目次

要約: Ling-1T、最初の旗艦非思考モデルであるLing 2.0シリーズは、現在SiliconFlowで利用可能です。1兆スケールで効率的な推論のために構築され、約1兆の全パラメータを特徴とし、トークンごとに約500億がアクティブです。深く速い推論のためのEvo-CoTトレーニングを備え、数学、コード、フロントエンドタスクにおいて最先端のパフォーマンスを提供し、精度、速度、コスト効率のバランスを再定義します。
今日から始めましょう。SiliconFlowの実用的APIを利用して、OpenAI/Anthropic互換性を完全に備え、既存のワークフローに統合する準備が整っています!
今日は、SiliconFlowでLing-1Tをリリースします。これはLing 2.0シリーズの最初の旗艦非思考モデルです。1兆パラメータと約500億のトークンごとのアクティブパラメータで構築され、複雑なタスクにおいて効率的な推論を最適化しています。また、複雑な自然言語の記述を実行可能なコードへと変換し、競争レベルの数学問題を解決し、美学と機能性のバランスを取ったフロントエンドインタフェースを生成することにも優れています。更に重要なのは、短い推論チェーンで高い精度を達成し、それがより速い応答、低コスト、より信頼性のあるアウトプットに繋がることです。
SiliconFlowのLing-1T APIを使用すると予期できます:
競争力のある価格:Ling-1T $0.57/M tokens (Input) $2.28/M tokens (Output).
拡張コンテキストウィンドウ:131Kコンテキストウィンドウにより、より長い文書を処理し、複雑なタスクにわたってコンテキストを維持できます。
効率的なMoEアーキテクチャ:1兆の全パラメータで、トークンごとの約500億のアクティブパラメータがあり、完全密度モデルの計算上の負担を省いて強力な推論を提供します。
Evo-CoT最適化:20兆以上の高品質、推論密集トークンで事前訓練され、進化的なチェインオブソート(Evo-CoT)プロセスが多段階問題解決を促進します。
キーフィーチャーとベンチマークパフォーマンス
推論は知性の礎です。Ling-1Tはこれをさらに押し進め、効率的な推論と創造的な生成を組み合わせ、2つの主要ディメンションで優れています:
美学の理解とフロントエンド生成
アイデアを優雅なフロントエンドコードへ変換:Ling-1TはUI意図を解釈し、自然言語をクリーンで機能的なインタフェースに翻訳します。
見た目と同様に実行するコード:そのハイブリッド構文–機能–美学報酬システムは、コードの各行が正確さ、使いやすさ、視覚的魅力を兼ね備えていることを保証します。
ArtifactsBenchでランク1:Ling-1Tはフロントエンド生成で優れています。SiliconFlow APIを介して作成されたデモを下にスクロールしてご覧ください。
兆スケールでの発展的知能
知能に合わせてスケール:BFCL V3での約70%のツールコール精度を最小限の調整で達成し、兆スケールでの発展的推論と転送能力を明らかにします。
あなたの意図を理解:自然言語指示を正確に解釈し、意図と推論を一致させ、信頼できる目的指向の応答を生成します。
論理とデザインを橋渡し:抽象的なアイデアや推論ステップを機能的な視覚コンポーネントに変え、迅速なプロトタイプ作成を支援します。
プラットフォーム全体で構築:レスポンシブでクロスプラットフォームなフロントエンドコードを生成し、最小限の調整で展開する準備が整っています。
スタイルとコンテキストで書く:あなたのトーン、オーディエンス、ブランドアイデンティティに沿ったマーケティングコピーと多言語テキストを生成します。
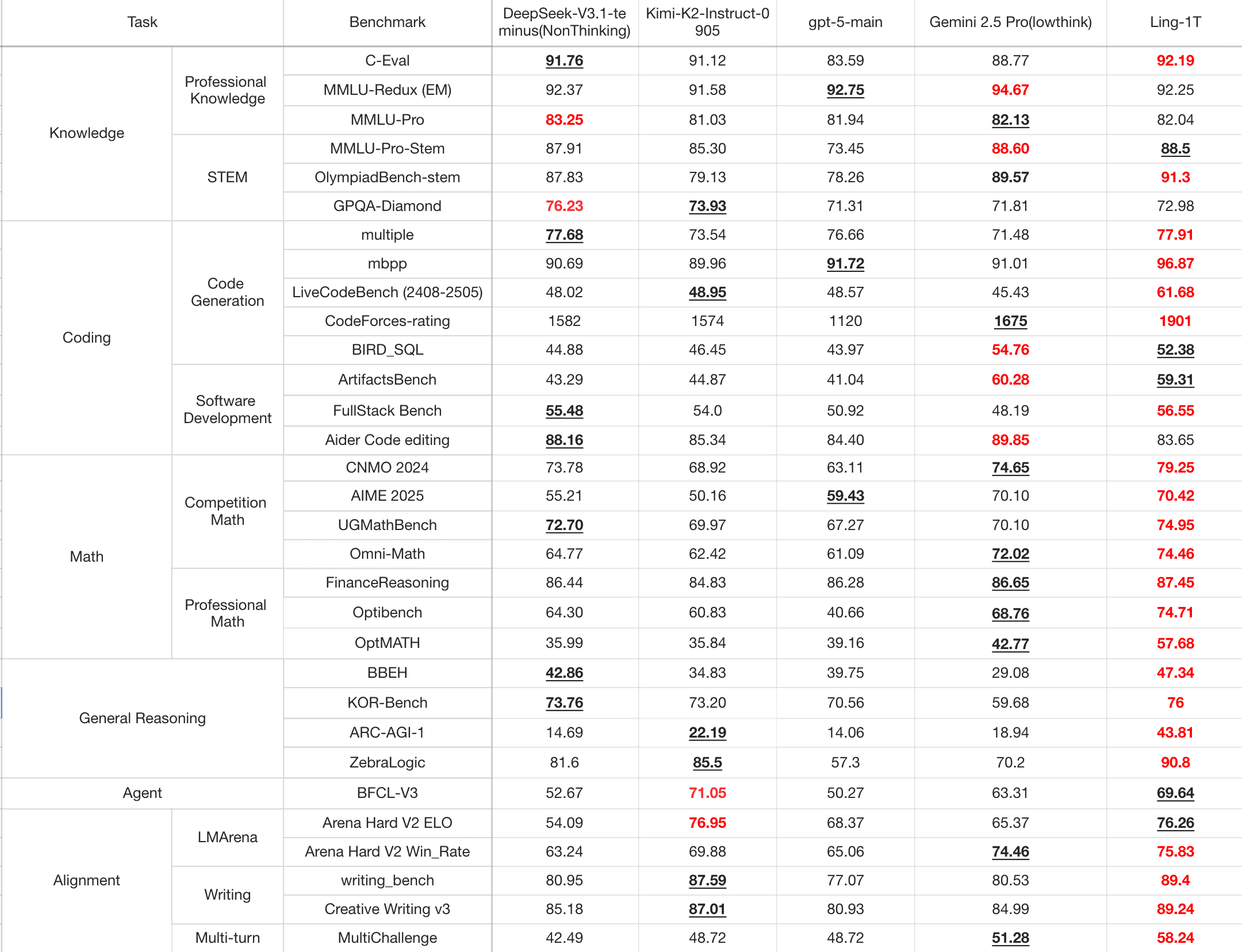
公平で包括的な評価を確保するために、Ling-1Tは、DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905、GPT-5-main、Gemini-2.5-Proを含むオープンソースおよびクローズドソースの旗艦モデルと比較されました。
コード生成、ソフトウェア開発、競争レベルの数学、専門的な数学、および論理的推論において、Ling-1Tは一貫して優れた複雑な推論パフォーマンスを提供し、これらのリーディングモデルに対して明確な全体的な優位性を示しています。
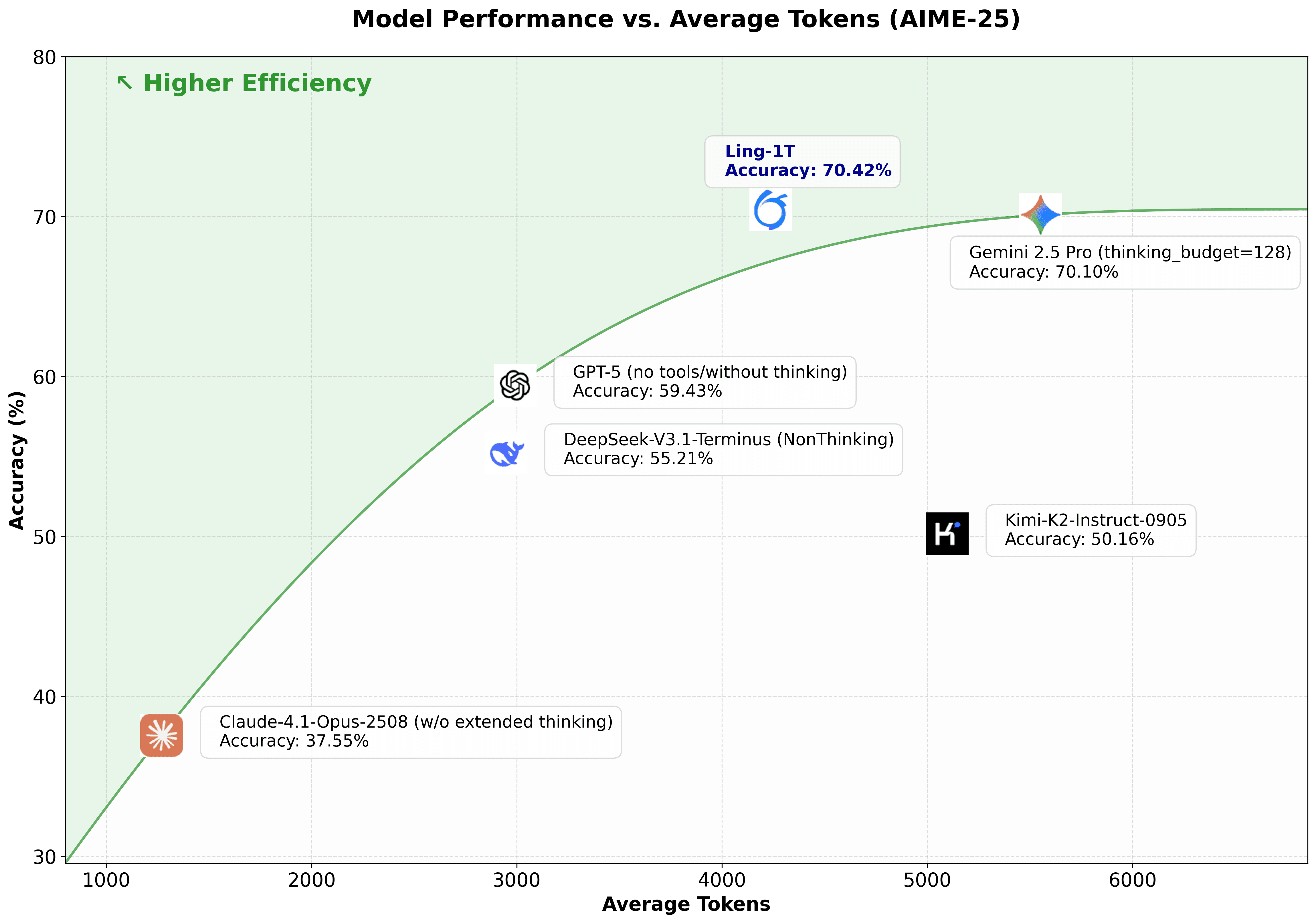
AIME 25ベンチマークで、Ling-1Tは推論の正確性と推論の長さのパレートフロンティアを拡張し、より少ない推論ステップでより高い精度を達成します。
複雑な推論、数学的分析、または多段階問題に取り組む開発者にとって、これはより高いPrecisionでより速い結果を意味します。
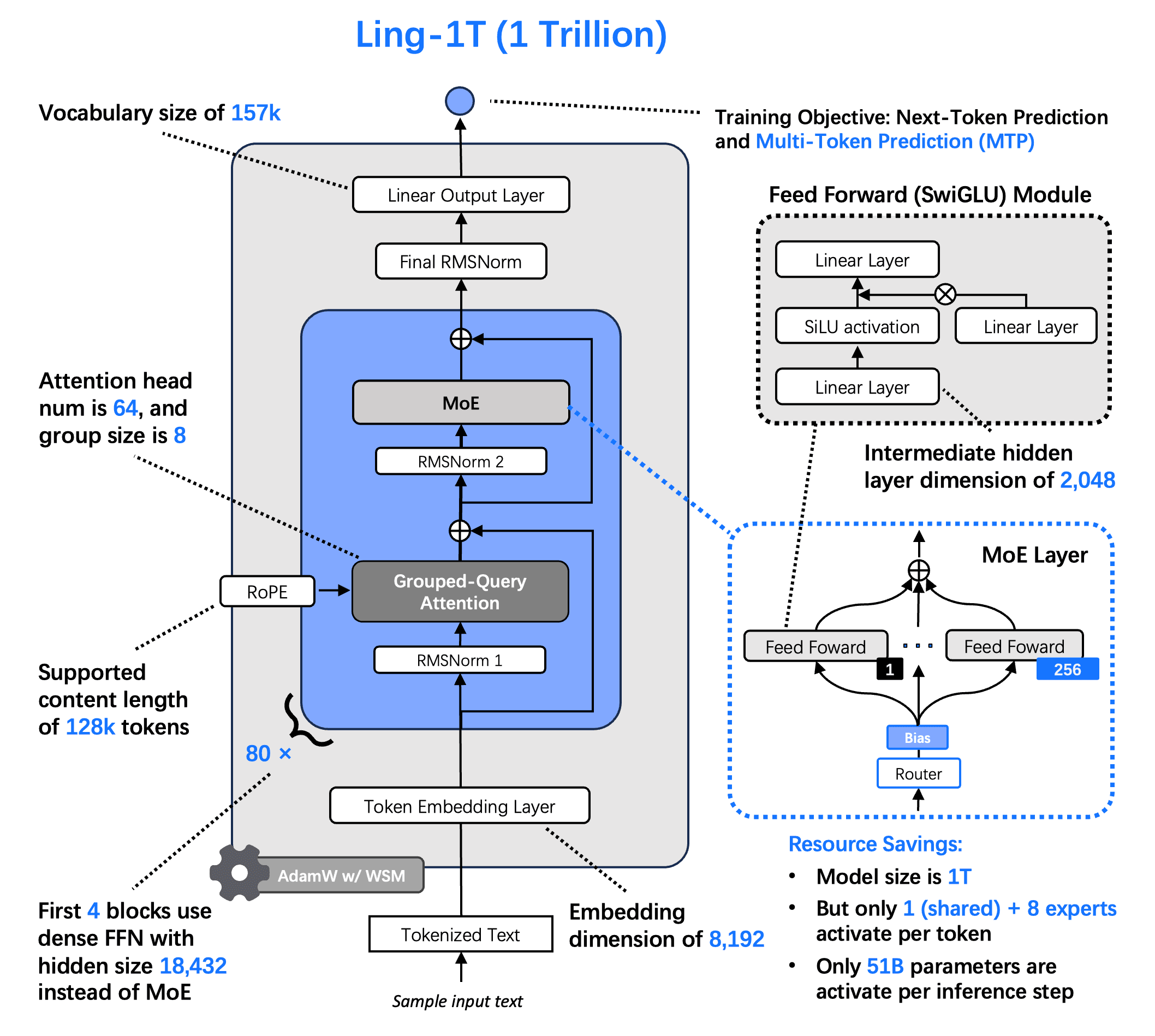
Modelアーキテクチャとトレーニング
主要なアーキテクチャの革新:
Ling 2.0アーキテクチャ上に配置され、Lingスケーリング法則に導かれたLing-1Tは、兆スケールの効率のためにゼロから設計されており、あらゆるスケールで安定した推論性能を保証します:
1T合計/50Bアクティブパラメータ、1/32 MoE活性化比
MTP層で強化された合成推論
Aux-loss-free, シグモイドスコアリング エキスパートルーティング、ゼロミーアン更新
QK正規化による完全に安定した収束
トレーニング効率:
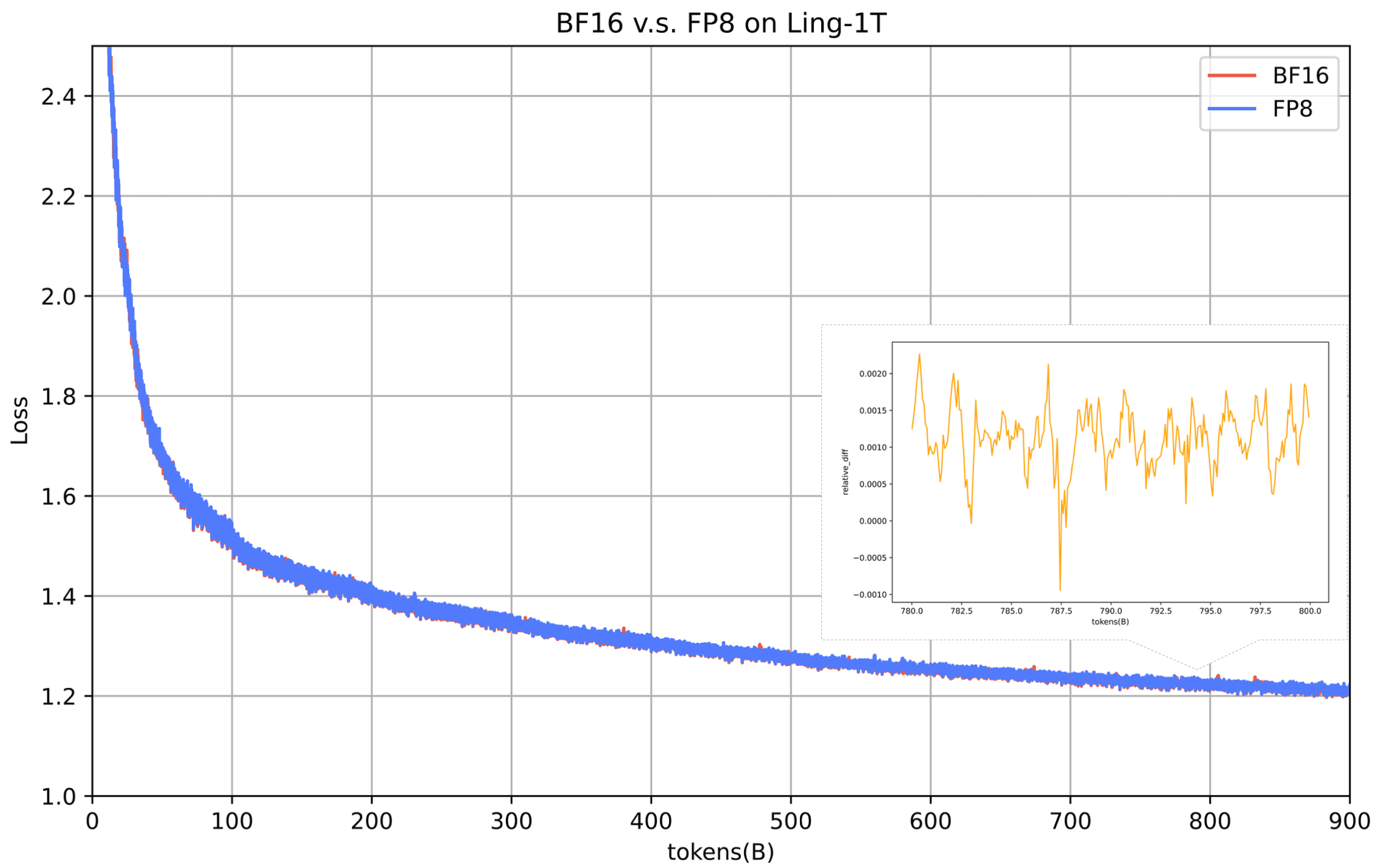
Ling-1TはFP8混合Precisionトレーニングを活用し、この方法でトレーニングされた最大の既知の基礎モデルとなりました。異種パイプライン最適化とWSM学習率スケジューラーを組み合わせ、40%以上のエンドツーエンド加速を達成し、兆スケールでの安定性を維持しました。
事前トレーニング:
20兆以上の高品質tokensで事前トレーニングされ、40%以上が推論密集データに割り当てられています。この基盤により、Ling-1Tは論理、多段階問題解決、複雑な分析において自然に強さを示します。
これらの能力をさらに強化するため、チェインオブソートデータを中間トレーニング中に統合し、推論の安定性と一般化を向上させました。
ポストトレーニング:
Ling-1Tは、高度な最適化を通じて推論能力の改善を続けています:
Evo-CoT (進化的チェインオブソート):推論のPrecisionと効率を段階的に向上させ、コンピューターステップが増えないように論理的思考を促進します。
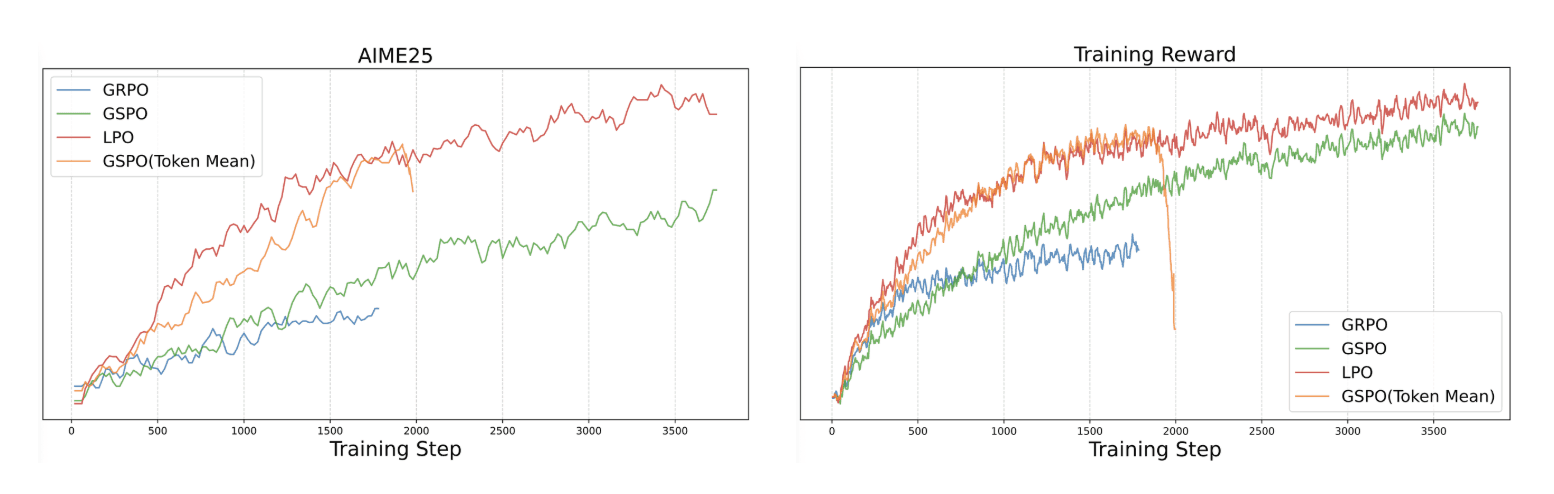
LPO (言語ユニットポリシー最適化):文レベルでの学習を最適化し、トークンシーケンスではなく自然言語の意味に応じた報酬を整えます。
すぐに始めましょう
1. 探求: Ling-1TをSiliconFlow Playgroundで試してみましょう。
2. 統合:当社のOpenAI互換のAPIを使用してください。SiliconFlow APIドキュメントでフルAPI仕様を確認してください。
SiliconFlowの実用的APIを通じて今日からLing-1Tを使用し始めましょう。効率と信頼性のある兆スケール推論を提供します。
