
目录

## 介绍
在不断发展的数字技术领域,视频内容已成为沟通、娱乐和教育的基石。为了认识到这一领域的巨大潜力和创新需求,[腾讯](https://www.tencentcloud.com/products/ivh) 作为全球技术和数字解决方案的领导者,骄傲地推出了 [Hunyuan Video](https://hunyuanvideoai.com/)。这个尖端的开源平台旨在革新我们创造、互动和传播视频内容的方式。在这篇博客中,我们将深入探讨 Hunyuan Video 的功能、优点以及其转型影响。
## Hunyuan Video 的关键功能
### 1. AI 驱动的视频编辑
* **智能编辑工具:**Hunyuan Video 利用先进的 AI 算法为视频内容编辑提供智能建议。这些工具可以分析视频素材,推荐最佳剪切点,确保最终产品流畅且引人入胜。
* **建议过渡:**AI 可以建议场景之间的视觉上吸引人的过渡,增强视频的整体流动性和美感。其中包括淡入、淡出、溶解和其他可以使视频更具动感的效果。
### 2. 云渲染与部署
* **快速渲染:**Hunyuan Video 使用基于云的渲染技术快速处理和完成视频内容。这消除了对强大本地硬件的需求,并允许更快的周转时间。
* **跨平台部署:**该工具支持视频在多个平台上无缝部署,包括社交媒体、流媒体服务和网站。这确保了无论观众选择在哪里观看,您的内容都可以轻松访问。
### 3. 实时互动流媒体
* **低延迟流媒体:**Hunyuan Video 提供低延迟的实时流媒体,确保直播活动流畅不间断。这对维持观众的参与和互动至关重要。
* **多样化的使用场景:**实时互动流媒体非常适合各种应用,包括虚拟会议、现场音乐会、教育课程和网络研讨会。它为内容创作者提供了一个灵活且动态的平台,以实时与观众互动。
## 引擎揭秘:揭示 Hunyuan Video 的架构
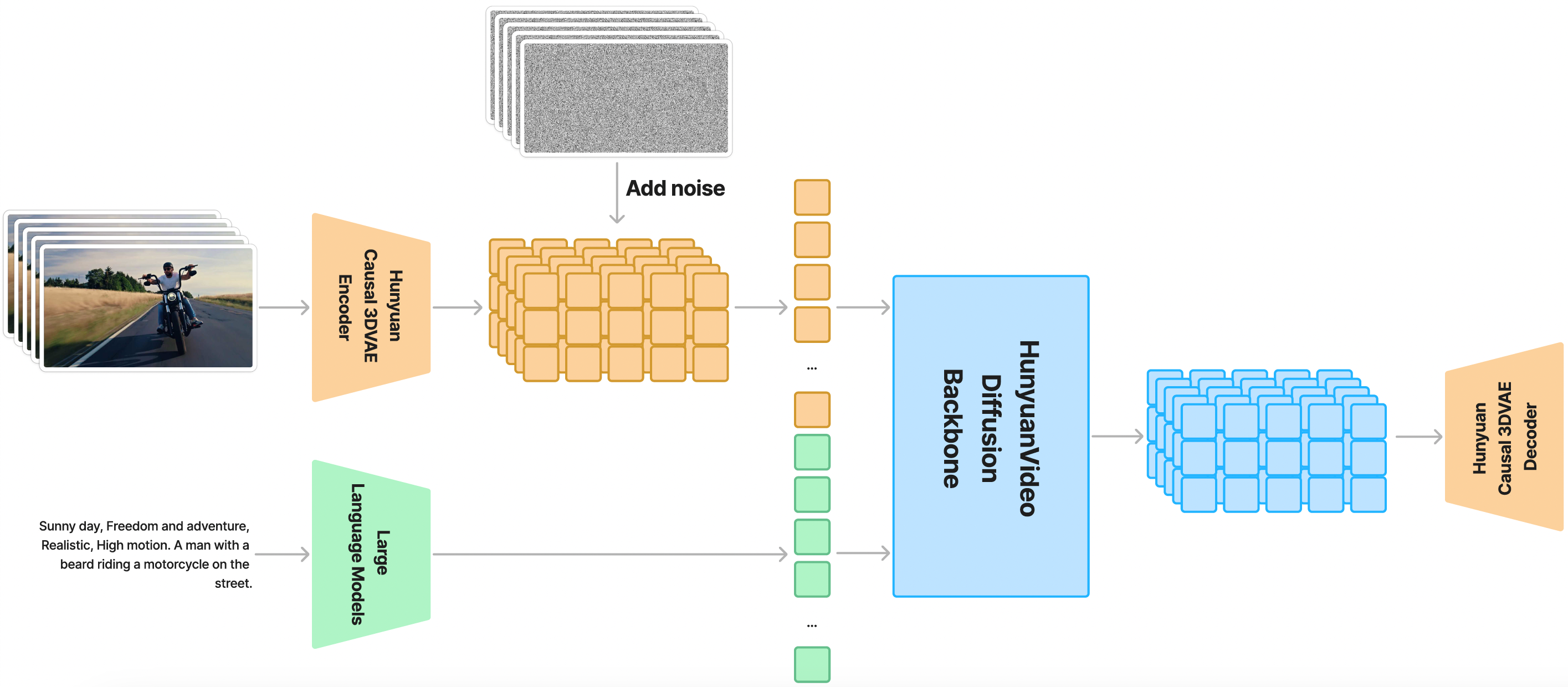
从该图中,我们可以了解到 Hunyuan Video 是通过 Causal 3D VAE 实现的空间时间压缩潜在空间进行训练的。使用大型语言模型处理 Text 作为条件输入。以上图中的示例以高斯噪声和条件输入为输入,生成一个输出潜在。这一潜在输出随后会被解码为图像或视频,使用 3D VAE 解码器。
### 1. 统一的 Image 和 Video 生成架构
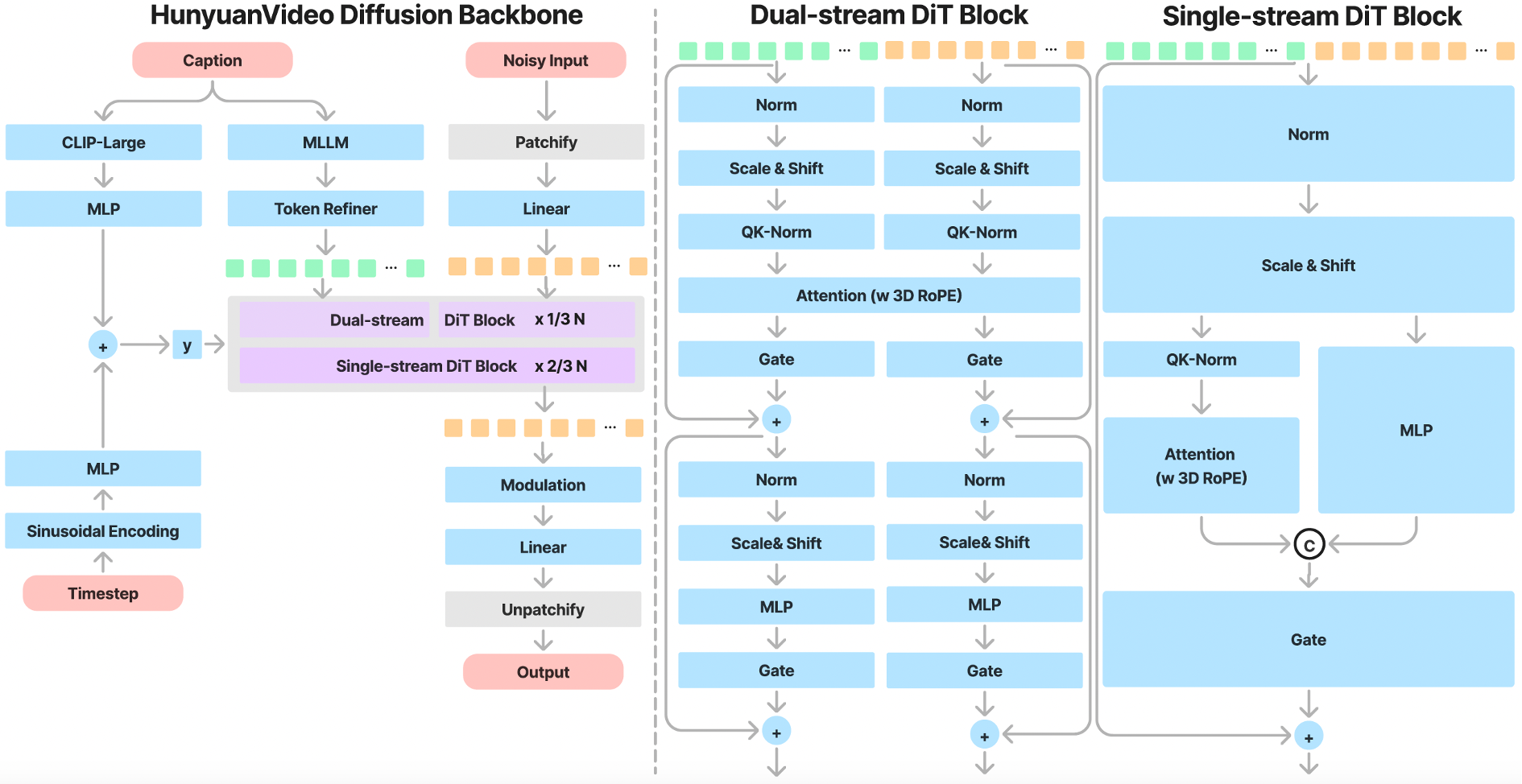
* **带全注意机制的 Transformer 设计:**实现统一的 Image 和 Video 生成。
* **双流到单流混合模型:*** **双流阶段:** Video 和 Text tokens 独立通过多个 Transformer 块进行处理。
* **单流阶段:**拼接的 tokens 经过后续的 Transformer 块,进行有效的 Multimodal 融合,捕捉视觉和语义信息之间的复杂交互。
### 2. MLLM 文本编码器:增强 Multimodal 对齐
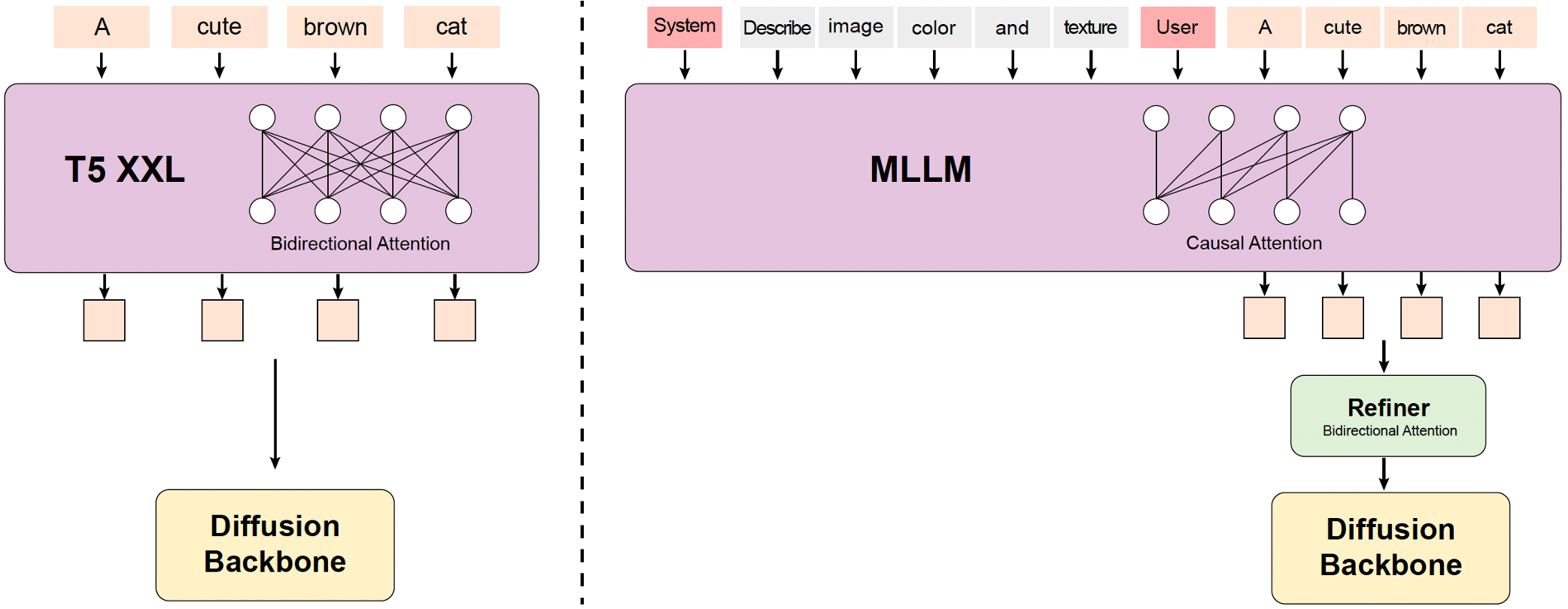
* **仅解码器结构:**与传统编码器(例如,CLIP,T5-XXL)相比,提供更好的图文对齐和出色的图像细节描述。
* **零次学习能力:**遵循系统指令,将其并加入用户提示中,增强对关键信息的关注。
* **双向 Token 精炼器:**用于增强文本特征,在扩散模型中提供更好的指导。
### 3. 3D VAE 以实现高效压缩

* **CausalConv3D:**训练一个 3D VAE 将视频和 Image 压缩成紧凑的潜在空间。
* **压缩比率:**视频长度 (4x)、空间 (8x) 和通道 (16x),
## 深度探索:释放 Hunyuan 模型的力量
该 YouTuber 首先介绍了 Hunyuan 模型,拥有 130 亿个参数,在生成高分辨率视频方面超过了 Runway Gen 3 和 Luma 1.6 等竞争对手。这种庞大的参数数量使模型能够生成令人惊叹的细致逼真的内容,使其成为内容创作者的优秀选择。此外,借助 Hunyuan 的先进 Multimodal 特性进行文本到视频的生成,可以创造出更加沉浸和细致的内容。通过结合文本、Image 和其他数据类型,Hunyuan 能够生成不仅视觉上令人惊叹而且在上下文和细节上都丰富的视频,提供一个新的创意和深度层次。
虽然该模型需要大量的视频内存(45-60 GB),但这位 YouTuber 提供了适用于兼容 GPU 的详细安装指南,确保具备必要硬件的用户可以充分利用其功能。这使得非技术人员的创作者也可以更轻松地进行设置并开始使用 Hunyuan。此外,上传短片进行分辨率实验的能力为创意和视频增强开辟了新的途径,允许 YouTubers 推动他们内容的界限。另外,Hunyuan 模型通过各种演示展示了其多功能性和潜力。从夜间驾驶场景的生动细节到该 YouTuber 提供的文本提示的奇妙探索,这些示例都突显了该模型处理各种内容类型和风格的能力。它的多功能性使其成为任何希望创建高质量、引人入胜的视频的 YouTuber 的宝贵工具,能够吸引观众。
## 基准性能:引领先进的文本到视频合成
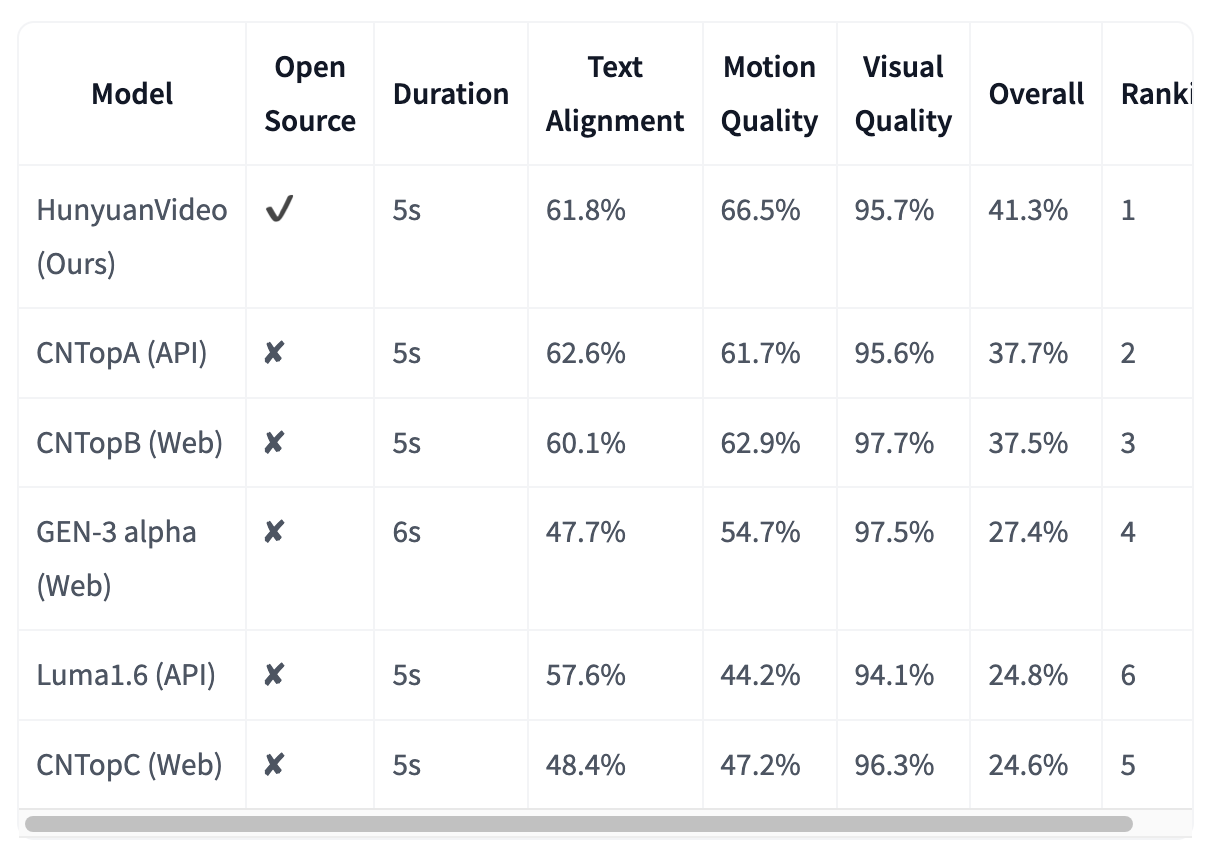
HunyuanVideo 在这篇[论文](https://arxiv.org/abs/2412.03603)中对五个其他领先的视频生成模型进行了评估。评估使用 1,533 个文本提示来生成每个模型的视频。然后将这些视频根据三个标准进行评估:文本对齐、运动质量和视觉质量。HunyuanVideo 在所有其他模型中表现优异,尤其在运动质量上表现突出。它在生成具有逼真和流畅运动的视频方面展示了显著优势。虽然所有模型在文本对齐方面表现都很出色,但 HunyuanVideo 还生成了高质量的视觉效果。
## 在此测试:
Huggingface: [https://huggingface.co/tencent/HunyuanVideo#-open-source-plan](https://huggingface.co/tencent/HunyuanVideo#-open-source-plan)
Hunyuan Video 官方网站: [https://hunyuanvideoai.com/dashboard](https://hunyuanvideoai.com/dashboard)
## 结论
当我们完成对腾讯 Hunyuan Video 的深入探索后,很明显,这一革命性平台将重塑视频技术的界限。凭借其最先进的架构,具有统一的 Image 和 Video 生成模型,Hunyuan Video 不仅是一个工具,而且是通向前所未有创意可能性的入口。随着我们进入这个视频技术的新纪元,Hunyuan Video 作为创新的灯塔,邀请创作者、企业和爱好者去探索、实验并推动可能的界限。无论您是希望提升内容,优化工作流程,还是今天就体验视频的未来,Hunyuan Video 肯定是您的理想选择!
