目录

总结: Qwen3-VL-8B — Qwen3-VL 家族的最新成员 — 现已在 SiliconFlow 上线。这个紧凑的视觉语言模型在 Instruct 和 Thinking 两个版本中提供了全面的 Multimodal 推理,同时大大降低了 VRAM 消耗。尽管拥有 8B 参数规模,它继承了旗舰模型 Qwen3-VL-235B 的全部能力 — 从高级 Text 生成到 空间和 Video 理解 — 超越了像 Gemini 2.5 Flash Lite 和 GPT-5 Nano 这样的更大模型。证明了效率与性能可以兼得,Qwen3-VL-8B 现已通过 SiliconFlow 的生产就绪 API 提供。
扩展 Qwen3-VL 生态系统,SiliconFlow 欣然介绍**Qwen3-VL-8B 系列 至我们的 模型目录** — 一种紧凑却强大的 Dense 视觉语言模型,重新定义了参数规模与 Multimodal 能力之间的平衡。提供 Instruct 和 Thinking 两个版本,它继承了旗舰机型的 全部能力,包括Qwen3-VL-235B-A22B-Instruct 和Qwen3-VL-235B-A22B-Thinking,包括 卓越的 Text 理解和生成、更深的视觉感知和推理、延长的上下文长度、增强的空间和 Video 动态理解以及更强的代理能力。
通过 SiliconFlow 的 Qwen3-VL-8B API,您可以期待:
经济实惠的定价:
Qwen3-VL-8B-Instruct:$0.18/M tokens (Input) 和 $0.68/M tokens (Output)
Qwen3-VL-8B-Thinking:$0.18/M tokens (Input) 和 $2.00/M tokens (Output)
262K 上下文窗口:支持 Text, Image 和 Video 的长形式 Multimodal 理解。
无缝集成:即时使用 SiliconFlow 的 OpenAI**/Anthropic 兼容 API**,或集成到您现有的工作流程中。
为什么Qwen3-VL-8B 重要
基于 Qwen3-VL 家族的基础,8B 变体引入了一套综合的增强功能,专为现实应用设计:
视觉代理能力:操作 PC/移动 GUI — 识别元素,理解功能,调用工具,并自主完成任务。
高级空间感知:判断物体位置、视点和遮挡;提供更强的 2D 定位并启用 3D 定位用于空间推理和体现 AI。
视觉编码提升:从 Image 和 Video 生成 Draw.io/HTML/CSS/JS。
长上下文和 Video 理解:本地 256K 上下文(可扩展至 1M),处理图书和小时长 Video,具有完整回忆和秒级索引。
增强的 Multimodal 推理:在 STEM/数学中表现出色,提供因果分析和逻辑、基于证据的答案。
扩展 OCR:支持 32 种语言(从 19 种提高),在低光、模糊和倾斜条件下增强鲁棒性,改进对稀有或古老字符和技术术语的处理,并改善长文档结构解析。
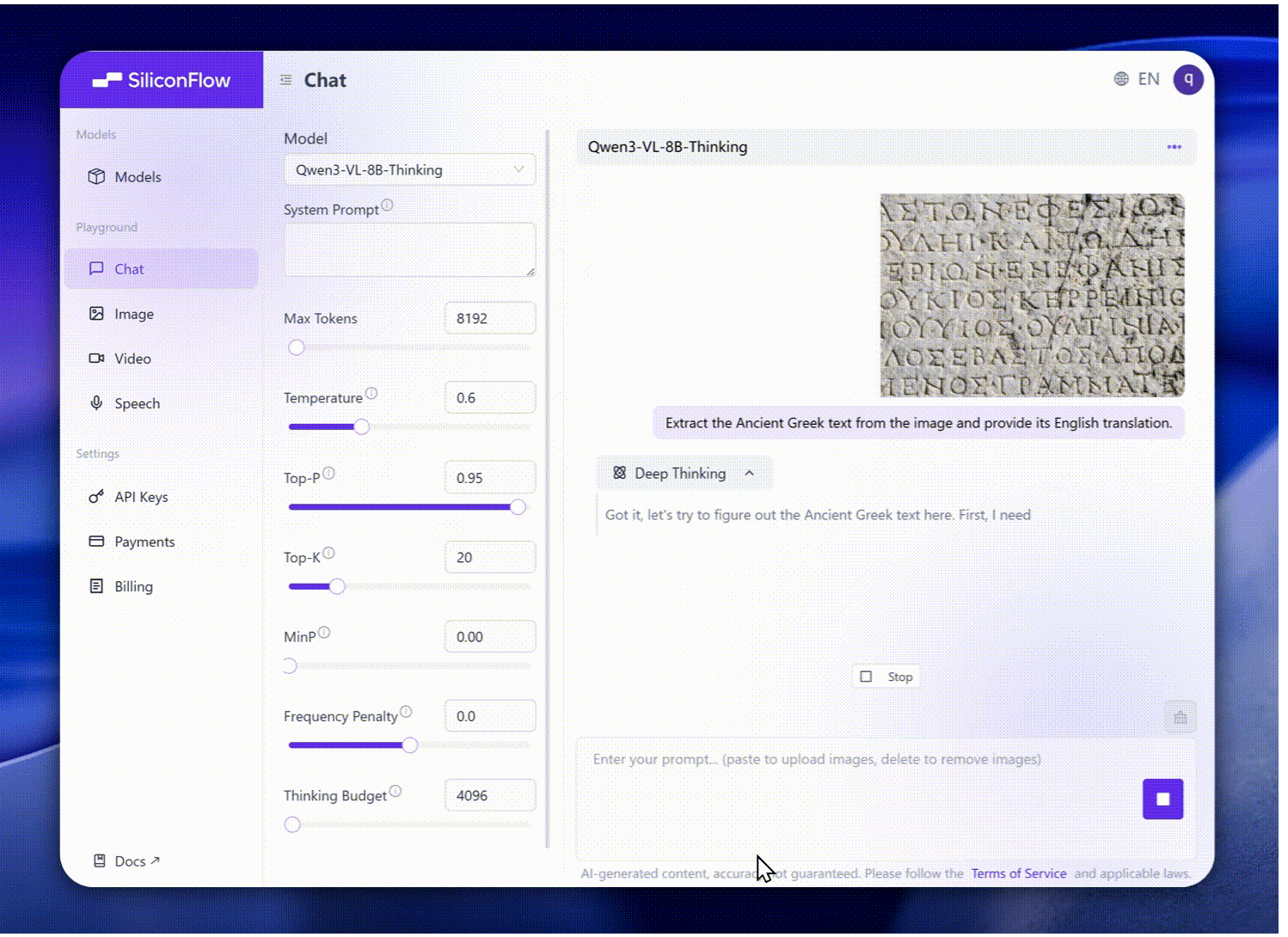
升级的视觉识别:更广泛、更高质量的预训练支持全面识别——名人、动漫、产品、地标、动植物等。
Text 理解媲美纯 LLMs:无损、统一的 Text-Vision 融合理解。
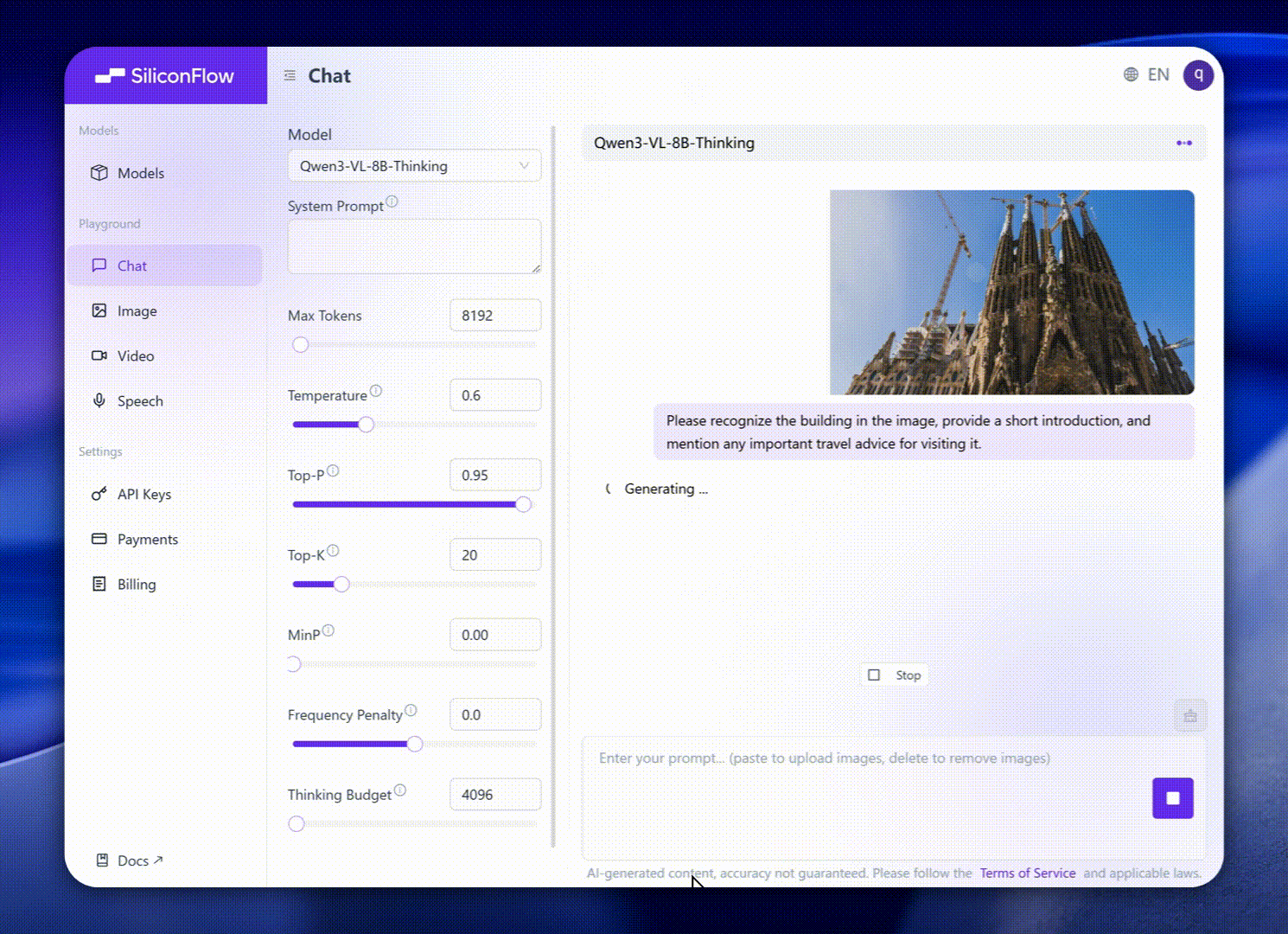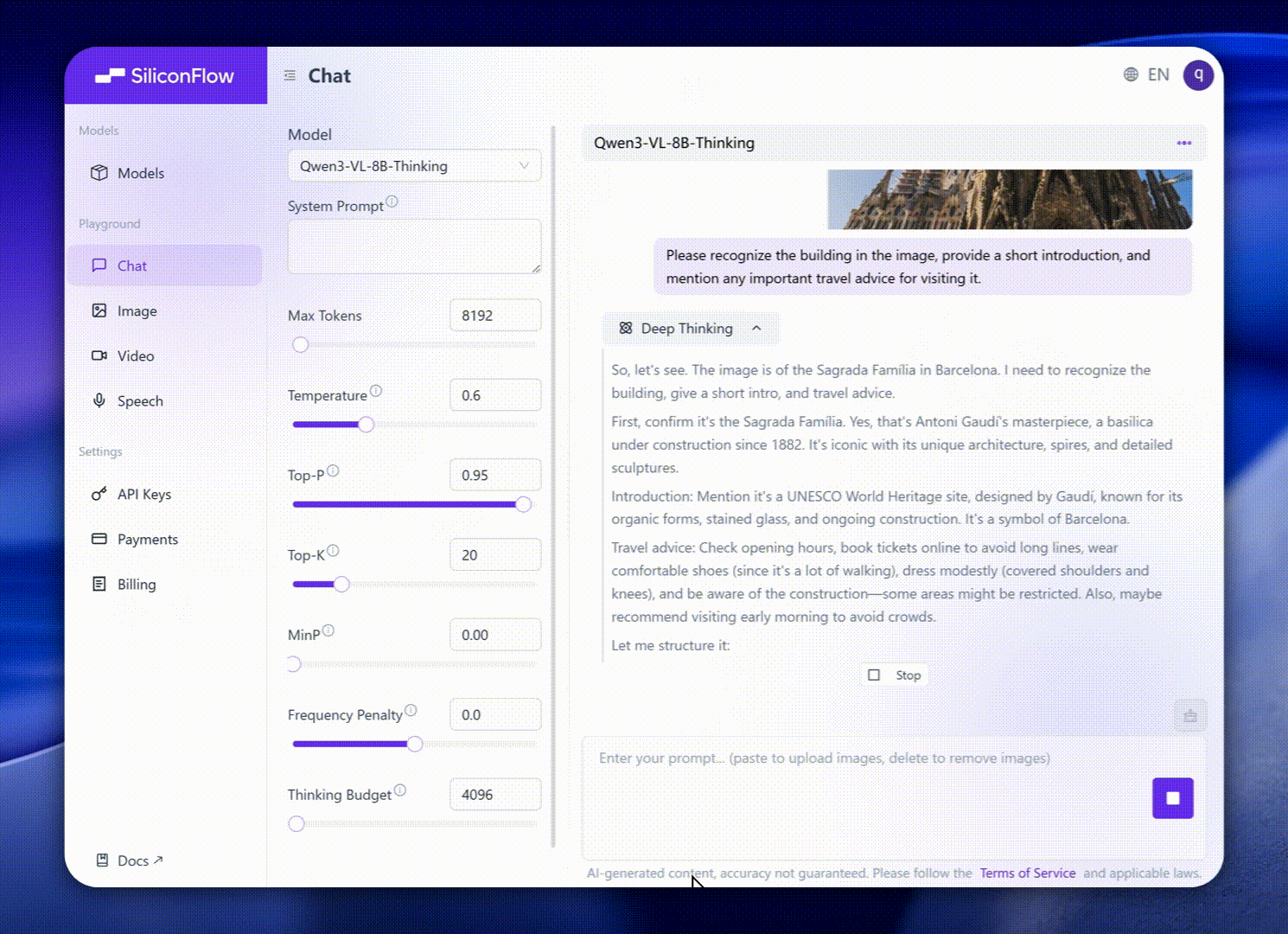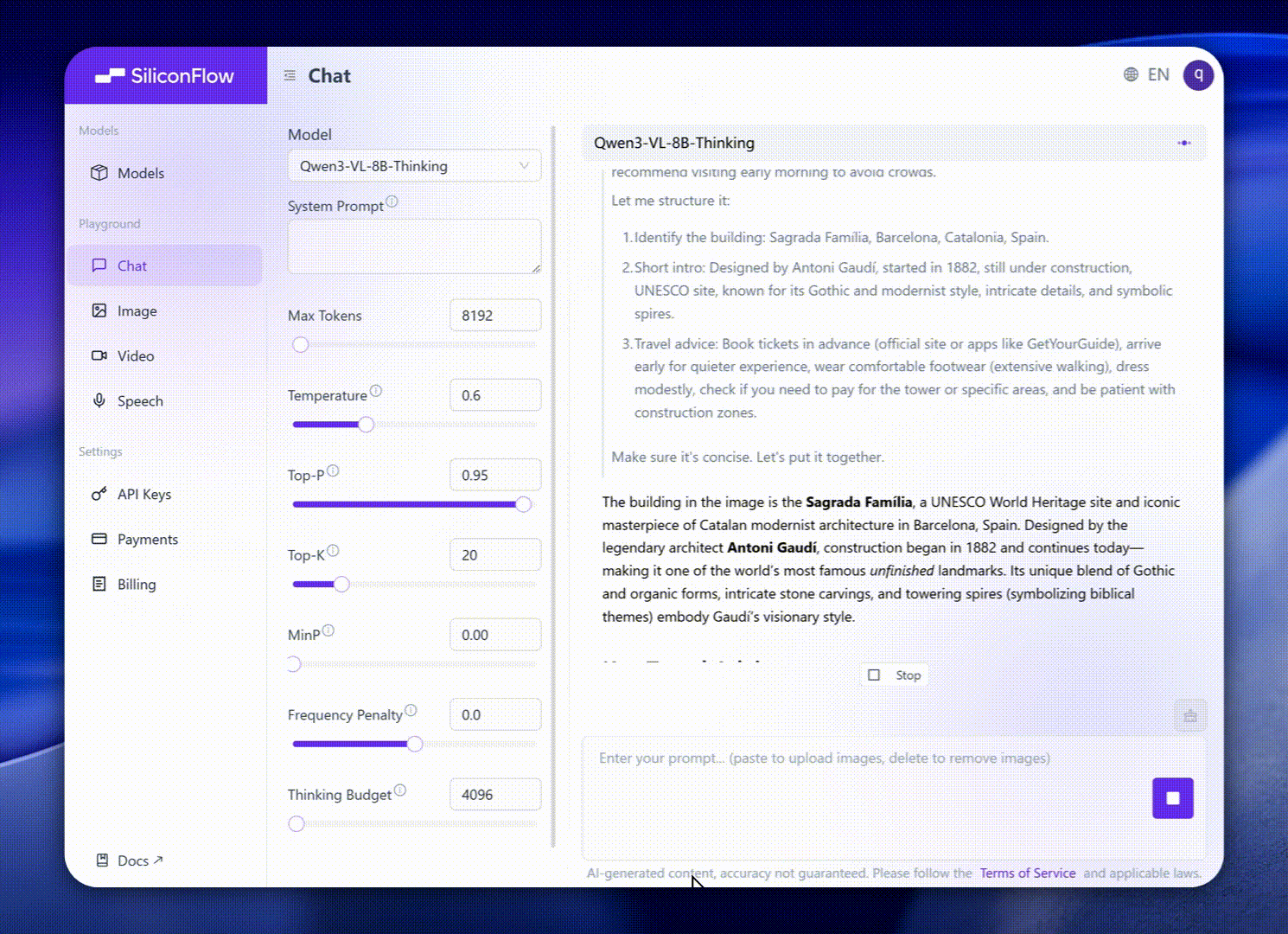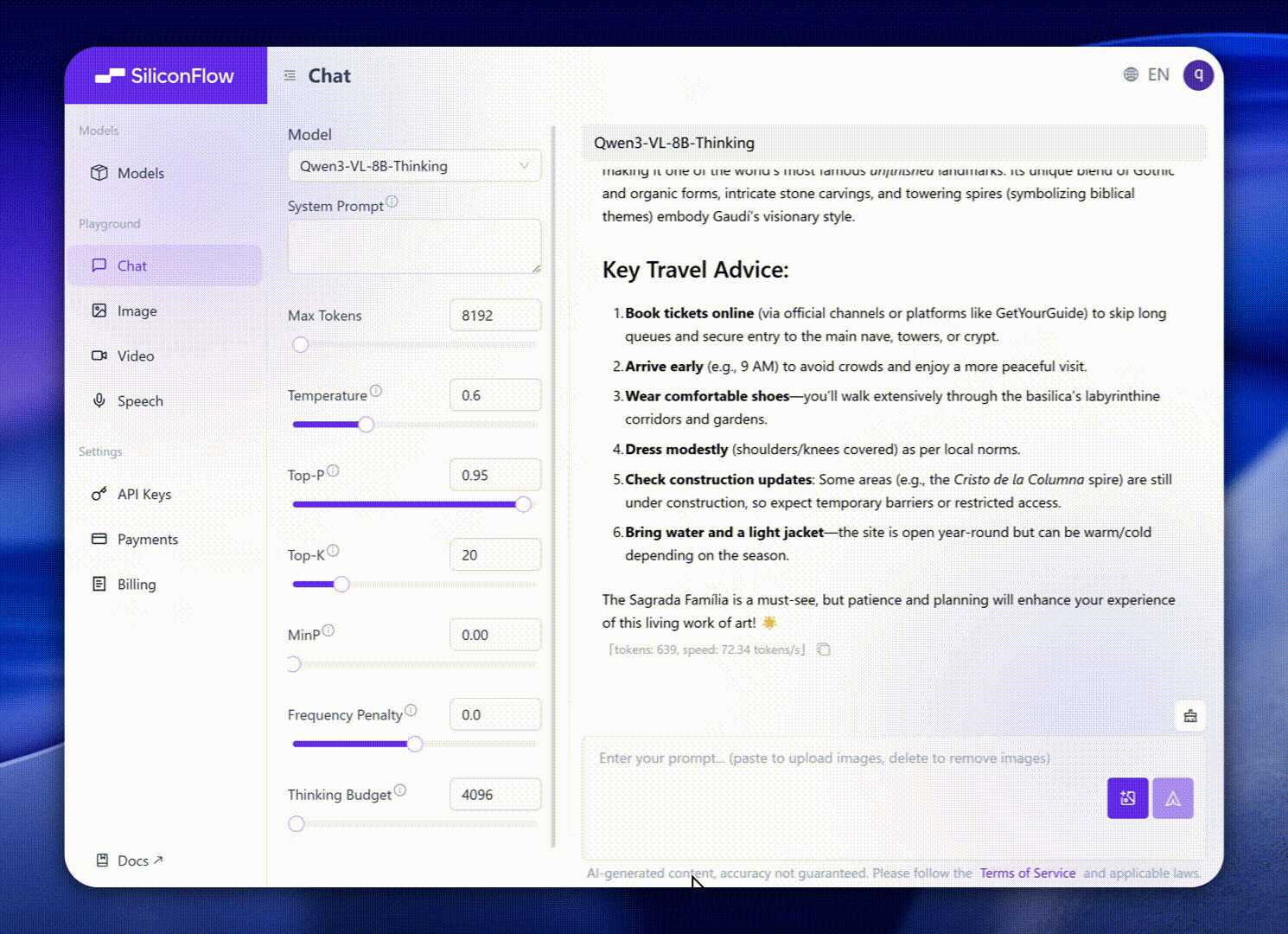
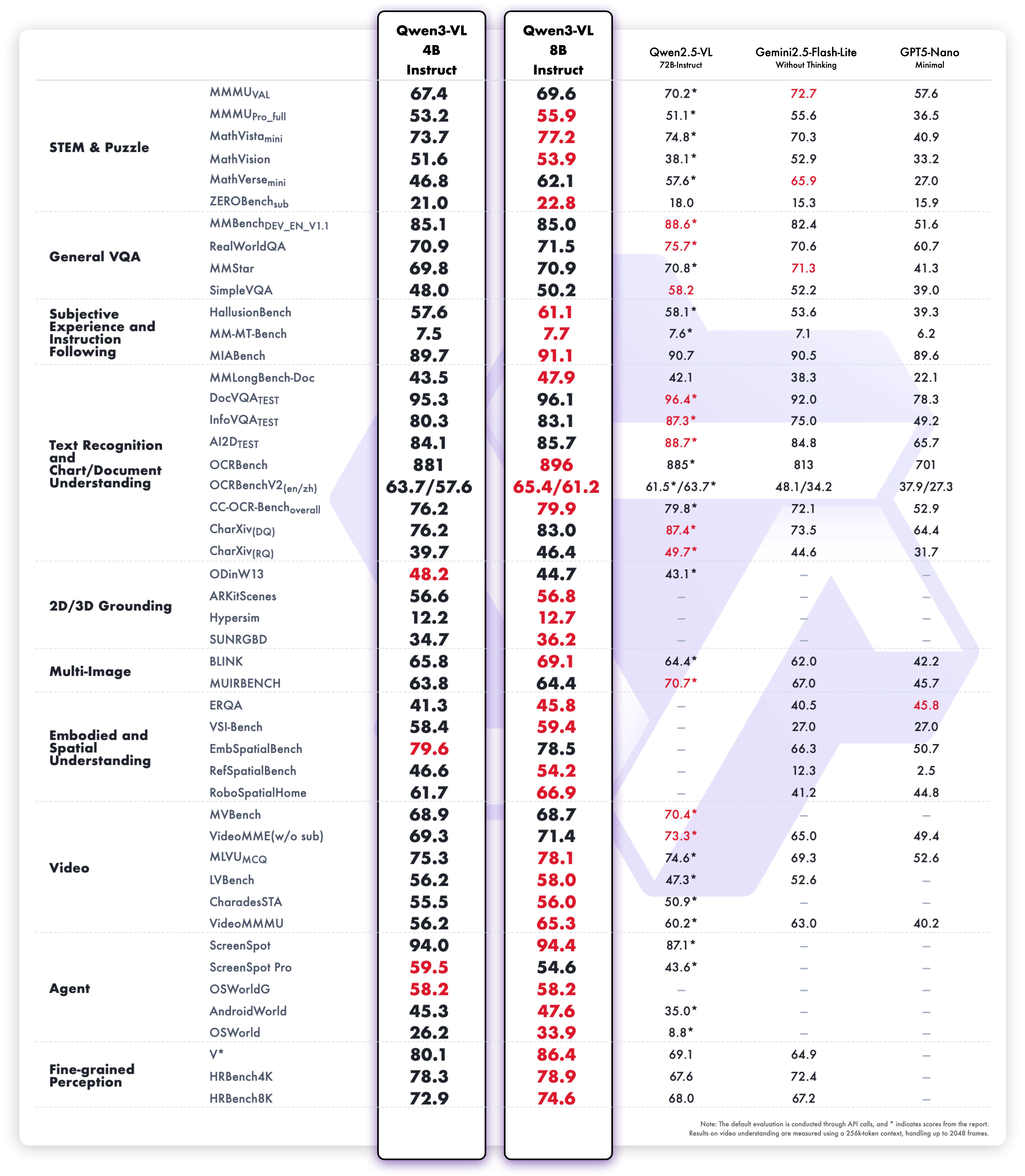
这些增强功能转化为卓越的现实世界基准表现。Qwen3-VL-8B 在公开基准中表现出杰出的表现,涵盖STEM、VQA、OCR、Video 理解和基于代理的任务 — 超过 Gemini 2.5 Flash Lite 和 **GPT-5 Nano,甚至可以媲美更大的Qwen2.5-VL-72B**。
值得注意的是,它在空间推理性能上表现出令人印象深刻的表现,为推进强大的智能应用奠定了坚实的基础。
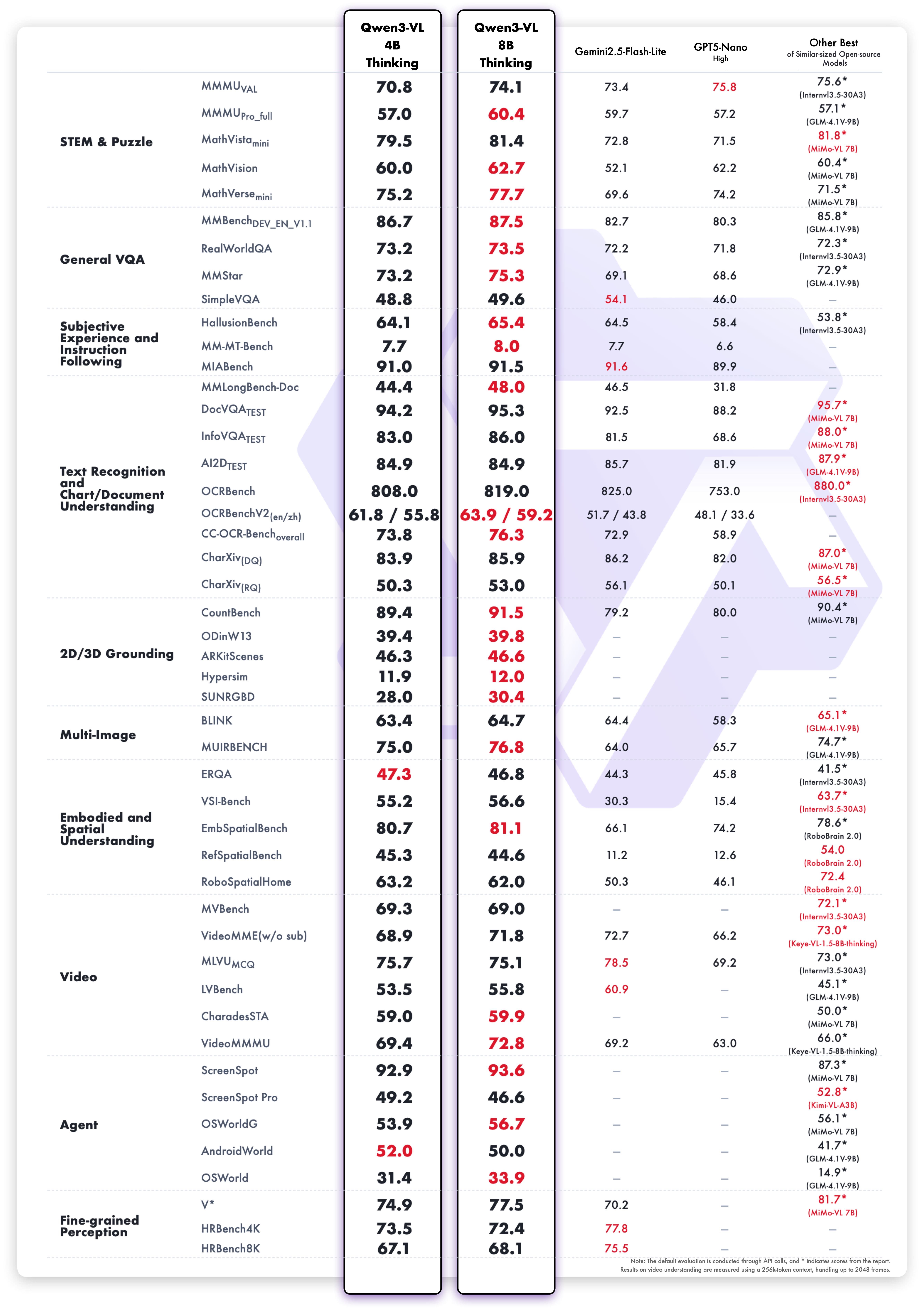
此外,较小的 Multimodal 模型总是面临基本的权衡:提高视觉能力往往会影响 Text 理解,反之亦然。这种“跷跷板效应”长期以来一直是创建紧凑而强大的视觉语言模型的障碍。Qwen3-VL-8B 通过视觉精度和 Text 强度平衡的共同优化克服了这种限制。
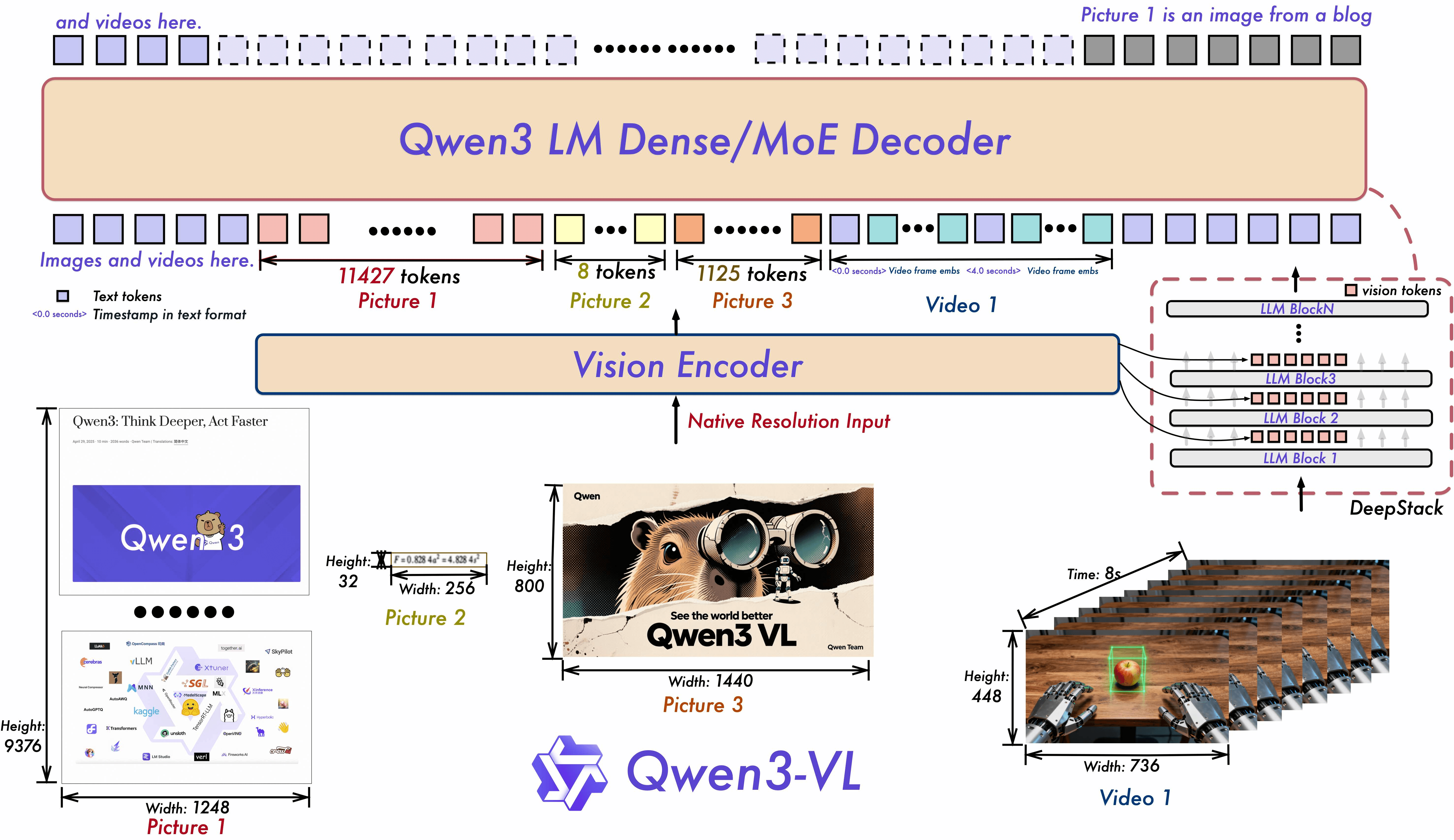
通过架构创新和技术优化,该模型显著增强了 Multimodal 感知,同时保持了基准测试中展示的强大 Text 理解能力。
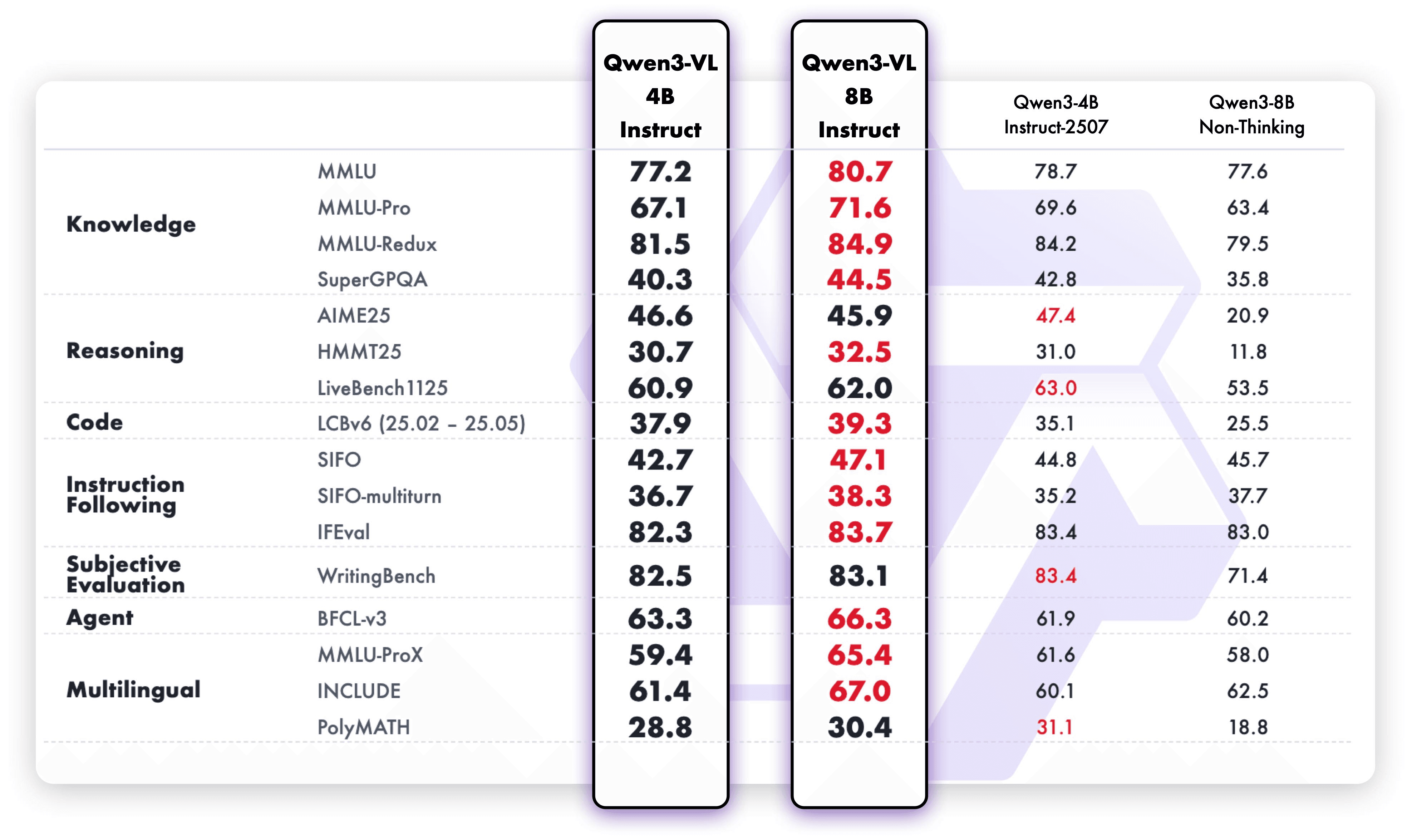
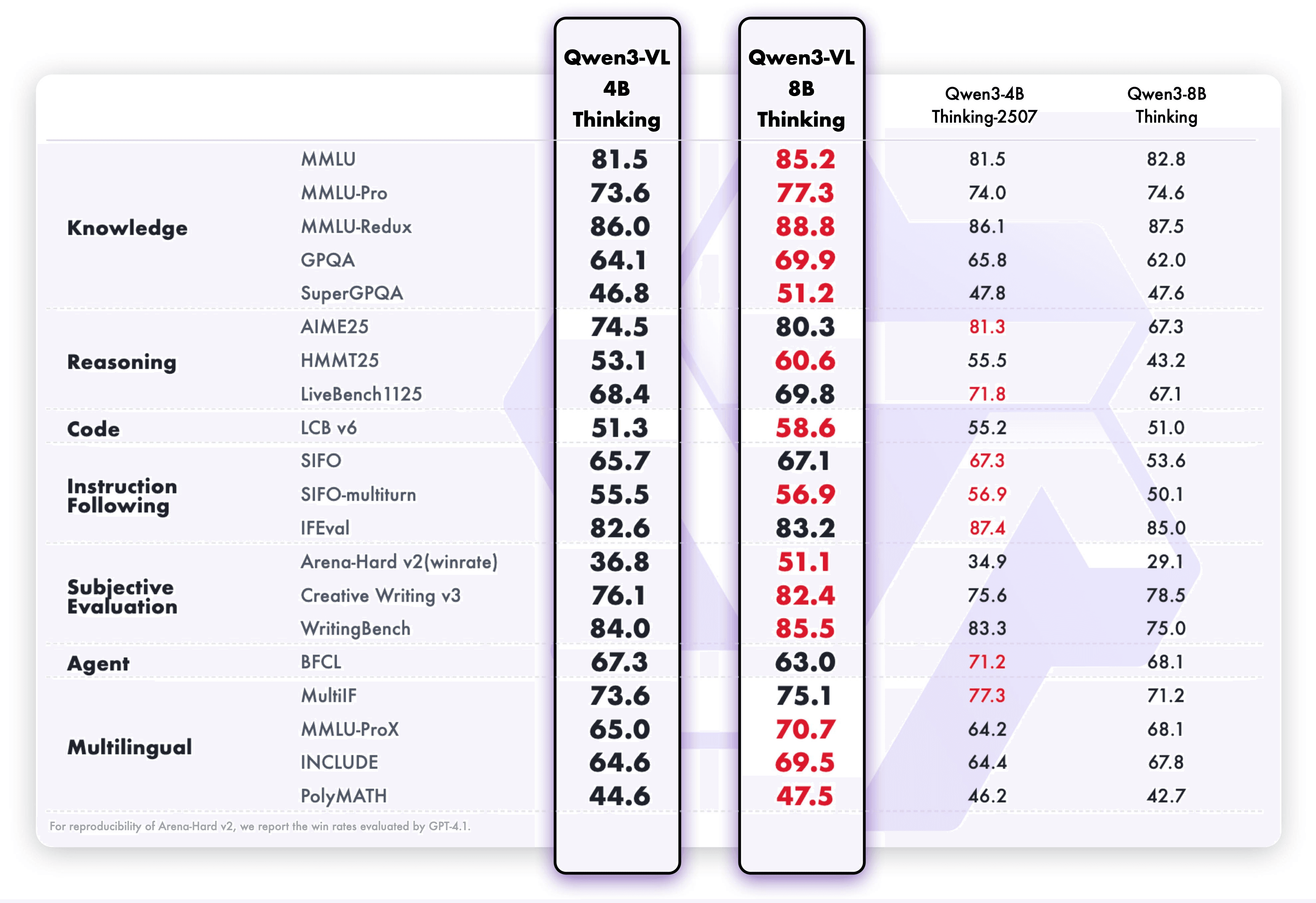
结果?更多能力现在适合更小的模型 — 从识别到推理,从 Text 到 Image 和 Video。
现实应用场景
凭借其紧凑的 8B 密集架构和全谱 Multimodal 能力,Qwen3-VL-8B 将先进的视觉智能带入现实工作流程:
视觉推理和 STEM 任务:解释图表、图表和数学公式,以清楚的逻辑解释解决几何、物理或化学问题。非常适合教育、研究和 AI 辅导系统。
文档理解和 OCR:从扫描的文件、收据或技术论文中提取和总结信息,支持 32 种语言。支持复杂的布局解析、表格识别和结构化数据转换。
动态视觉和代理交互:分析 Video 帧,识别 GUI 元素,并在 PC 或移动接口中模拟交互——实现能够“看、推理和行动”的自主代理。
Multimodal 创造:将视觉 Input 转换为创意或技术 Output,例如从截图生成 HTML/CSS/JS 布局或从 Image 和短片中撰写描述性叙述。
无论您是在构建智能助理、文档分析系统或创意 Multimodal 工具,Qwen3-VL-8B 通过 SiliconFlow 的 API 服务将旗舰级 Multimodal 智能带入您的工作流程。
立即开始
探索:在 Qwen3-VL-8B 系列中试用 SiliconFlow 模型广场。
集成:使用我们的 OpenAI 兼容 API。在 SiliconFlow API 文档中探索完整的 API 规范。
今天就开始使用 Qwen3-VL-8B 构建,通过 SiliconFlow 的生产就绪 API 体验旗舰级 Multimodal 智能!
