目次

要約:Qwen3-VL-8B — Qwen3-VLファミリーの最新メンバー — がSiliconFlowで公開されました。このコンパクトなビジョンランゲージモデルは、InstructとThinkingの2つのバリアントで包括的なマルチモーダル推論を提供し、VRAM消費を大幅に抑えています。8Bパラメータサイズにもかかわらず、Qwen3-VL-235Bフラッグシップモデルの完全な機能を継承し、空間およびビデオの理解を含む高度なテキスト生成を行います。Gemini 2.5 Flash LiteやGPT-5 Nanoといった大規模モデルを凌駕しながら、効率性と性能を両立するQwen3-VL-8Bは、SiliconFlowの本稼働APIを通じてご利用いただけます。
Qwen3-VLエコシステムを拡大し、SiliconFlowは Qwen3-VL-8Bシリーズ を私たちの モデルカタログに紹介します。このコンパクトでありながら強力なDense視覚ランゲージモデルは、パラメータサイズとマルチモーダル機能のバランスを再定義します。InstructおよびThinkingバリアントで利用可能で、フラッグシップの兄弟モデルQwen3-VL-235B-A22B-InstructおよびQwen3-VL-235B-A22B-Thinkingの完全な機能を継承し、優れたテキスト理解と生成、より深い視覚的認識と思考、拡張されたコンテキストの長さ、強化された空間およびビデオダイナミクスの理解、強化されたエージェントの機能を含みます。
SiliconFlowのQwen3-VL-8B APIでは、次のことが期待できます:
予算に優しい価格設定:
Qwen3-VL-8B-Instruct: $0.18/M tokens(インプット)および$0.68/M tokens (アウトプット)
Qwen3-VL-8B-Thinking: $0.18/M tokens(インプット)および$2.00/M tokens (アウトプット)
262Kコンテキストウィンドウ:テキスト、イメージ、およびビデオ全体にわたる長文マルチモーダル理解をサポートします。
シームレスな統合:SiliconFlowのOpenAI**/Anthropic互換API**で即座に構築するか、既存のワークフローに統合してください。
Qwen3-VL-8Bが重要な理由
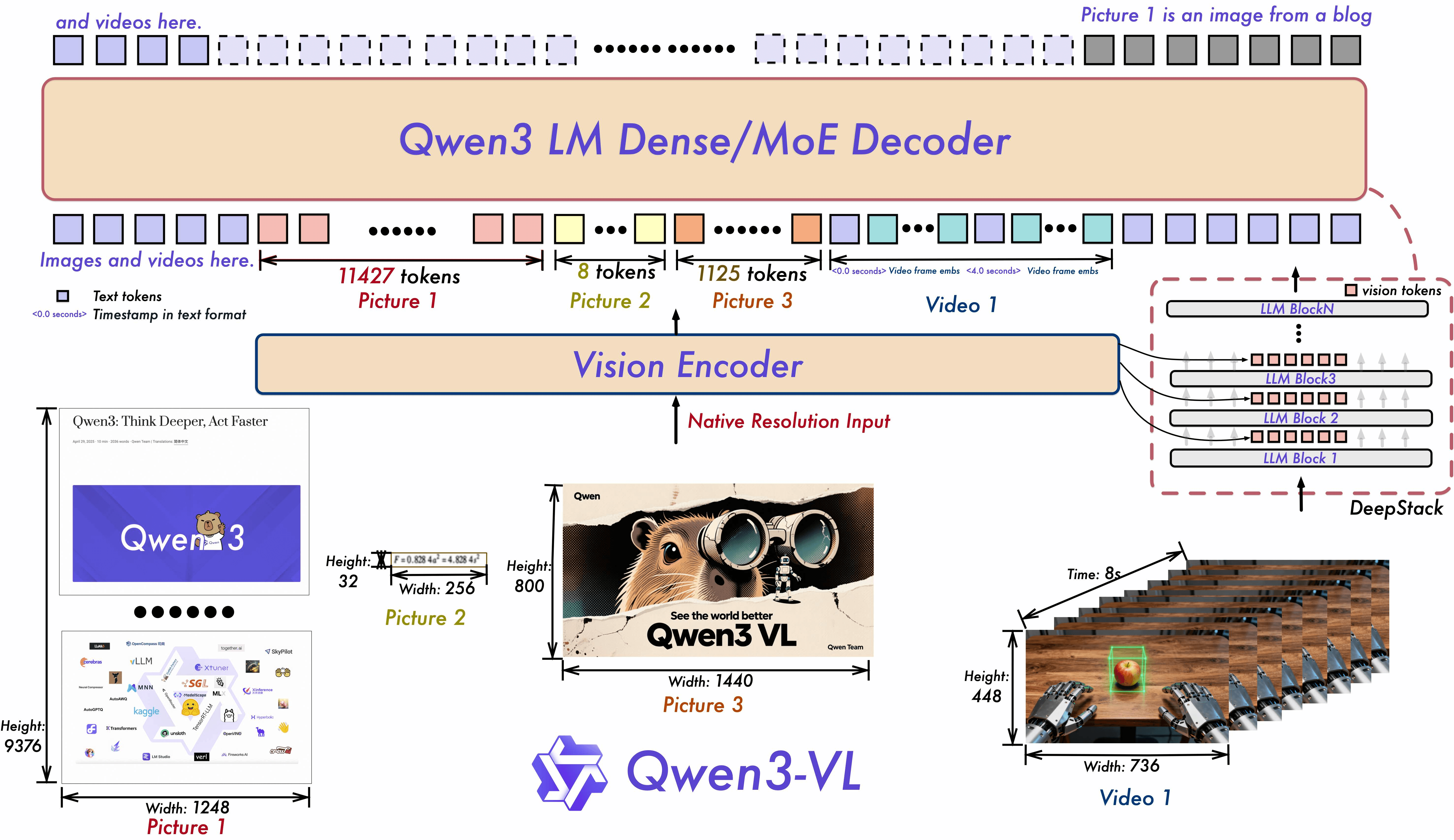
Qwen3-VLファミリーの基礎を基に、8Bバリアントは現実世界のアプリケーション向けに設計された包括的な改良を導入します:
視覚エージェント機能: PC/モバイルGUIを操作し、要素を認識し、機能を理解し、ツールを呼び出し、自律的にタスクを完了します。
高度な空間認識: オブジェクトの位置、視点、遮蔽を判断し、より強力な2D基盤を提供し、空間推論と体現型AIのための3D基盤を可能にします。
視覚コーディングブースト: イメージとビデオからDraw.io/HTML/CSS/JSを生成します。
長いコンテキストとビデオ理解: ネイティブ256Kコンテキスト(1Mまで拡張可能)。全体の回想と秒レベルのインデックス作成で、書籍や長時間のビデオを処理します。
強化されたマルチモーダル推論: STEM/数学において因果分析と合理的で証拠に基づいた回答で卓越しています。
拡大したOCR: 言語は19から32にサポートが拡大され、低照度、ぼやけ、傾き条件下での堅牢性が強化され、稀少または古代キャラクターや技術用語の取り扱いが改善され、長文ドキュメントの構造解析が向上しました。
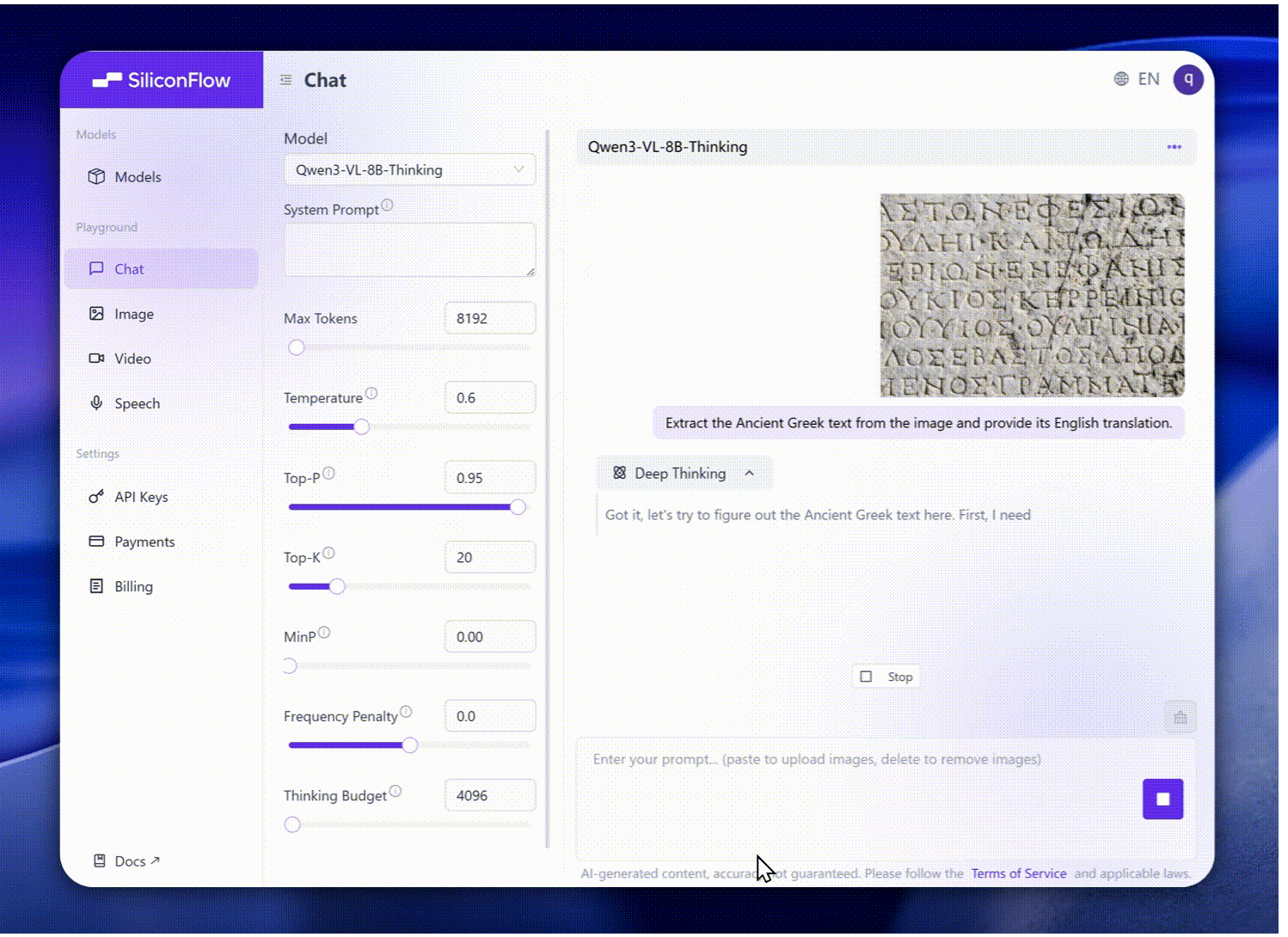
強化された視覚認識: より広い高品質の事前学習が包括的な認識(著名人、アニメ、製品、ランドマーク、植物/動物など)を可能にします。
純粋なLLM並みのテキスト理解: ロスのない統合的な理解のためのシームレスなテキスト-ビジョン融合。
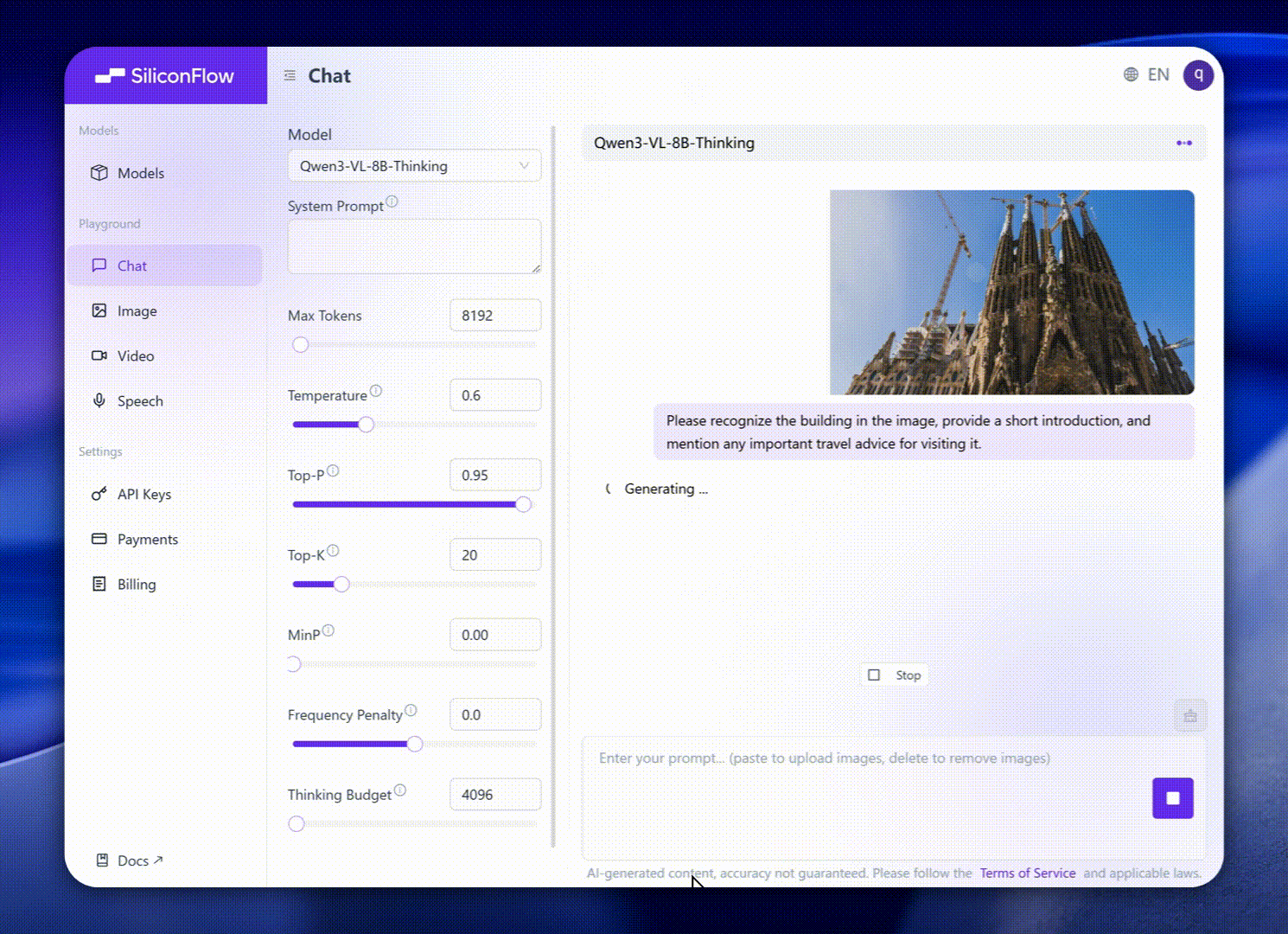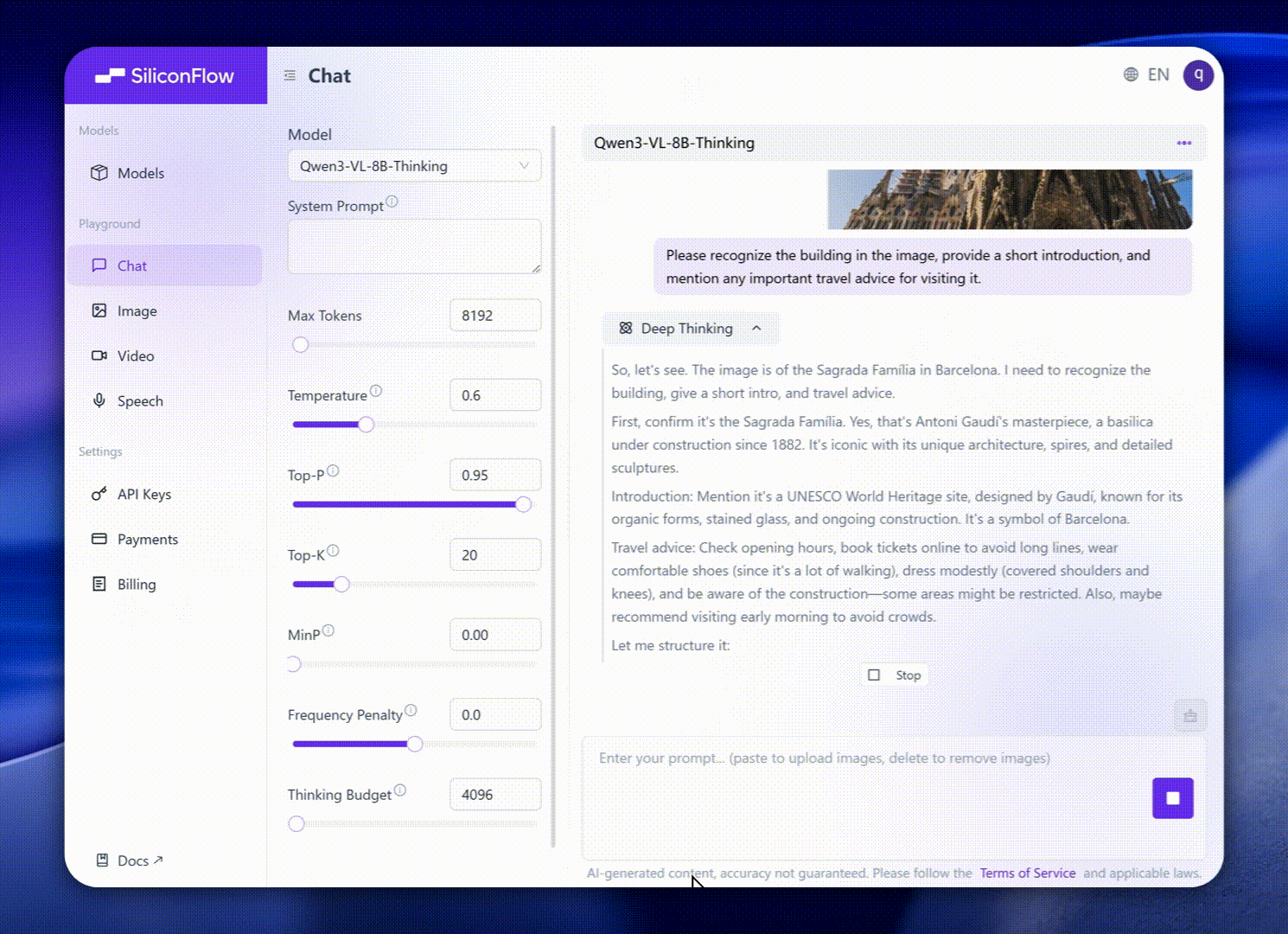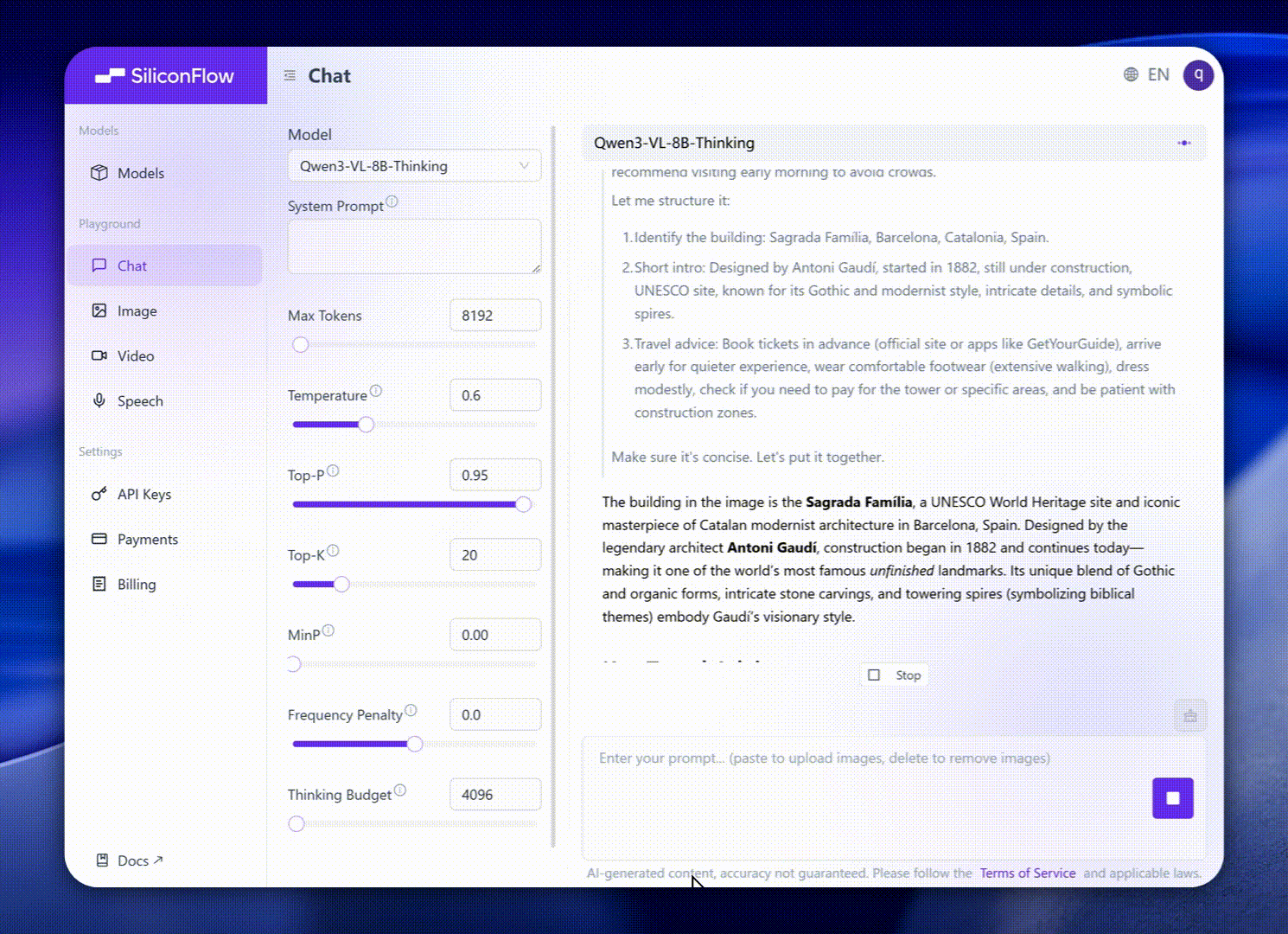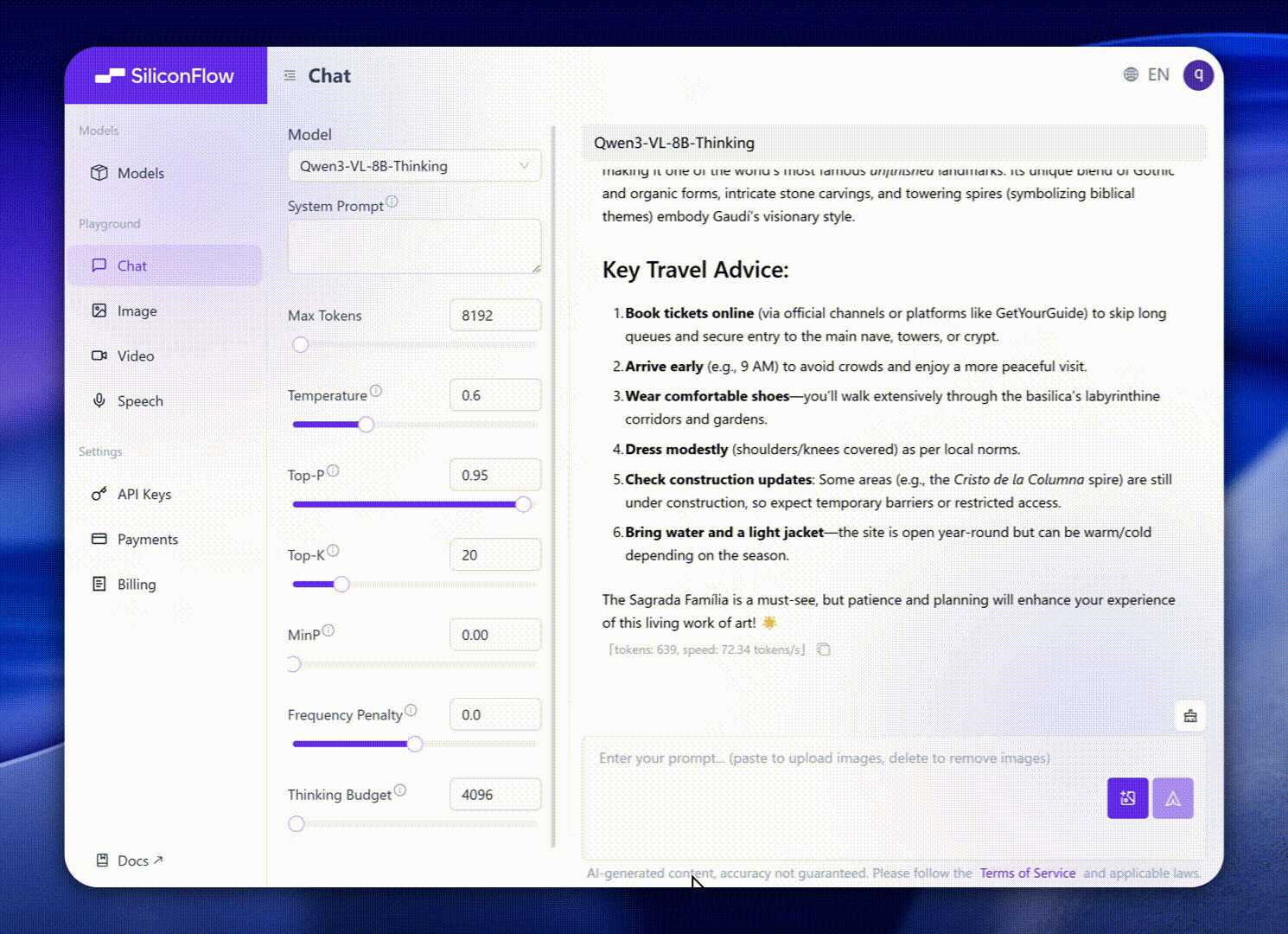
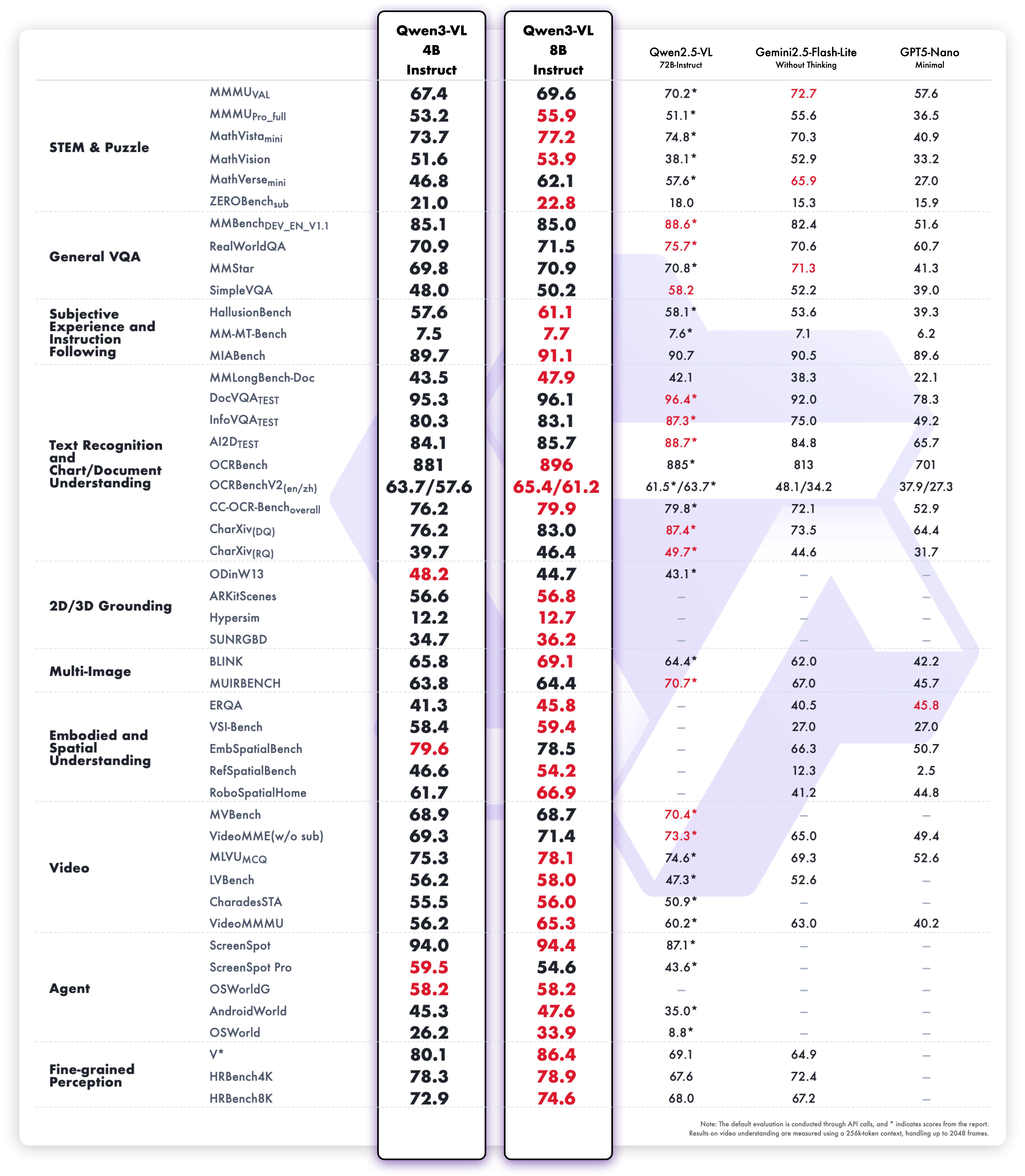
これらの強化点は、現実世界のベンチマークパフォーマンスに優れた結果をもたらします。Qwen3-VL-8Bは、STEM、VQA、OCR、ビデオ理解、エージェントベースのタスクにおける優れたパフォーマンスを提供し、Gemini 2.5 Flash Liteおよび**GPT-5 Nano、そしてはるかに大規模なQwen2.5-VL-72B**にも匹敵します。
特に、印象的な空間推論のパフォーマンスを達成し、体現型インテリジェンスアプリケーションの進展のための強力な基盤を提供します。
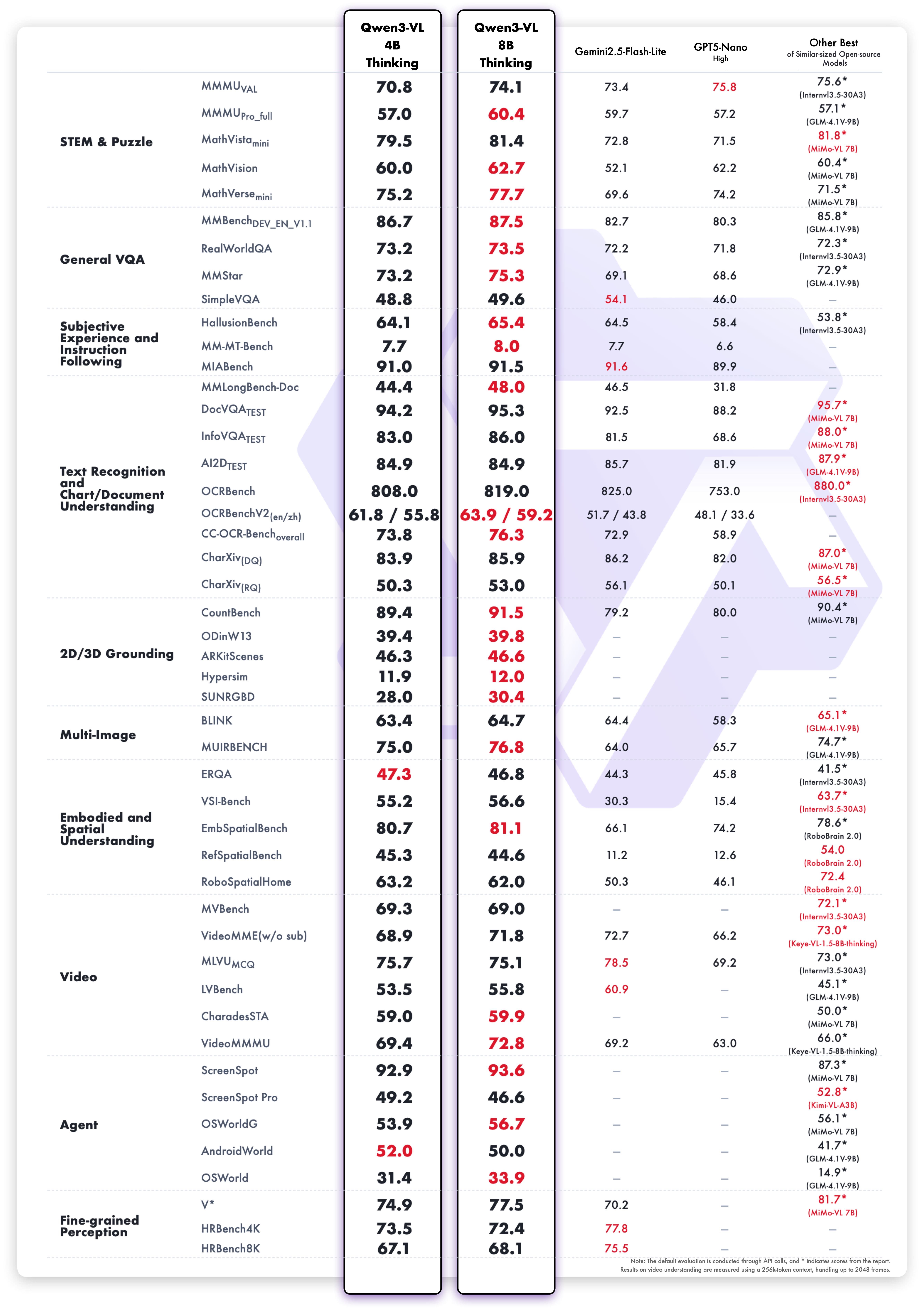
また、より小型のマルチモーダルモデルは常に基本的なトレードオフに直面します: 潜在的な視覚能力を高めることはしばしばテキスト理解を損なうという「シーソー効果」が、コンパクトで有能な視覚-言語モデルの作成に対する障壁となってきました。Qwen3-VL-8Bは、視覚Precisionとテキストの堅牢性のバランスの取れた共最適化を通じて、この制限を克服します。
建築的な革新と技術的な最適化を通じて、モデルはマルチモーダルの知覚を大幅に向上させながら、以下のベンチマークで示されたようにパワフルなテキスト理解を維持します。
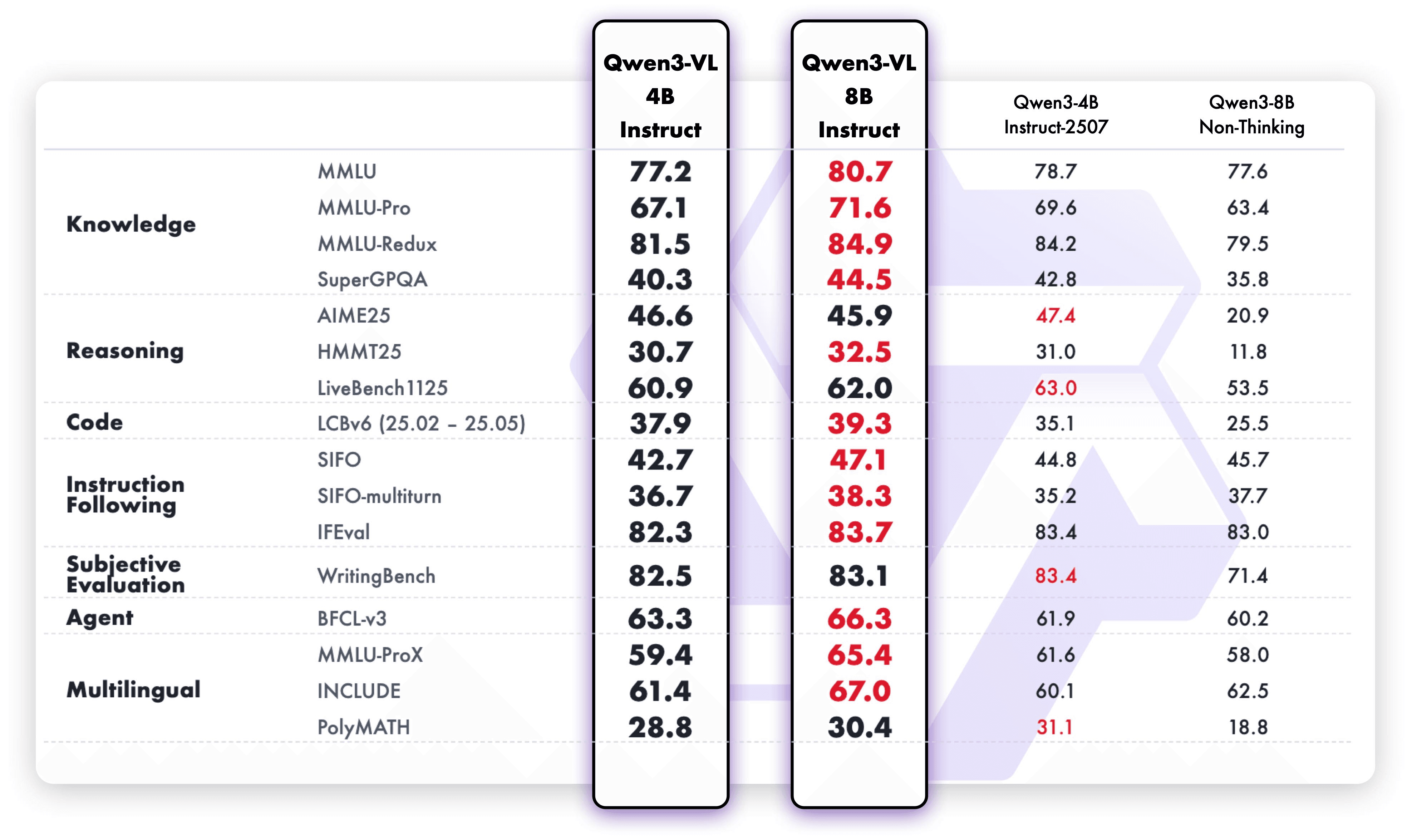
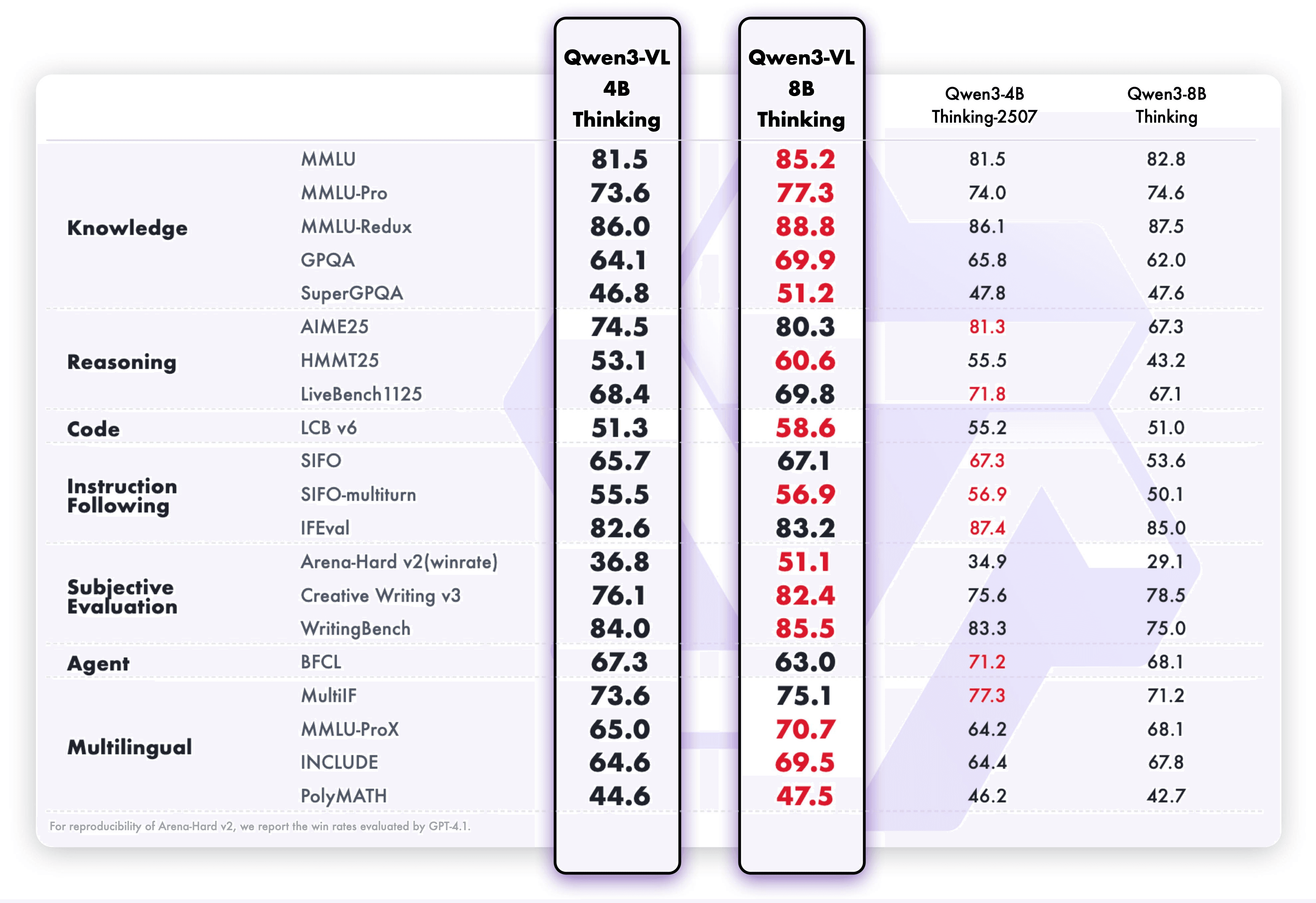
結果として? より多くの機能がより小さなモデルに収まります – 認識から推論まで、テキストからイメージとビデオまで。
実世界のアプリケーションシナリオ
このコンパクトな8B密集アーキテクチャと全スペクトルのマルチモーダル機能を備えたQwen3-VL-8Bは、現実世界のワークフローに先進的な視覚インテリジェンスをもたらします:
視覚推論&STEMタスク: 図形、グラフ、数学の式を解釈し、ジオメトリー、物理、化学の問題を明確な論理的説明で解決します。教育、研究、およびAIチュータリングシステムに理想的です。
文書理解&OCR:スキャン文書、レシート、技術論文から情報を抽出して要約します。32言語に対応し、複雑なレイアウト解析、テーブル認識、および構造化データ変換をサポートします。
動的ビジョン&エージェントインタラクション: ビデオフレームを分析し、GUI要素を認識し、PCまたはモバイルインターフェース内で相互作用をシミュレーション – 現実世界の環境で「見て考え行動する」自律エージェントを可能にします。
マルチモーダル作成: 視覚的入力をクリエイティブまたは技術的アウトプットに変換します。例えば、スクリーンショットからHTML/CSS/JSレイアウトを生成したり、イメージやクリップから説明的な物語を作成します。
インテリジェントアシスタント、文書分析システム、またはクリエイティブマルチモーダルツールを構築する場合、SiliconFlowのAPIサービスを通じてQwen3-VL-8Bがあなたのワークフローにフラッグシップレベルのマルチモーダルインテリジェンスをもたらします。
今すぐ始めましょう
探求: Qwen3-VL-8BシリーズをSiliconFlow Playgroundでお試しください。
統合: 私たちのOpenAI互換APIを使用してください。SiliconFlow APIドキュメントで完全なAPI仕様を探求してください。
今日からQwen3-VL-8Bを使って構築を始め、SiliconFlowの本稼働APIを通じてフラッグシップレベルのマルチモーダルインテリジェンスを体験してください!
