目次

要約: Qwen3-VL — Qwenシリーズで最も強力なビジョン言語モデル — がSiliconFlowで利用可能になりました。このリリースは画期的なアップグレードを提供します:優れたテキスト理解と生成、マルチモーダル推論、先進の空間およびビデオ認識、262Kコンテキストウィンドウ、32言語に対応したOCR、より強力なエージェントの相互作用。密集およびMoEのアーキテクチャによって235Bパラメータまで対応し、Interleaved-MRoPEやDeepStackのような革新を採用し、マルチモーダルAIの新しい基準を設定します。
現在、InstructとThinkingの両方のバリアントがSiliconFlowで利用可能です。SiliconFlowのプロダクション対応APIで今すぐ構築を開始しましょう!
私たちは、Qwen3-VLシリーズがSiliconFlowでライブになったことを発表できることに興奮しています。次世代のビジョン言語モデルとして、世界をよりよく見て、理解し、応答するために構築されたQwen3-VLは、マルチモーダルAIを再定義する画期的な機能を提供します。これにより、精密なビデオ理解、32言語に対応したOCR拡張、レアキャラクターや歴史的なテキストの改善された取り扱い、262Kコンテキストウィンドウによる超長コンテンツ分析を可能にします。
SiliconFlowは今、InstructおよびThinkingエディションを提供しています。前者は効率的な実行に最適化され、後者はより深い推論に向けて強化されており、ユーザーはニーズに応じたモデルを選択する柔軟性を持っています。
SiliconFlowのQwen3-VL APIを通じて期待できること:
コスト効率の高い料金設定:
Qwen3-VL-30B-A3B-Instruct $0.29/M tokens (Input) および $1/M tokens (Output)
Qwen3-VL-30B-A3B-Thinking $0.29/M tokens (Input) および $1/M tokens (Output)
Qwen3-VL-235B-A22B-Instruct $0.3/M tokens (Input) および $1.5/M tokens (Output)
Qwen3-VL-235B-A22B-Thinking $0.45/M tokens (Input) および $3.5/M tokens (Output)
262Kコンテキストウィンドウ: 長い文書や多ターン会話のシームレスな処理を可能にします。
これらの組み合わせを通じて—30B対235B、Instruct対Thinking—SiliconFlowは開発者に効率、深さ、コスト間のバランスを選択する柔軟性をもたらし、あらゆる規模でのプロダクションに柔軟なマルチモーダルインテリジェンスをもたらします。
なぜQwen3-VLが重要なのか
ほとんどのビジョン言語モデルは、広範な機能か深い推論のトレードオフに直面しますが、両方を兼ね備えていることは少ないです。一般モデルは複雑な論理で苦労し、専門モデルは汎用性に欠けます。見ることは理解することではなく、理解することが問題解決を保証するものではありません。
Qwen3-VLは二重エディションアプローチでこれに対応します:
Instruct: 信頼性のあるパフォーマンスを持ち、広範な日常のビジョン言語タスクに最適化されています。
Thinking: STEMや数学の複雑な問題解決に向けた高度な推論能力で強化されています。
これにより、3つの主要な領域での能力の開放が可能となります:
1. エージェンティック
ビジュアルエージェント: AIにアプリやウェブサイトをナビゲートさせましょう!UI要素を認識し、その機能を理解し、ステップごとのタスクを自律的に実行します。また、OS Worldなどのベンチマークでトップのグローバルパフォーマンスを達成し、ツールを使用することで微細な認識タスクのパフォーマンスを大幅に向上させます。
より優れた空間理解: 絶対座標から相対座標までの2Dグラウンディング。オブジェクトの位置、視点の変化、遮蔽関係を判断できます。3Dグラウンディングもサポートし、複雑な空間推論や具現化AIアプリケーションの基盤を形成します。
設計からコードへ: スクリーンショットやビデオをアップロードし、プロダクション準備が整ったDraw.ioダイアグラム、HTML、CSS、またはJavaScriptを生成します。これにより「見たままが得られる」視覚プログラミングが現実となります。

2. 認識と理解
長いコンテキストと長いビデオ理解: すべてのモデルはネイティブに262Kコンテキストウィンドウをサポートしており、最大100万トークンまで拡張可能です。これにより、数百ページの技術文書、教科書全体、さらには数時間のビデオを入力でき、モデルはすべてを記憶し、正確に詳細を取り戻すことができます。
拡張されたOCR: 32言語のサポート、ぼやけた/傾いた/低光環境での画像での強固なパフォーマンス、レアキャラクター、古文書、および技術用語の改善された取り扱いに加え、長いドキュメントの構造解析の改善があります。
アップグレードされた視覚認識と認識: 事前トレーニングデータの品質と多様性を改善することで、モデルはより広範なオブジェクトを認識できるようになります。セレブリティ、アニメキャラクター、製品、ランドマークから動植物まで、日常生活と専門的な「何でも認識する」ニーズをカバーします。
3. 数学と言語
より強力なマルチモーダル推論(Thinkingバージョン): ThinkingモデルはSTEMや数学推論に特に最適化されています。複雑な主題の質問に直面した際、微細な詳細に注意を払い、問題をステップバイステップで分解し、原因と結果を分析し、論理的で証拠に基づく回答を提供します。MathVision、MMMU、MathVistaなどの推論ベンチマークで強みを発揮します。
優れたテキスト中心のパフォーマンス: Qwen3-VLはテキストと視覚モダリティの早期合同事前学習を採用し、言語能力を継続的に強化しています。テキストベースのタスクでのパフォーマンスはQwen3-235B-A22B-2507—フラッグシップ言語モデル—と匹敵し、次世代のビジョン言語モデルに向けた真の「テキスト基盤のマルチモーダルパワーハウス」を実現します。

ベンチマーク性能と技術アーキテクチャの更新
Qwen3-VLは広範なビジョン言語スキルを示すだけでなく、マルチモーダルおよび純粋なテキスト評価の分野で最先端の性能を提供します。
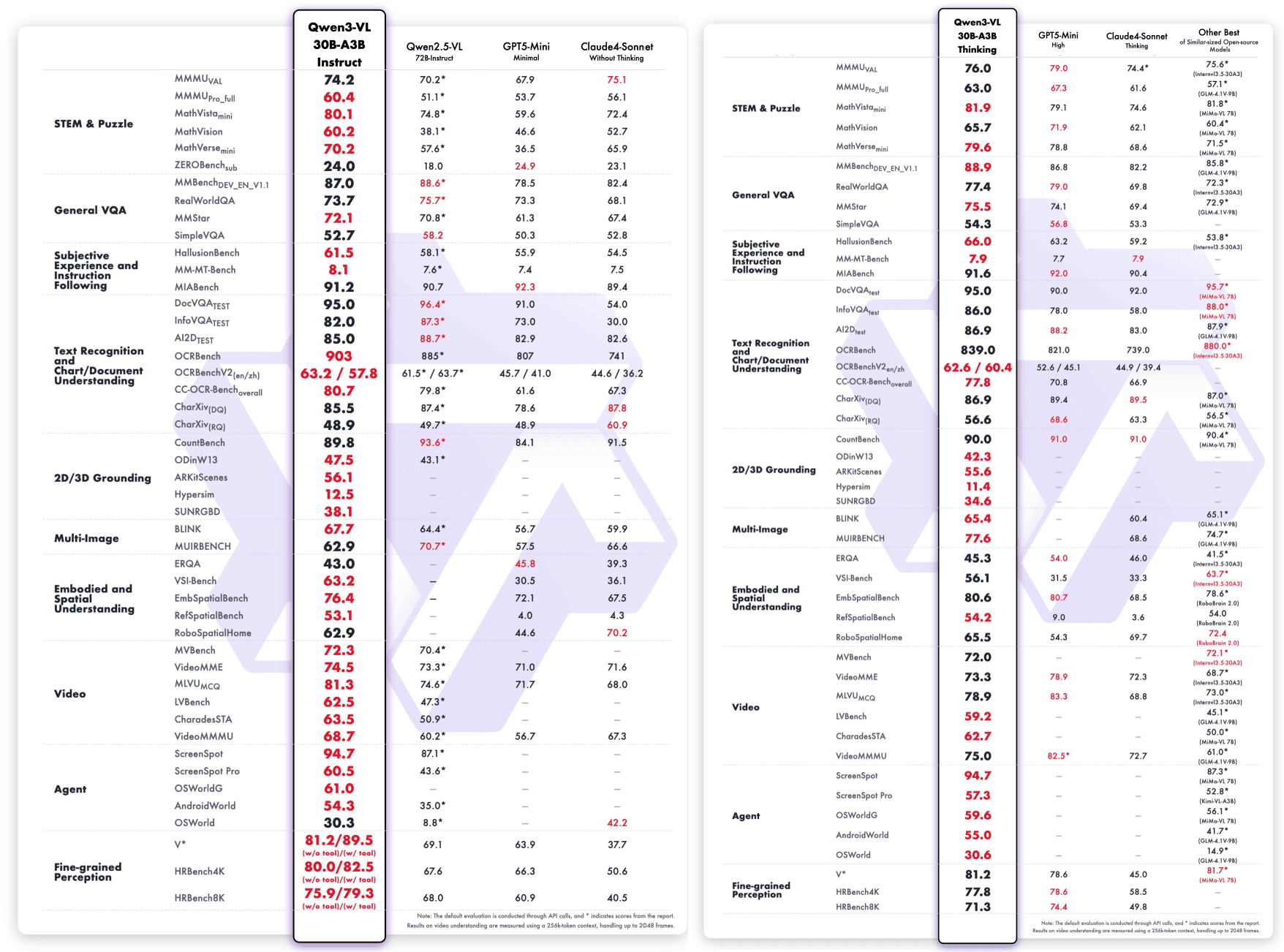
Qwen3-VL-235B-A22B-Instruct & Qwen3-VL-235B-A22B-Thinking:
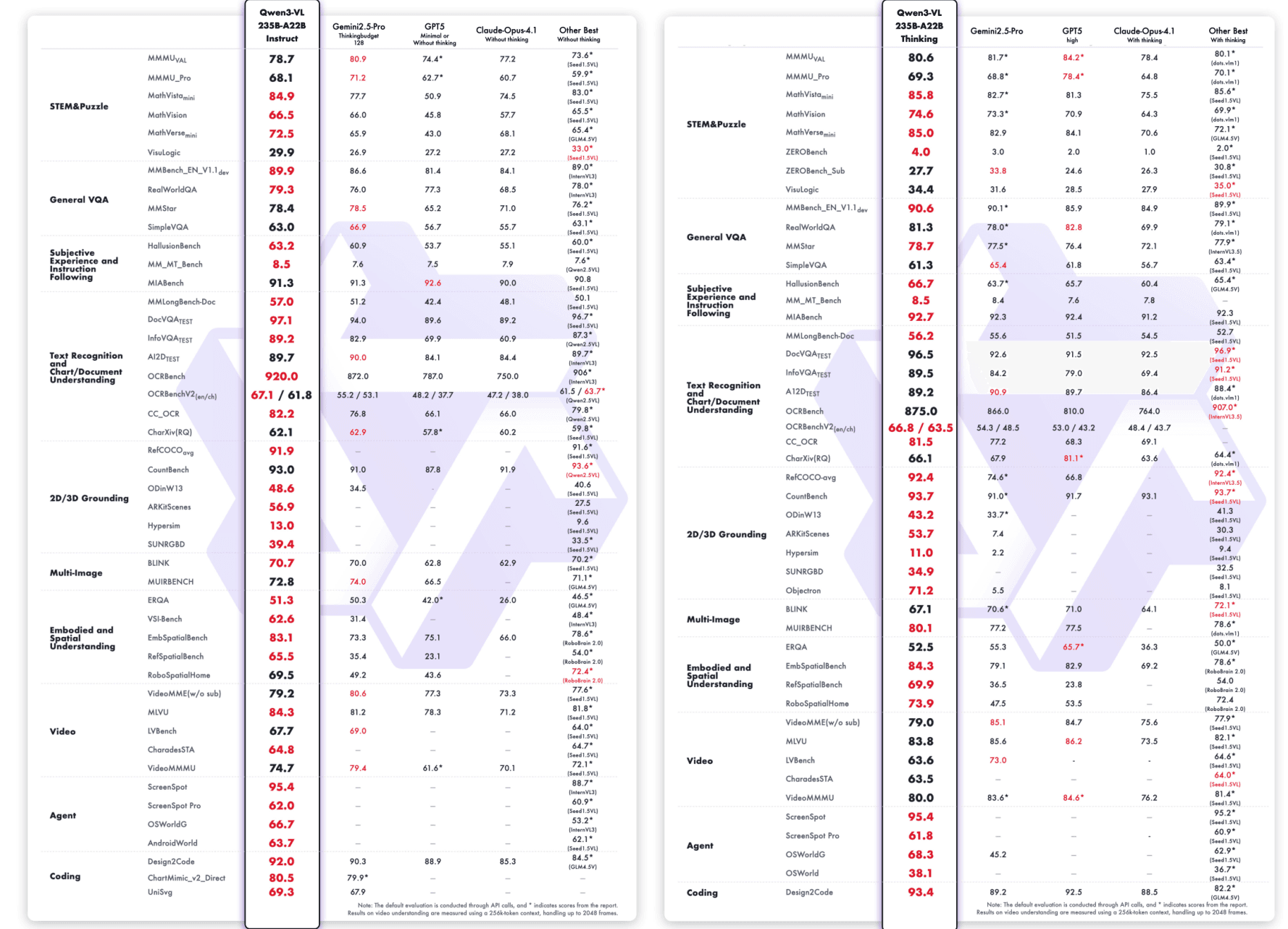
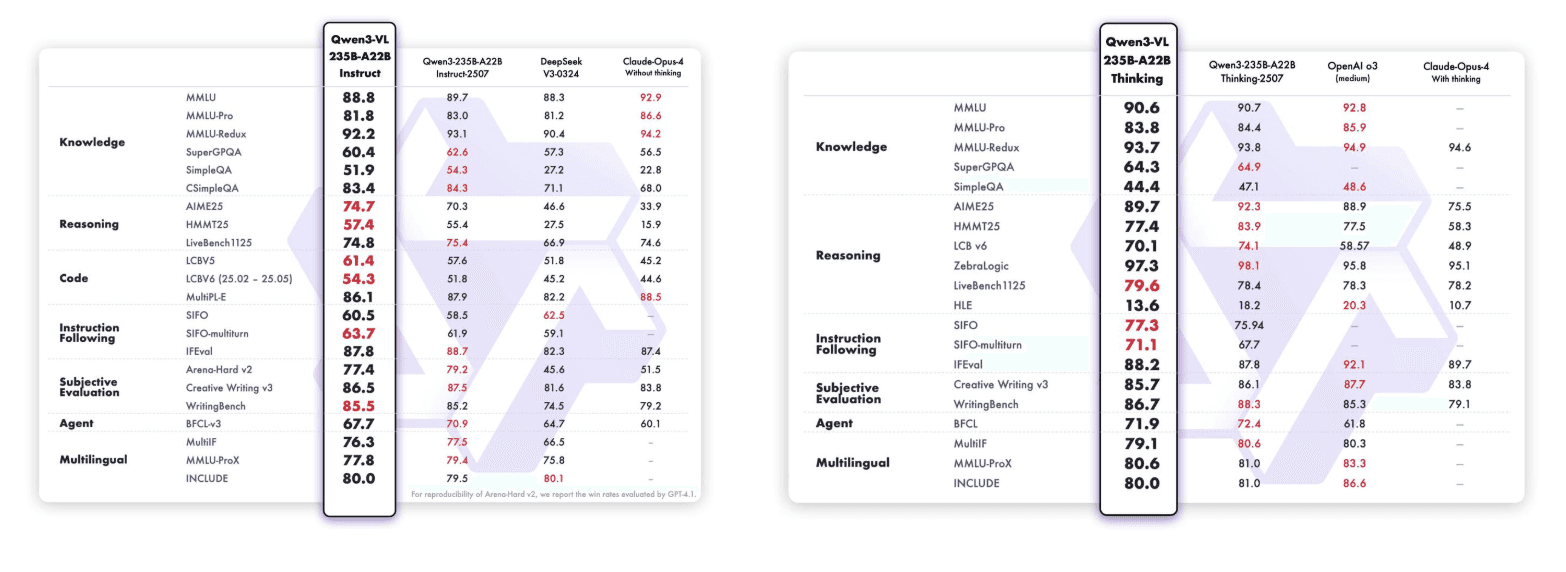
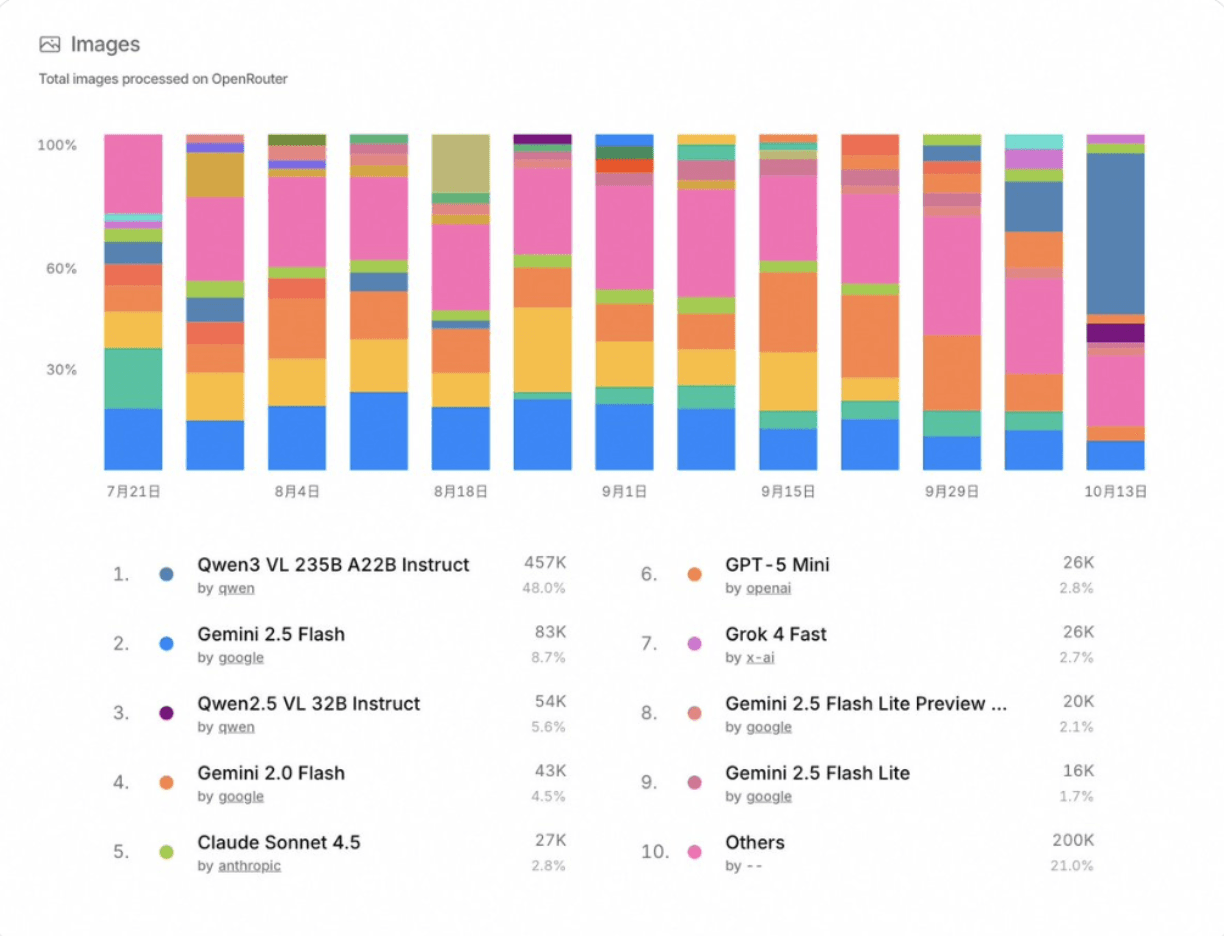
ベンチマークパフォーマンスを超えて、Qwen3-VL-235B-A22B-Instructはオープンソースコミュニティでも驚くべき成果を上げています。OpenRouterの最近の統計(2025年10月)によれば、画像処理で48%の市場シェアを持ち、他の主要なマルチモーダルモデルを上回り、Gemini 2.5 FlashやClaude Sonnet 4.5を上回っています。
特に、SiliconFlowはOpenRouterでのプロバイダーとしても機能し、Qwen3-VL-235B-A22B-Instructを他の主要なモデルであるDeepSeek-V3.2-Exp、GLM-4.6、Kimi K2-0905、またはGPT-OSS-120Bと共に提供し、開発者には最先端モデルへの統一アクセスを提供します。
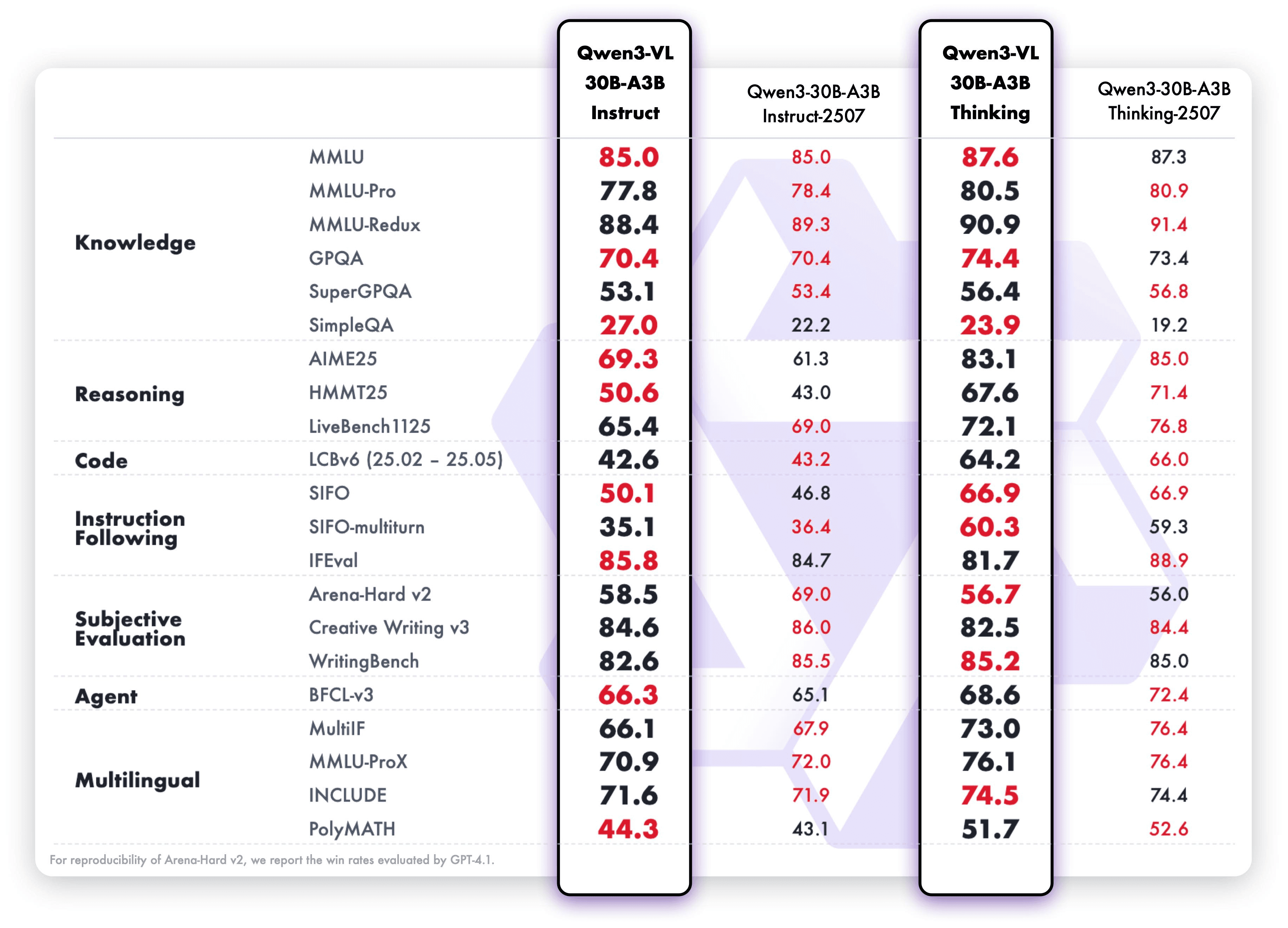
Qwen3-VL-30B-A3B-Instruct & Qwen3-VL-30B-A3B-Thinking:
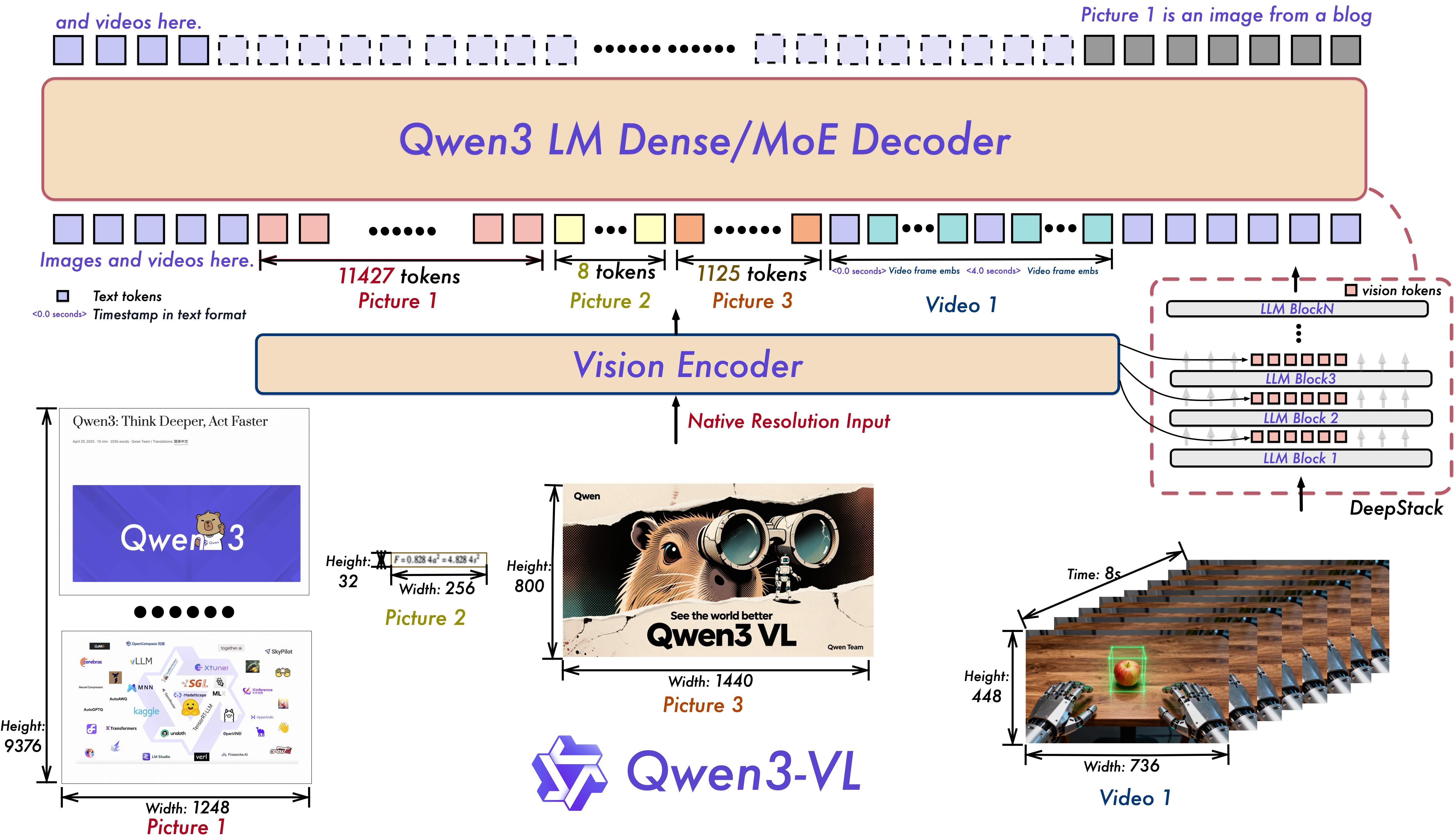
アーキテクチュラルイノベーション
Qwen3-VLの能力を支える3つの核心的な先進技術:
Interleaved-MRoPE: 強固な位置埋込による時、幅、高の全周波数割り当てを通じて、長時間ビデオ推論を強化します。
DeepStack: マルチレベルのViTの特徴を融合し、微細な詳細を捉え、画像–テキストの整合を鮮明にします。
テキストタイムスタンプ整合: T-RoPEを超えて、精密なタイムスタンプ基盤のイベント局所化を通じて、ビデオの時間的モデリングを強化します。
実世界の適用シナリオ
ビデオコンテンツ分析とインデックス作成 フレーム精度の理解を持つビデオの処理—「15分目に何が起こった?」や「赤い服を着たスピーカーによって議論された主要なトピックを要約して」。メディア企業、教育プラットフォーム、効率的な長編分析を必要とするコンテンツモデレーションに理想的です。
インテリジェントドキュメント処理 歴史的なアーカイブ、技術マニュアル、ぼやけたスキャンを含む32言語での複雑なドキュメントから構造化された情報を抽出します。法律調査、学術分析、企業知識管理のための書籍全体(最大1Mトークン)を取り扱います。
ノーコード開発とUI自動化 設計モックアップをアップロードしてプロダクション準備の整ったコードを生成したり、視覚エージェントにアプリを自律的にナビゲートさせたり—フォームを埋め、ワークフローをテストし、複数のタスクを実行します。プロトタイピング、QA自動化を加速し、手作業によるコーディング時間を削減します。
STEM教育と研究 科学的ダイアグラムと数式をステップバイステップで分析します。Thinkingエディションは複雑な問題を分解し、因果関係を説明し、学生、研究者、教育者に証拠に基づく回答を提供します。
すぐに開始する
1. 探求: Qwen3-VLシリーズをSiliconFlow Playgroundで試してみてください。
2. 統合: OpenAI互換のAPIを使用してください。SiliconFlow APIドキュメンテーションでフルAPI仕様を探索してください。
マルチモーダルエージェントの構築、UIワークフローの自動化、または数時間のビデオを分析する際に、Qwen3-VLは視覚的知能を提供します。
今すぐSiliconFlowのプロダクション準備が整ったAPIをご利用いただき、視覚的知能をワークフローに組み込んでください!
SiliconFlowで利用可能なすべてのモデルを探索しましょう →
