
Daftar Isi

## Pengantar
Dalam lanskap teknologi digital yang terus berkembang, konten video telah muncul sebagai pilar komunikasi, hiburan, dan pendidikan. Mengenali potensi besar dan kebutuhan akan inovasi di bidang ini, [Tencent](https://www.tencentcloud.com/products/ivh), pemimpin global dalam teknologi dan solusi digital, dengan bangga mempersembahkan [Hunyuan Video](https://hunyuanvideoai.com/). Platform open-sourced mutakhir ini dirancang untuk merevolusi cara kita menciptakan, berinteraksi, dan menyebarluaskan konten video. Dalam blog ini, kita akan membahas fitur, manfaat, dan dampak transformasional dari Hunyuan Video.
## Fitur Utama Hunyuan Video
### 1. Pengeditan Video yang Didukung AI
* **Alat Pengeditan Cerdas:** Hunyuan Video memanfaatkan algoritma AI canggih untuk memberikan saran cerdas dalam mengedit konten video. Alat ini dapat menganalisis rekaman video untuk merekomendasikan titik potong optimal, memastikan produk akhir yang halus dan menarik.
* **Transisi yang Disarankan:** AI dapat menyarankan transisi yang menarik secara visual antar adegan, meningkatkan aliran keseluruhan dan estetika video. Ini termasuk fade-ins, fade-outs, dissolves, dan efek lain yang dapat membuat video lebih dinamis.
### 2. Render & Penempatan di Cloud
* **Render Cepat:** Hunyuan Video menggunakan teknologi rendering berbasis cloud untuk memproses dan menyelesaikan konten video dengan cepat. Ini menghilangkan kebutuhan akan perangkat keras lokal yang kuat dan memungkinkan waktu penyelesaian yang lebih cepat.
* **Penempatan di Berbagai Platform:** Alat ini mendukung penempatan video yang mulus di berbagai platform, termasuk media sosial, layanan streaming, dan situs web. Ini memastikan bahwa konten Anda mudah diakses oleh audiens Anda, terlepas dari di mana mereka memilih untuk menontonnya.
### 3. Streaming Interaktif Real-Time
* **Streaming Berlatensi Rendah:** Hunyuan Video menawarkan streaming real-time dengan latensi minimal, memastikan bahwa acara langsung berjalan lancar dan tidak terputus. Ini penting untuk mempertahankan keterlibatan dan interaksi dengan audiens.
* **Kasus Penggunaan yang Serbaguna:** Streaming interaktif real-time ideal untuk berbagai aplikasi, termasuk konferensi virtual, konser langsung, sesi pendidikan, dan webinar. Ini menyediakan platform yang fleksibel dan dinamis bagi pembuat konten untuk terhubung dengan audiens mereka secara real-time.
## Di Balik Layar: Mengungkap Arsitektur Hunyuan Video
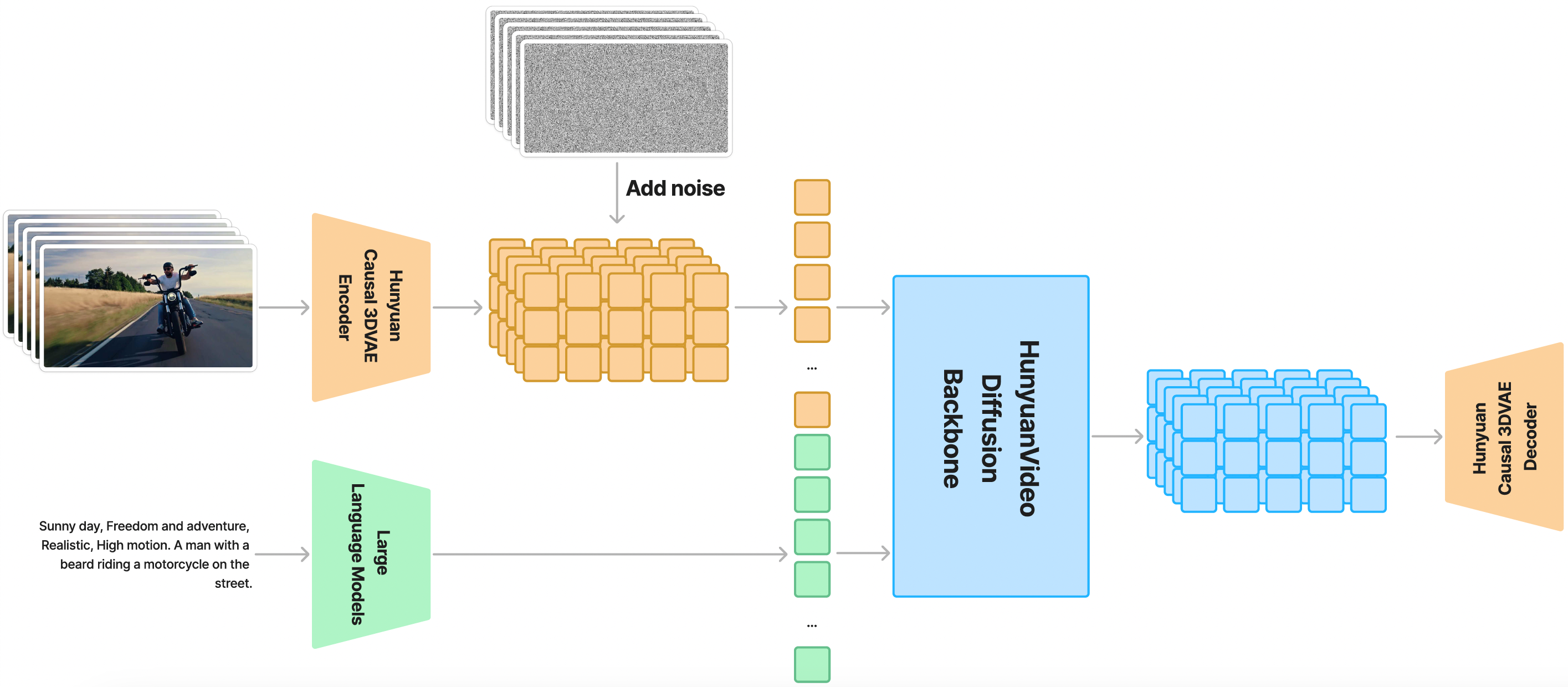
Dari gambar ini, kita dapat mengetahui bahwa Hunyuan Video dilatih pada ruang laten yang terkompresi secara spasial-temporal, dicapai melalui Causal 3D VAE. Teks prom diselesaikan menggunakan model bahasa besar dan berfungsi sebagai input pengkondisian. Contoh dari gambar di atas mengambil noise Gaussian dan input pengkondisian sebagai input dan menghasilkan output laten. Output laten ini kemudian didekode menjadi gambar atau video menggunakan dekoder 3D VAE.
### 1. Arsitektur Generatif Gambar dan Video Terpadu
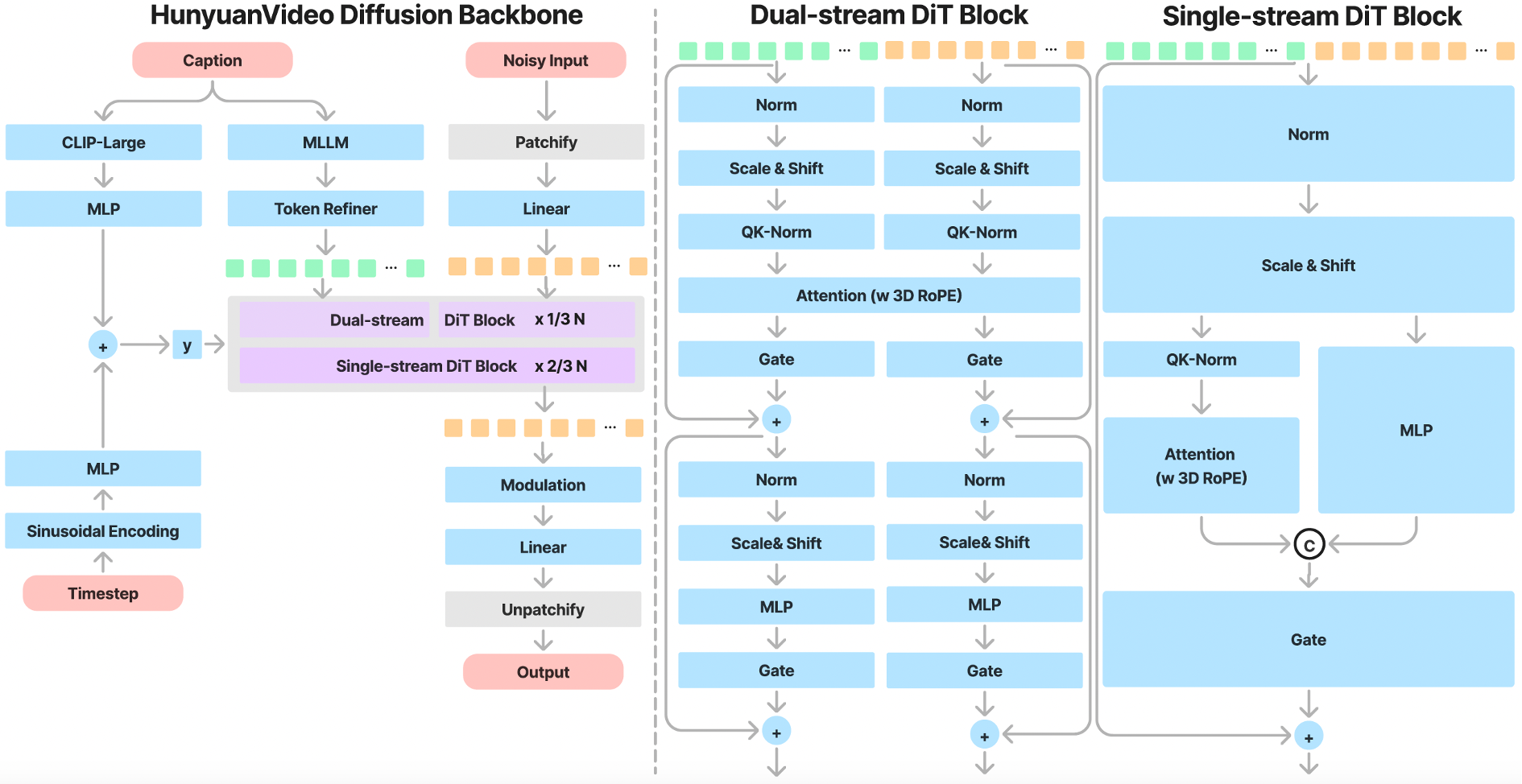
* **Desain Transformer dengan Mekanisme Perhatian Penuh:**Memungkinkan generasi gambar dan video yang terpadu.
* **Model Hibrida Dual-Stream ke Single-Stream:*** **Fase Dual-Stream:** Video dan token teks diproses secara independen melalui beberapa blok Transformer.
* **Fase Single-Stream:** Token yang digabungkan mengalami blok Transformer berikutnya untuk fusi multimodal yang efektif, menangkap interaksi kompleks antara informasi visual dan semantik.
### 2. Pengekode Teks MLLM: Meningkatkan Penyelarasan Multimodal
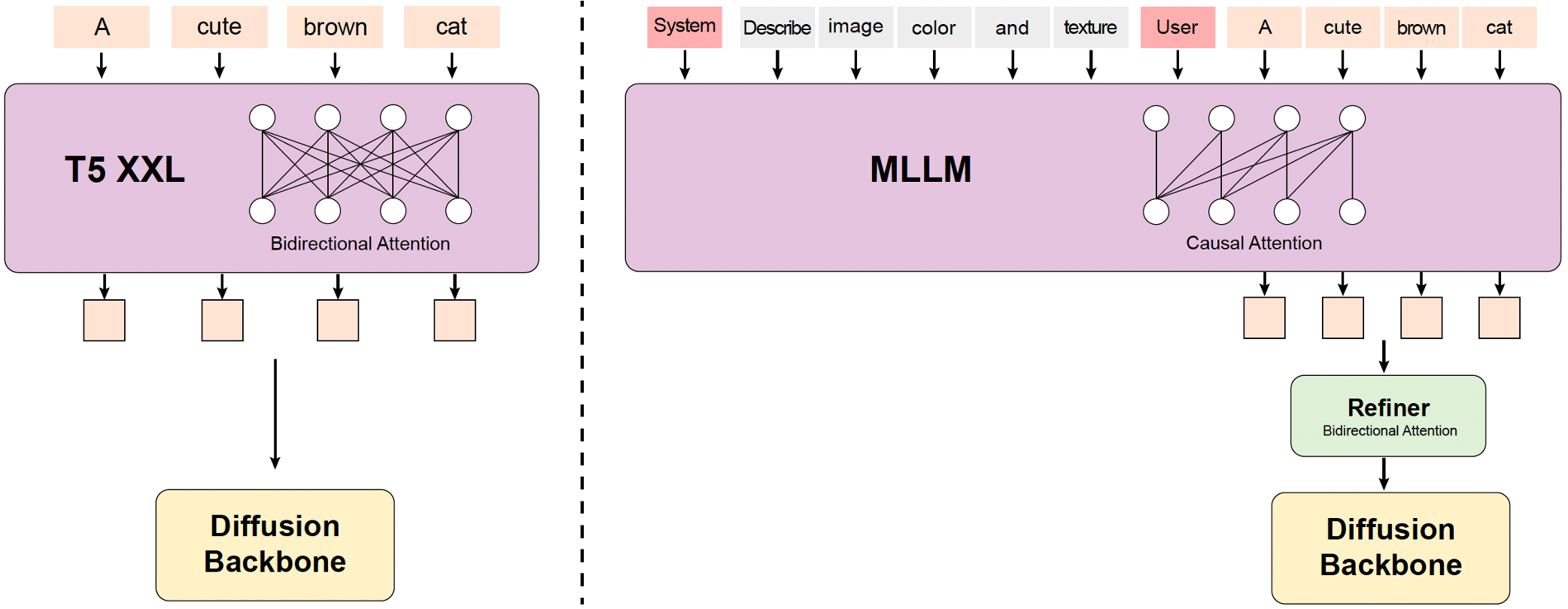
* **Struktur Hanya-Pengode:** Menawarkan penyelarasan teks-gambar yang lebih baik dan deskripsi detail gambar superior dibandingkan pengekode tradisional (mis., CLIP, T5-XXL).
* **Kemampuan Pembelajaran Zero-Shot:** Mengikuti instruksi sistem yang ditempatkan di depan prompt pengguna, meningkatkan fokus pada informasi kunci.
* **Peningkat Token Bidirectional:** Diperkenalkan untuk meningkatkan fitur teks guna panduan yang lebih baik dalam model difusi.
### 3. 3D VAE untuk Kompresi yang Efisien

* **CausalConv3D:** Melatih 3D VAE untuk mengompres video dan gambar ke dalam ruang laten yang ringkas.
* **Rasio Kompresi:** Panjang video (4x), ruang (8x), dan saluran (16x),
## Penyelaman Mendalam: Membuka Kekuatan Model Hunyuan
Youtuber pertama kali memperkenalkan bahwa model Hunyuan memiliki skala yang mengesankan dengan 13 miliar parameter, melampaui pesaing seperti Runway Gen 3 dan Luma 1.6 dalam menghasilkan video resolusi tinggi. Jumlah parameter yang besar ini memungkinkan model untuk menghasilkan konten yang sangat detail dan realistis, menjadikannya pilihan unggulan untuk pembuat konten. Selain itu, generasi teks-ke-video dengan fitur multimodal canggih Hunyuan dapat menciptakan konten yang lebih imersif dan detail. Dengan menggabungkan teks, gambar, dan jenis data lainnya, Hunyuan dapat menghasilkan video yang tidak hanya memukau secara visual tetapi juga kaya akan konteks dan detail, menawarkan tingkat kreativitas dan kedalaman baru.
Sementara model ini membutuhkan memori video yang signifikan (45-60 GB), panduan instalasi terperinci disediakan oleh Youtuber ini untuk GPU yang kompatibel, memastikan bahwa mereka dengan perangkat keras yang diperlukan dapat sepenuhnya memanfaatkan kemampuannya. Ini membuatnya lebih mudah bagi pembuat konten untuk mengatur dan mulai menggunakan Hunyuan, bahkan jika mereka tidak paham teknologi. Selain itu, kemampuan untuk mengunggah klip pendek dan bereksperimen dengan resolusi membuka peluang baru untuk kreativitas dan peningkatan video, memungkinkan YouTuber untuk mendorong batas-batas konten mereka. Selain itu, model Hunyuan menunjukkan keserbagunaan dan potensinya melalui berbagai demonstrasi. Dari detail vivid dari skenario mengemudi malam hari hingga eksplorasi yang aneh dari teks prompt yang ditawarkan oleh Youtuber, contoh-contoh ini menyoroti kemampuan model untuk menangani berbagai tipe dan gaya konten. Keserbagunaan ini menjadikannya alat berharga untuk setiap YouTuber yang ingin menciptakan video berkualitas tinggi dan menarik yang dapat memikat audiens mereka.
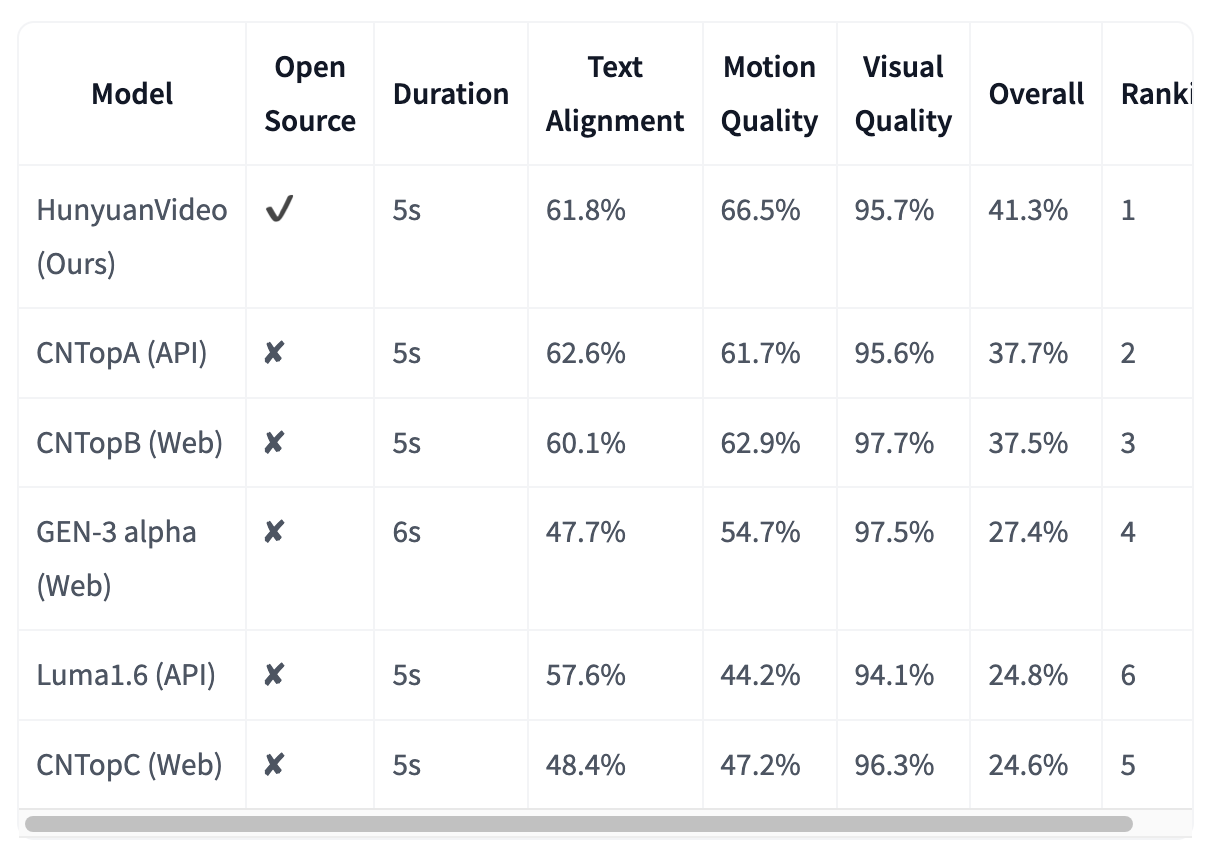
## Kinerja Tolok Ukur: Memimpin Dalam Sintesis Teks-ke-Video
HunyuanVideo telah dievaluasi [dalam esai ini](https://arxiv.org/abs/2412.03603) terhadap lima model generasi video terkemuka lainnya. Evaluasi tersebut melibatkan penggunaan 1.533 teks prompt untuk menghasilkan video dengan masing-masing model. Video-video ini kemudian dinilai berdasarkan tiga kriteria: penyelarasan teks, kualitas gerak, dan kualitas visual. HunyuanVideo melampaui semua model lain, terutama unggul dalam kualitas gerak. Ini menunjukkan keunggulan signifikan dalam menghasilkan video dengan gerak yang realistis dan halus. Sementara semua model menunjukkan kinerja kuat dalam penyelarasan teks, HunyuanVideo juga menghasilkan visual berkualitas tinggi.
## Uji di sini:
Huggingface: [https://huggingface.co/tencent/HunyuanVideo#-open-source-plan](https://huggingface.co/tencent/HunyuanVideo#-open-source-plan)
Situs resmi Hunyuan Video: [https://hunyuanvideoai.com/dashboard](https://hunyuanvideoai.com/dashboard)
## Kesimpulan
Saat kita menyimpulkan penjelajahan mendalam kita tentang Hunyuan Video oleh Tencent, sudah jelas bahwa platform revolusioner ini siap untuk mengubah batasan teknologi video. Dengan arsitektur mutakhirnya, yang menampilkan model generatif gambar dan video terpadu, Hunyuan Video bukan hanya alat, tetapi gerbang menuju kemungkinan kreatif yang belum pernah terjadi sebelumnya. Saat kita melangkah ke era baru teknologi video ini, Hunyuan Video berdiri sebagai mercusuar inovasi, mengundang kreator, bisnis, dan penggemar untuk menjelajahi, bereksperimen, dan mendorong batas dari apa yang mungkin. Baik Anda ingin meningkatkan konten Anda, merampingkan alur kerja Anda, atau sekadar mengalami masa depan video hari ini, Hunyuan Video pasti merupakan gerbang Anda!
