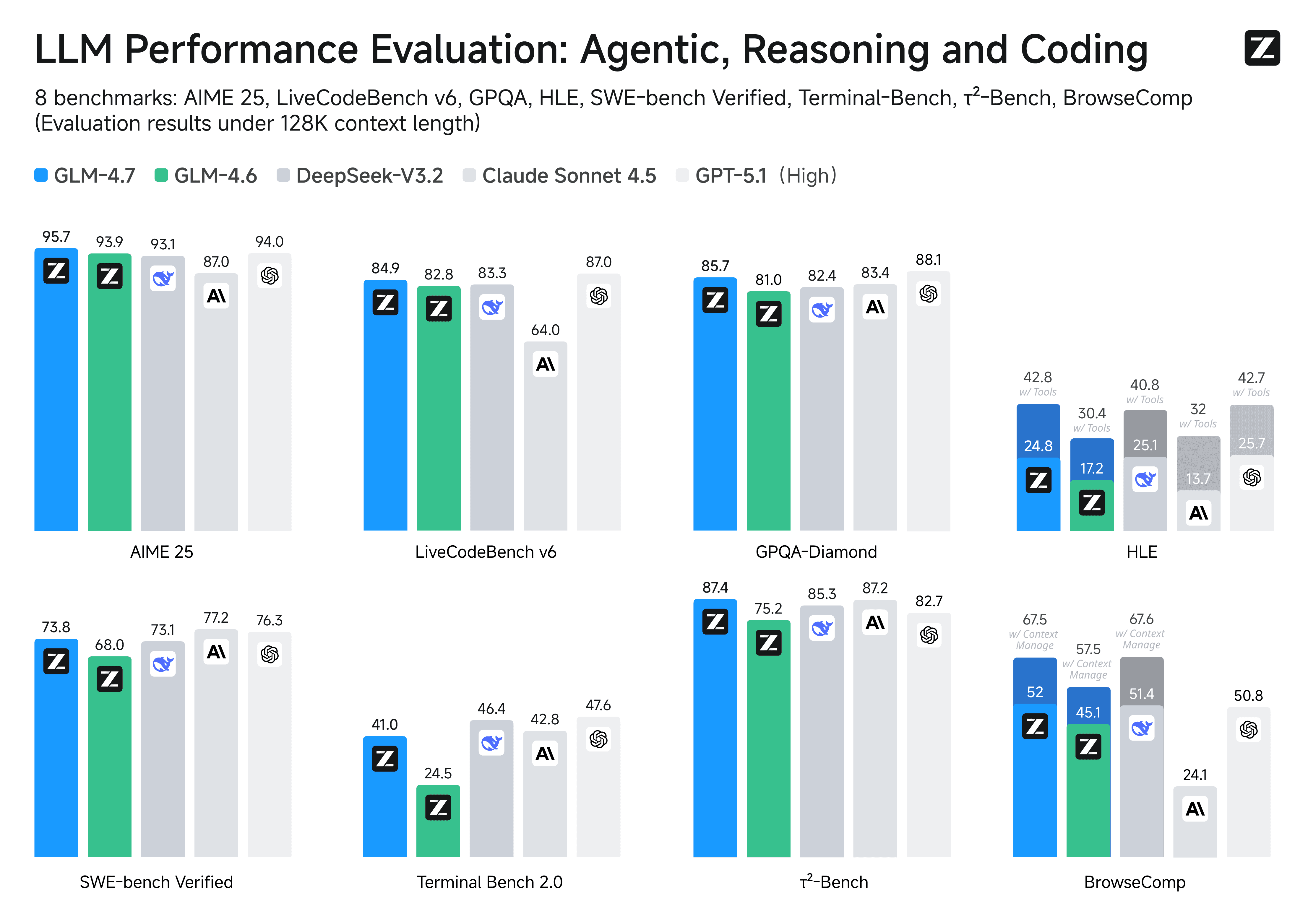
GLM-4.7은 다국어 에이전틱 코딩 및 터미널 기반 작업의 새로운 기준을 설정합니다. 이전 모델과 비교할 때, 개선 사항이 상당합니다:
73.8% (+5.8%) SWE-bench 검증
66.7% (+12.9%) SWE-bench 다국어
41% (+16.5%) 터미널 벤치 2.0
Model은 이제 "행동하기 전에 생각"을 지원하여 Claude Code, Kilo Code, Cline, Roo Code를 포함한 메인스트림 에이전트 프레임워크에서 복잡한 작업에 대해 보다 신뢰할 수 있는 성능을 제공합니다.
바이브 코딩
GLM-4.7은 UI 품질에 있어 큰 도약을 이룹니다. 더 깔끔하고 현대적인 웹 페이지를 생성하고 보다 정확한 레이아웃과 크기의 슬라이드를 생성합니다. 인터페이스를 프로토타이핑하거나 프레젠테이션을 만드는 경우에 Visual Output 품질이 눈에 띄게 향상됩니다.
고급 도구 사용
도구 활용이 크게 향상되었습니다. τ²-Bench 및 BrowseComp를 통한 웹 브라우징 작업과 같은 다단계 벤치마크에서 GLM-4.7은 Claude Sonnet 4.5 및 GPT-5.1 High를 능가하며 복잡하고 실제 작업流程에 대한 뛰어난 능력을 입증합니다.
복합 추론 능력
수학 및 추론 능력에서 큰 향상을 보이며, GLM-4.7은 GLM-4.6과 비교하여 HLE (인류의 마지막 시험) 벤치마크에서 42.8% (+12.4%)를 달성합니다. 또한 chat, 창의적 글쓰기, 롤플레이 시나리오와 같은 많은 다른 시나리오에서도 중요한 개선 사항을 볼 수 있습니다.
코딩, 창의성 또는 복합 추론 - 지금 시작하여 GLM-4.7이 워크플로에 어떤 이점을 제공하는지 확인하세요.
즉시 시작하세요
탐색: SiliconFlow Playground에서 GLM-4.7을 시도하세요.
통합: OpenAI/Anthropic-호환 API를 사용하세요. SiliconFlow API 문서에서 전체 API 사양을 탐색하세요.
