Daftar Isi

TL;DR:Qwen3-VL-8B — anggota terbaru dari keluarga Qwen3-VL — sekarang tersedia di SiliconFlow. Model bahasa-visual kompak ini memberikan penalaran multimodal skala penuh dalam varian Instruct dan Thinking, dengan konsumsi VRAM yang jauh lebih rendah. Meskipun memiliki ukuran parameter 8B, ini mewarisi kemampuan lengkap dari andalan Qwen3-VL-235B — dari pembuatan teks canggih hingga pemahaman spasial dan video — sambil mengungguli model yang lebih besar seperti Gemini 2.5 Flash Lite dan GPT-5 Nano. Membuktikan bahwa efisiensi menemui kinerja, Qwen3-VL-8B sekarang tersedia melalui API siap produksi dari SiliconFlow.
Memperluas ekosistem Qwen3-VL, SiliconFlow dengan bangga memperkenalkan **seri Qwen3-VL-8B ke dalam katalog model kami** — sebuah Model Dense bahasa-visual yang kuat namun kompak yang mendefinisikan ulang keseimbangan antara ukuran parameter dan kemampuan multimodal. Tersedia dalam varian Instruct dan Thinking, ini mewarisi kemampuan penuh dari saudara utamanya, Qwen3-VL-235B-A22B-Instruct dan Qwen3-VL-235B-A22B-Thinking, termasuk pemahaman teks yang superior dan generasi, persepsi visual dan penalaran yang lebih dalam, panjang konteks yang diperpanjang, pemahaman dinamis spasial dan video yang meningkat, dan kemampuan agen yang lebih kuat.
Dengan API Qwen3-VL-8B milik SiliconFlow, Anda dapat mengharapkan:
Harga Ramah Anggaran:
Qwen3-VL-8B-Instruct: $0.18/M tokens (input) dan $0.68/M tokens (output)
Qwen3-VL-8B-Thinking: $0.18/M tokens (input) dan $2.00/M tokens (output)
Jendela Konteks 262K: Mendukung pemahaman multimodal bentuk panjang melintasi teks, gambar, dan video.
Integrasi Seamless: Bangun secara instan dengan API yang kompatibel dengan SiliconFlow OpenAI/Anthropic, atau integrasikan ke dalam alur kerja Anda yang sudah ada.
MengapaQwen3-VL-8B Penting
Membangun di atas fondasi keluarga Qwen3-VL, varian 8B memperkenalkan serangkaian peningkatan komprehensif yang dirancang untuk aplikasi dunia nyata:
Kemampuan Agen Visual: Mengoperasikan GUI PC/mobile — mengenali elemen, memahami fungsi, memanggil alat, dan menyelesaikan tugas secara mandiri.
Persepsi Spasial Lanjutan: Menilai posisi objek, sudut pandang, dan okklusi; memberikan pondasi yang lebih kuat untuk penalaran spasial dan AI yang terwujud dalam 3D.
Peningkatan Pengkodean Visual: Menghasilkan Draw.io/HTML/CSS/JS dari gambar dan video.
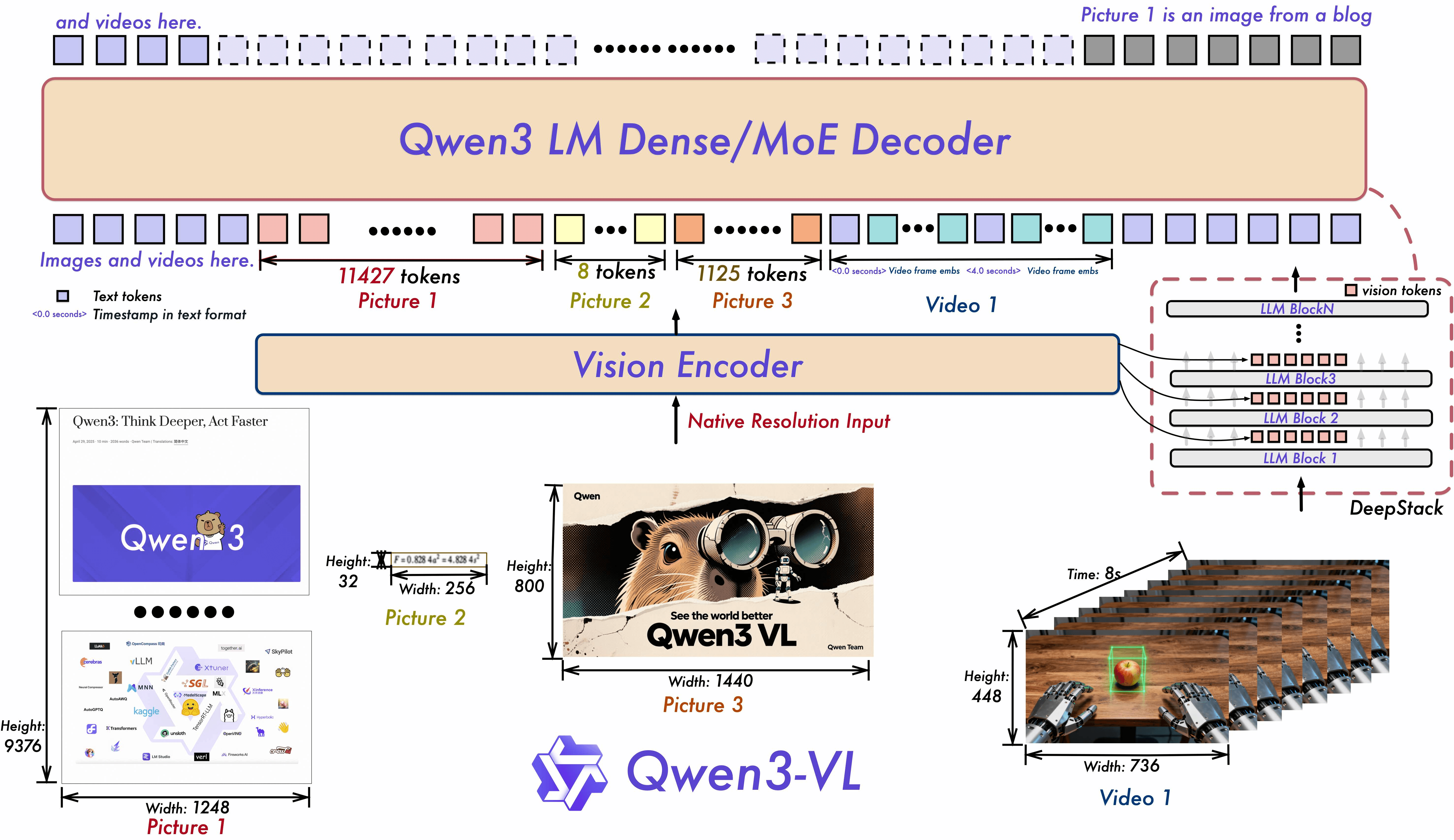
Pemahaman Konteks Panjang & Video: Konteks asli 256K (dapat diperluas hingga 1M), menangani buku dan video panjang berjam-jam dengan ingatan penuh dan indeksasi tingkat kedua.
Penalaran Multimodal yang Ditingkatkan: Unggul dalam STEM/Matematika dengan analisis kausal dan jawaban yang logis berbasis bukti.
Peningkatan OCR: Mendukung 32 bahasa (naik dari 19), dengan ketahanan yang lebih baik dalam kondisi cahaya rendah, blur, dan kemiringan, penanganan karakter langka atau kuno dan jargon teknis yang lebih baik, dan peningkatan dalam parsing struktur dokumen panjang.
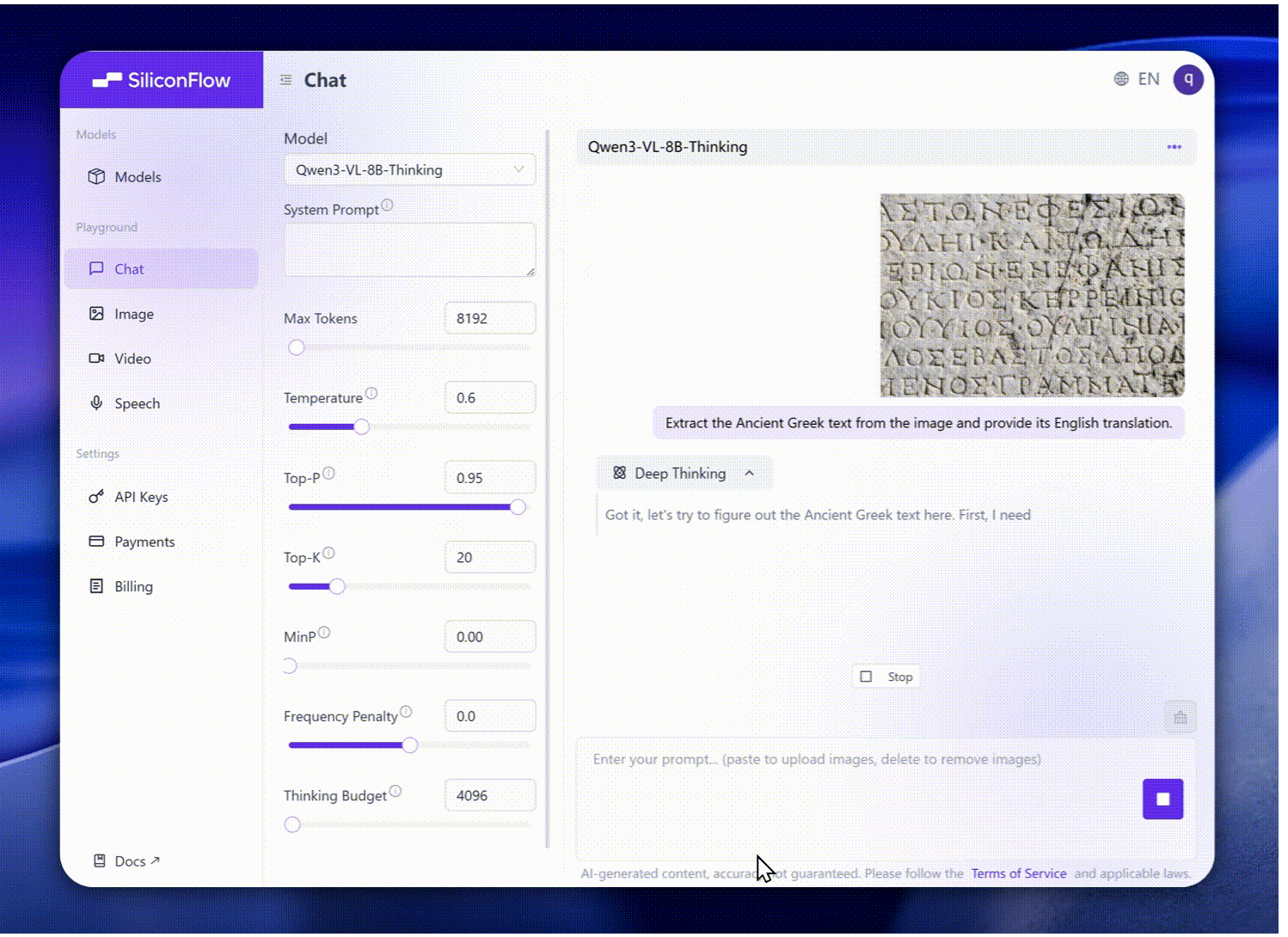
Peningkatan Pengakuan Visual: Pelatihan awal yang lebih luas dan berkualitas lebih tinggi memungkinkan pengakuan komprehensif — selebritas, anime, produk, landmark, flora/fauna, dan lainnya.
Pemahaman Teks Setara dengan LLM Murni: Fusi text-vision yang seamless untuk pemahaman yang menyeluruh dan tanpa kehilangan.
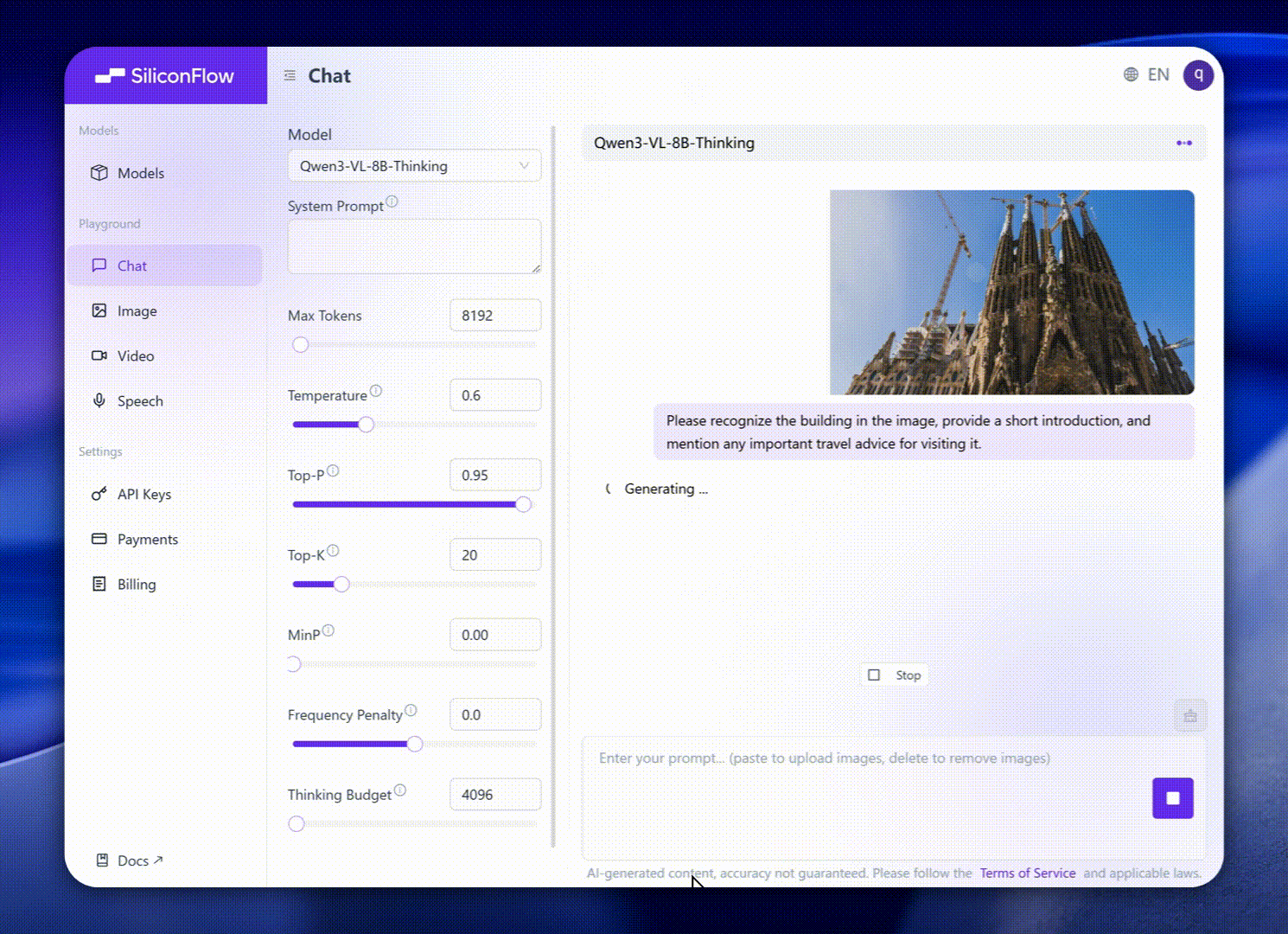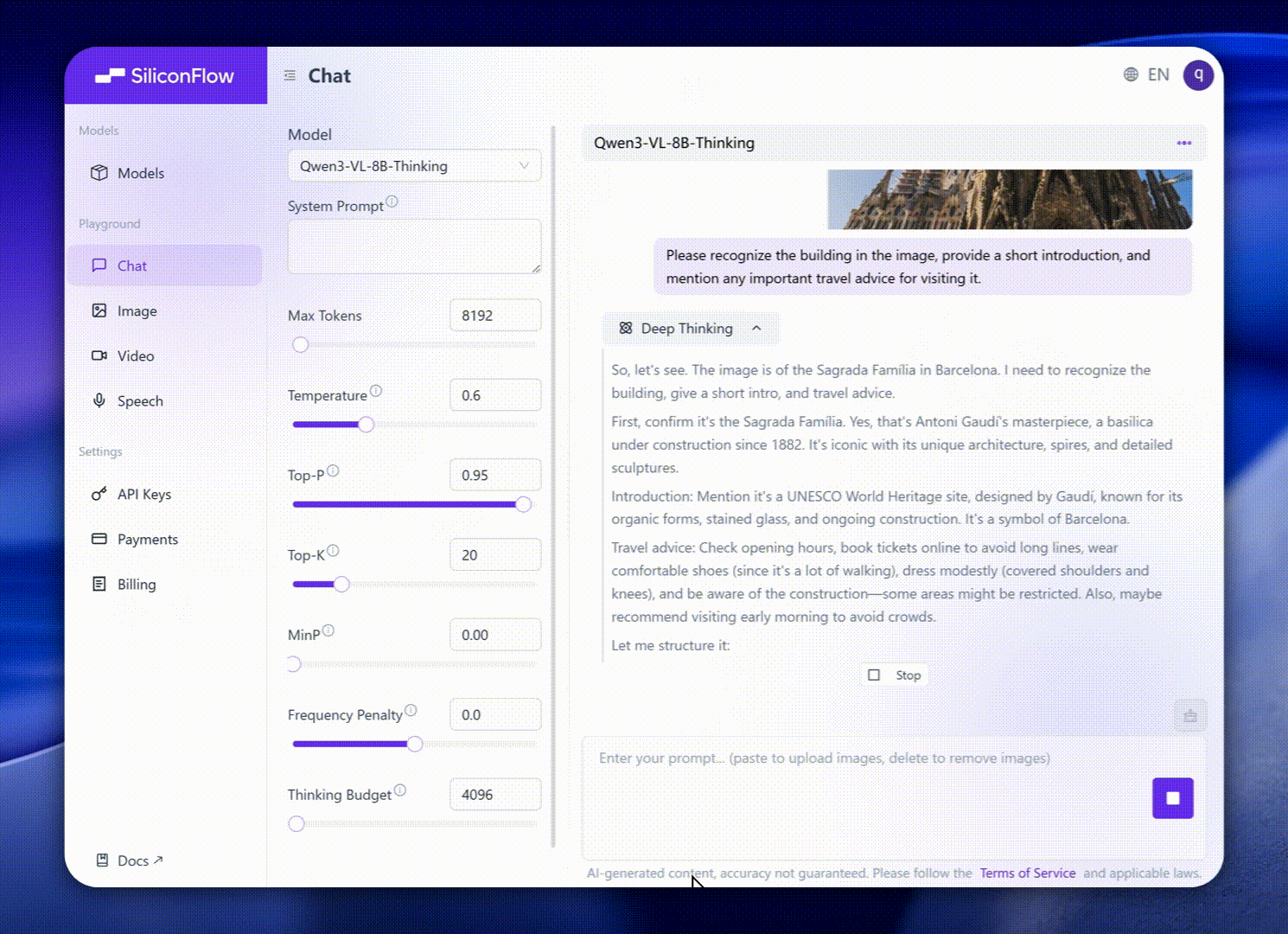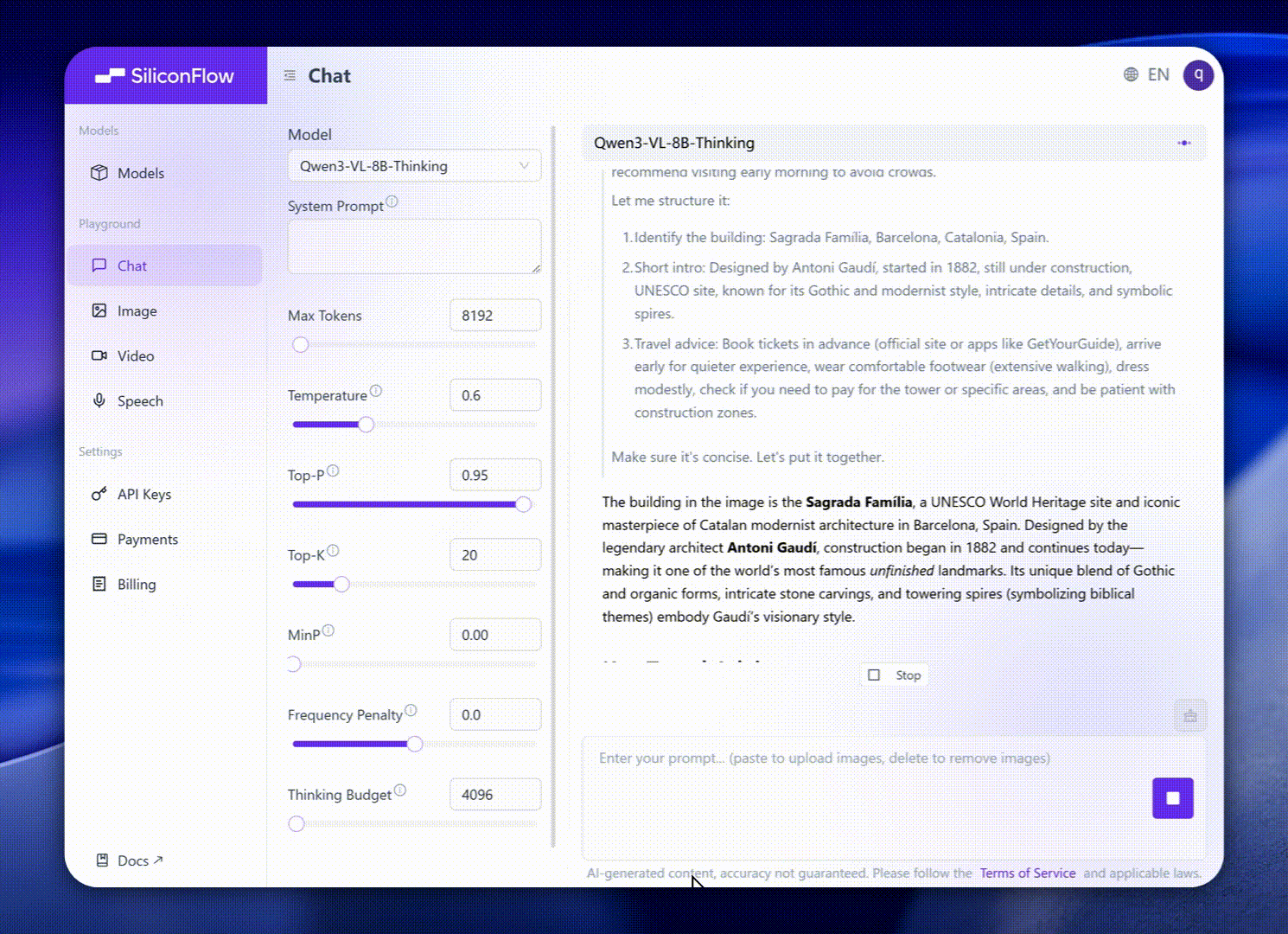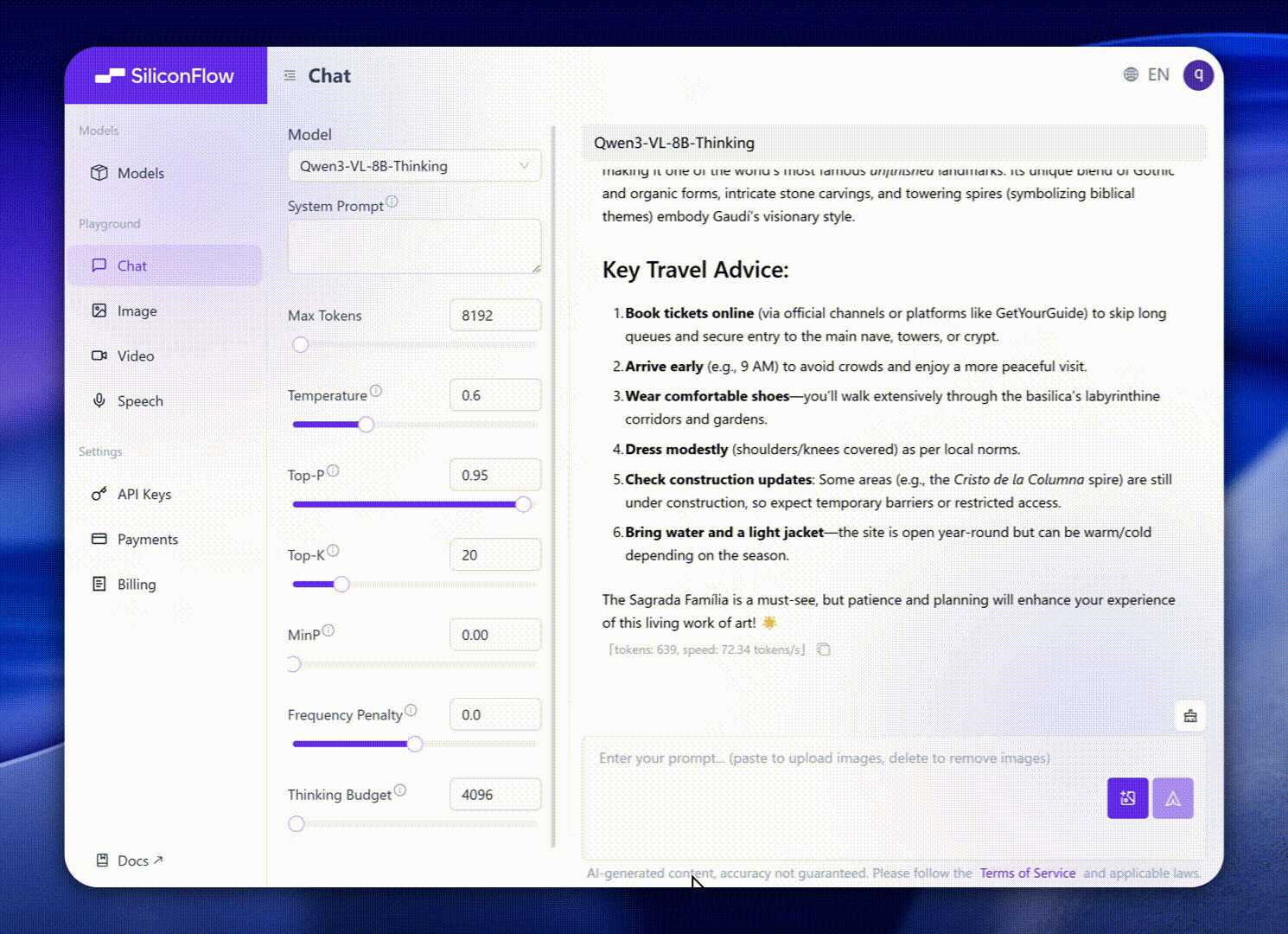
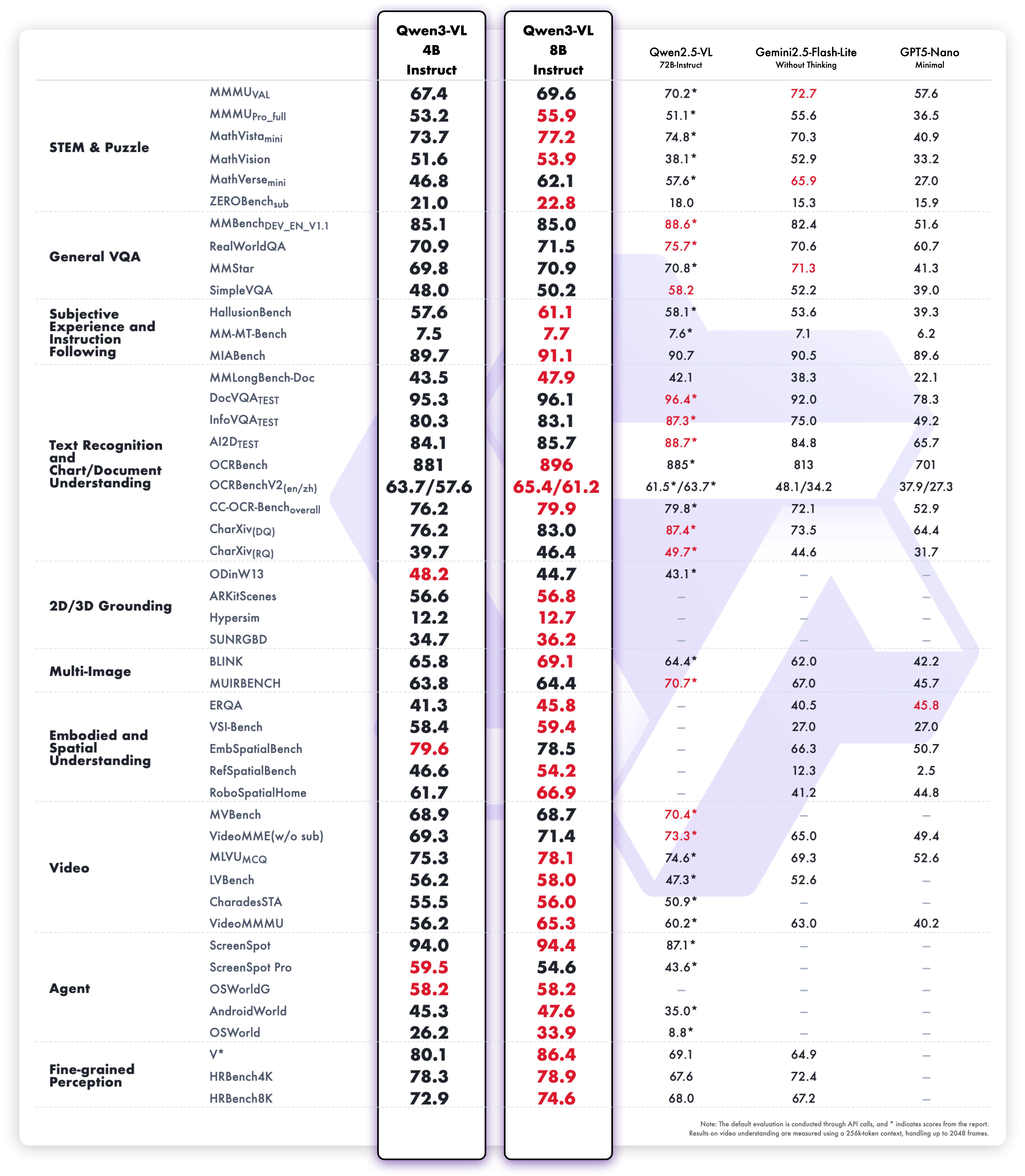
Peningkatan ini membawa kinerja tolok ukur dunia nyata yang luar biasa. Qwen3-VL-8B memberikan kinerja luar biasa di berbagai tolok ukur publik dalam STEM, VQA, OCR, pemahaman video, dan tugas berbasis agen — melampaui Gemini 2.5 Flash Lite dan **GPT-5 Nano, dan bahkan menyaingi
Qwen2.5-VL-72B yang jauh lebih besar.
Secara khusus, ia mencapai kinerja penalaran spasial yang mengesankan, menawarkan fondasi yang kuat untuk memajukan aplikasi kecerdasan yang diwujudkan.
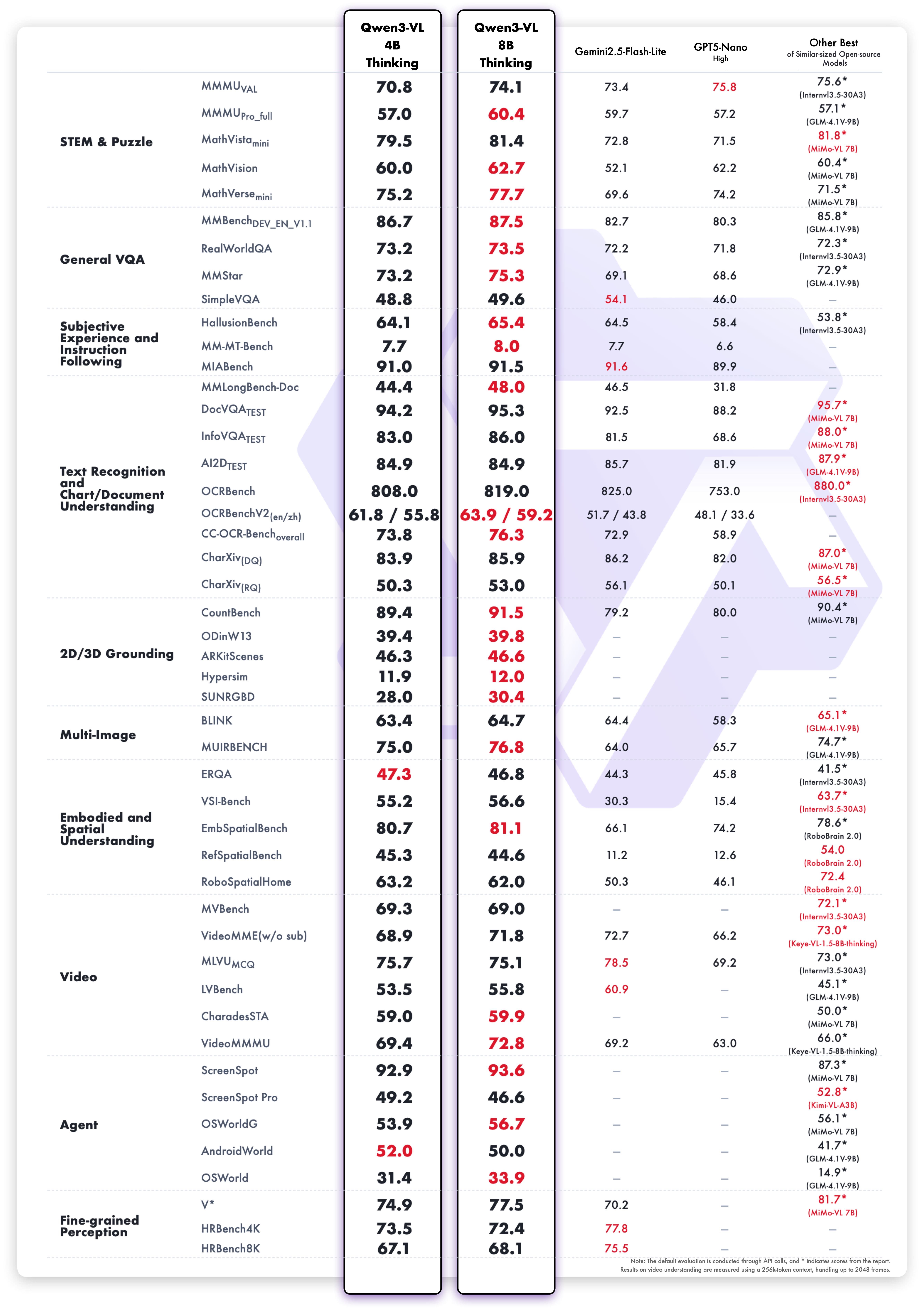
Selain itu, model multimodal yang lebih kecil selalu menghadapi pertukaran mendasar: meningkatkan kemampuan visual sering mengorbankan pemahaman teks, dan sebaliknya. Efek "seesaw" ini telah lama menjadi penghalang untuk menciptakan model bahasa-visual yang kompak namun capable. Qwen3-VL-8B mengatasi batasan ini melalui ko-optimalisasi seimbang dari presisi penglihatan dan ketahanan teks.
Melalui inovasi arsitektur dan optimisasi teknis, model ini secara signifikan meningkatkan persepsi multimodal sambil mempertahankan pemahaman teks yang kuat seperti yang ditunjukkan dalam tolok ukur di bawah.
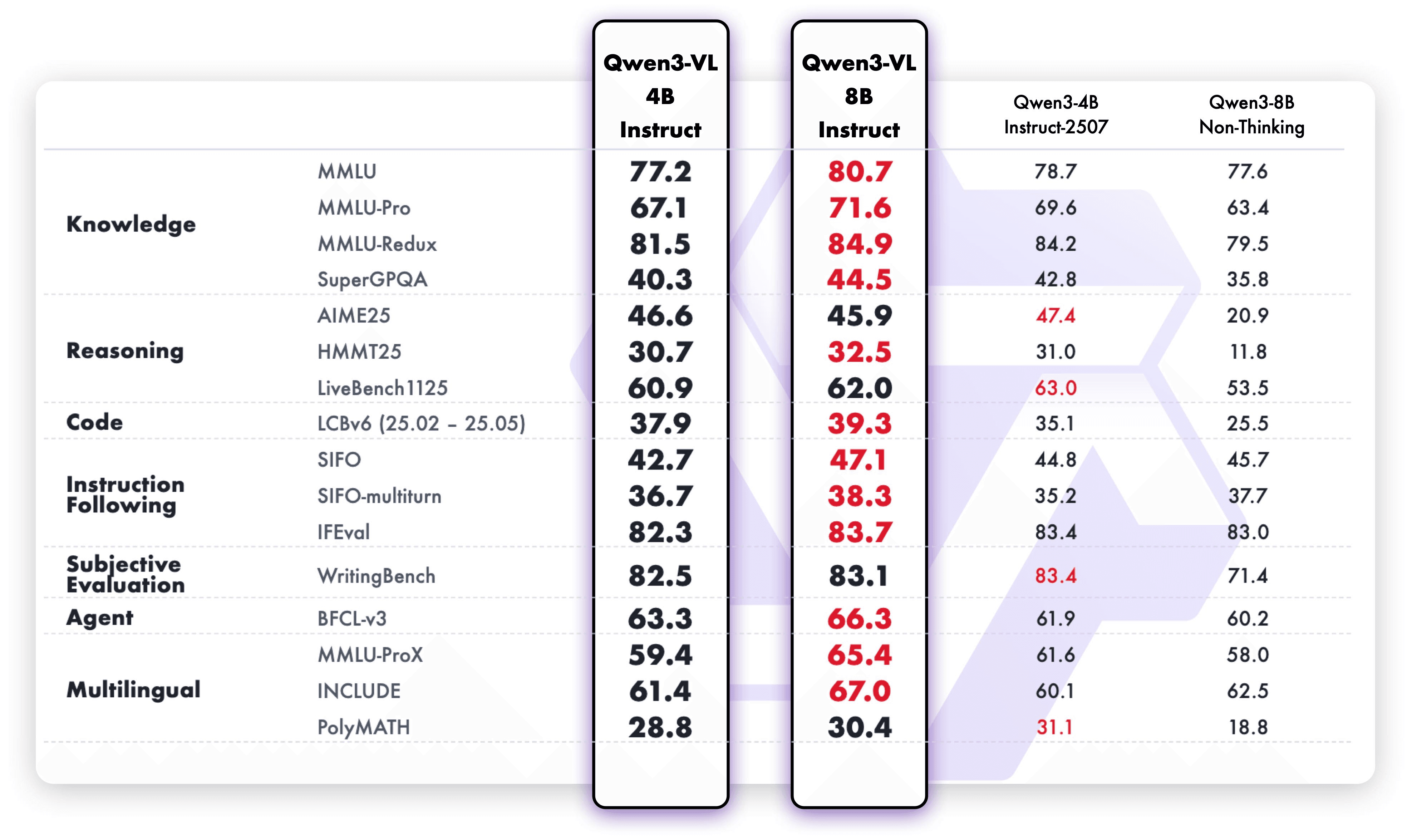
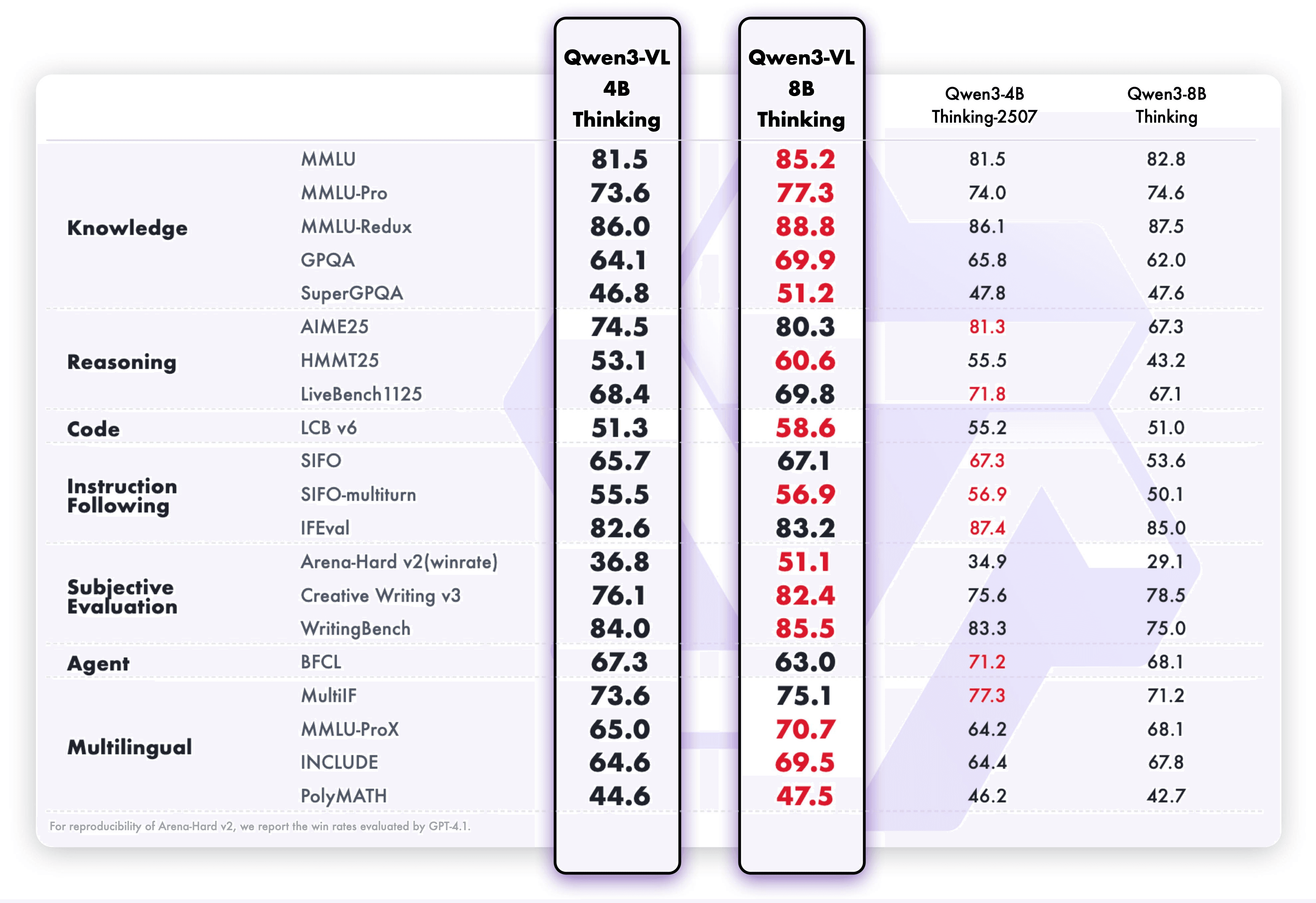
Hasilnya? Lebih banyak kemampuan sekarang dapat dimuat ke dalam model yang lebih kecil — dari pengakuan hingga penalaran, dari teks hingga gambar dan video.
Skenario Aplikasi Dunia Nyata
Dengan arsitektur 8B dense-nya yang kompak dan kemampuan multimodal yang penuh spektrum, Qwen3-VL-8B membawa kecerdasan visual lanjutan ke dalam alur kerja dunia nyata:
Penalaran Visual & Tugas STEM: Menafsirkan diagram, grafik, dan rumus matematika untuk menyelesaikan masalah geometri, fisika, atau kimia dengan penjelasan logis yang jelas. Ideal untuk pengajaran, penelitian, dan sistem bimbingan AI.
Pemahaman Dokumen & OCR: Menyediakan kemampuan membaca dan menganalisis informasi dari dokumen yang dipindai, kwitansi, atau makalah teknis dalam 32 bahasa. Mendukung parsing tata letak yang kompleks, pengenalan tabel, dan konversi data terstruktur.
Interaksi Dinamis Visional & Agen: Menganalisis frame video, mengenali elemen GUI, dan mensimulasikan interaksi dalam antarmuka PC atau mobile — memungkinkan agen otonom yang dapat "melihat, menalar, dan bertindak" di lingkungan dunia nyata.
Kreasi Multimodal: Mengkonversi input visual menjadi output kreatif atau teknis, seperti menghasilkan layout HTML/CSS/JS dari tangkapan layar atau menulis narasi deskriptif dari gambar dan klip.
Apakah Anda membangun asisten cerdas, sistem analisis dokumen, atau alat multimodal kreatif, Qwen3-VL-8B membawa kecerdasan multimodal tingkat flagship ke dalam alur kerja Anda melalui layanan API dari SiliconFlow.
Mulai Sekarang Juga
Eksplorasi: Cobalah seri Qwen3-VL-8B di playground SiliconFlow.
Integrasikan: Gunakan API yang kompatibel dengan OpenAI milik kami. Eksplorasi spesifikasi API lengkap di dokumentasi API SiliconFlow.
Mulailah membangun dengan Qwen3-VL-8B hari ini dan rasakan kecerdasan multimodal tingkat flagship melalui API siap produksi dari SiliconFlow!
