Daftar Isi

TL;DR: Step 3.5 Flash is now live on SiliconFlow. As StepFun AI's most capable open-source foundation model, it delivers frontier deep reasoning, agentic coding, and long-context processing with the efficiency required for real-time interactions. By leveraging 3-way Multi-Token Prediction to reach 100–300 tok/s speed and 3:1 Sliding Window Attention ratio for efficient 262K context handling, it maximizes throughput while minimizing overhead. Now at $0.1/M input | $0.3/M output on SiliconFlow, Step 3.5 Flash brings elite-level intelligence with immediate responsiveness to your production workflows.
We're excited to bring Step 3.5 Flash to SiliconFlow. As StepFun AI's most capable open-source foundation model, it is engineered to bridge the gap between reasoning depth and efficiency. By activating only 11B of its 196B total parameters via sparse MoE architecture, it rivals the intelligence of top-tier proprietary models (GPT5.2 high/Claude Opus 4.5/Gemini 3 Pro) especially in complex math and Agent scenarios while maintaining the agility essential for real-time interaction.
Now, via SiliconFlow's OpenAI-compatible API, you can access:
Highly Competitive Pricing: Step 3.5 Flash at $0.1/M tokens (input) and $0.3/M tokens (output)
Deep Reasoning at Speed: Fast generation speeds of 100–300 tok/s
Efficient 262K Long Context: Consistent performance across massive datasets while significantly reducing computational overhead by leveraging 3:1 SWA ratio
Seamless Integration: Deploy instantly via SiliconFlow or integrate directly with industry-standard tools like Claude Code, Cline, Kilo Code, and Roo Code
Whether you're building autonomous coding agents, conducting deep research, or processing massive codebases, SiliconFlow's Step 3.5 Flash API delivers the performance you need with immediate responsiveness.
In the following sections, we'll break down the key capabilities behind Step 3.5 Flash, showcase its real-world performance, and provide configuration tips to maximize your developer experience.
What's New about Step 3.5 Flash
For many developers, choosing an LLM has long been a compromise between the 'slow-but-deep' reasoning of flagship models and the 'fast-but-shallow' responses of flash models. This trade-off becomes particularly acute in today's agentic scenarios, where complex tasks demand high-level intelligence without sacrificing immediate responsiveness.
Step 3.5 Flash is designed to close this gap. Below, we highlight the key capabilities that enable fast execution without sacrificing reasoning quality:
Deep Reasoning Fast
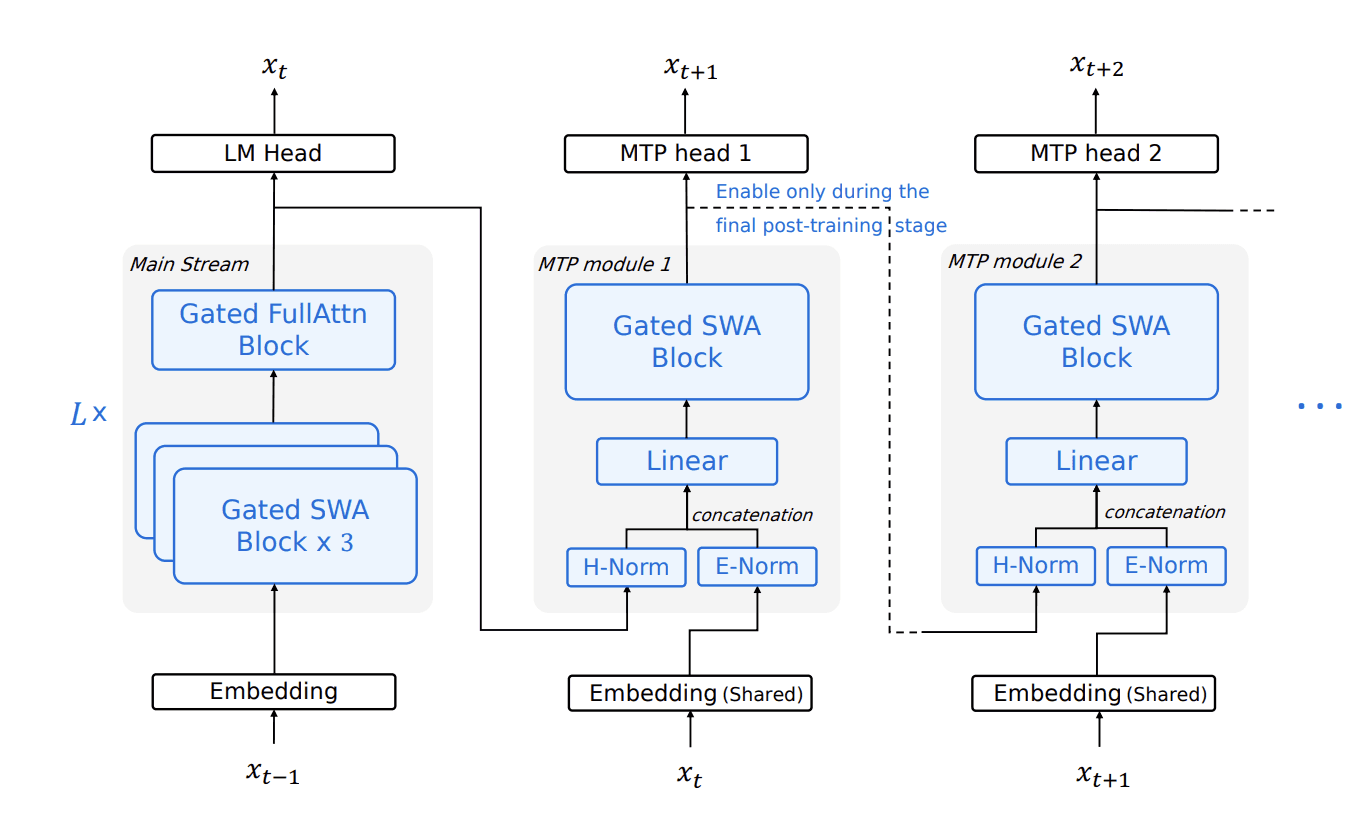
While traditional chatbots are optimized for reading, agents require reason at speed. Powered by 3-way Multi-Token Prediction (MTP-3), Step 3.5 Flash achieves a generation throughput of 100–300 tok/s in typical usage. According to official data, it reaches a peak of 350 tok/s for single-stream coding tasks on NVIDIA Hopper GPUs, enabling complex, multi-step reasoning chains with immediate responsiveness.
Efficient Long Context
Step 3.5 Flash supports a 262K context window while remaining cost-efficient, making it suitable for workloads such as massive datasets and long codebases. It achieves this through a hybrid attention design with a 3:1 Sliding Window Attention (SWA) ratio, inserting three SWA layers for every one full-attention layer. This approach maintains stable long-context performance while significantly reducing the compute overhead typically associated with standard long-context models.
SoTA Coding & Agents Performance
Built for agentic tasks, Step 3.5 Flash delivers strong performance on long-horizon benchmarks—74.4% on SWE-bench Verified and 51.0% on Terminal-Bench 2.0. These results reflect stable multi-step reasoning and tool-use ability, backed by a scalable RL framework that supports continual improvement.
Benchmark | Step 3.5 Flash | GLM-4.7 | DeepSeek V3.2 | Kimi K2.5 | Gemini 3.0 Pro | Claude Opus 4.5 | GPT-5.2 xHigh |
Reasoning | |||||||
AIME 2025 | 97.3 | 95.7 | 93.1 | 96.1 | 95.0 | 92.8 | 100.0 |
IMOAnswerBench | 85.4 | 82.0 | 78.3 | 81.8 | 83.3 | 84.8 | 86.3 |
HMMT 2025 | 96.2 | 95.3 | 91.4 | 93.3 | 96.0 | 92.3 | 98.3 |
Coding | |||||||
SWE-bench Verified | 74.4 | 73.8 | 73.1 | 76.8 | 76.2 | 80.9 | 80.0 |
Terminal-Bench 2.0 | 51.0 | 41.0 | 46.4 | 50.8 | 54.2 | 59.3 | 54.0 |
LiveCodeBench-V6 | 86.4 | 84.9 | 83.3 | 85.0 | 90.7 | 84.8 | 87.7 |
Agent | |||||||
τ²-Bench | 88.2 | 87.4 | 85.2 | 85.4 | 90.7 | 92.5 | 85.5 |
BrowseComp | 69.0 | 67.5 | 67.6 | 74.9 | 59.2 | 57.8 | 65.8 |
How it Performs in Real World
In this instance, Step-3.5-Flash is tasked via SiliconFlow's API to analyze European supply chain risks. It autonomously engineered 5 Python modules to sequentially generate 12-month synthetic shipment data (which can be fully replaced by your authentic business datasets), integrate real-time weather APIs, and calculate multi-factor risk scores.
The process concludes with an interactive dashboard and a comprehensive HTML report. Specifically, the dashboard autonomously integrates Leaflet.js for geospatial visualization and Plotly.js for interactive charts, creating a rich, multi-dimensional analytical experience without any explicit guidance in the prompt.
Prompt: Analyze european supply chain data from the past 12 months and integrate real-time weather forecasting to assess logistics risks in Europe for the upcoming month, then generate a data report for me.
What makes this possible: Step 3.5 Flash excels at orchestrating tools with flawless intent-alignment, seamlessly pivoting between code execution and API protocols—bridging internal reasoning with real-world impact. This project powerfully demonstrates its agentic coding and complex tool orchestration capabilities.
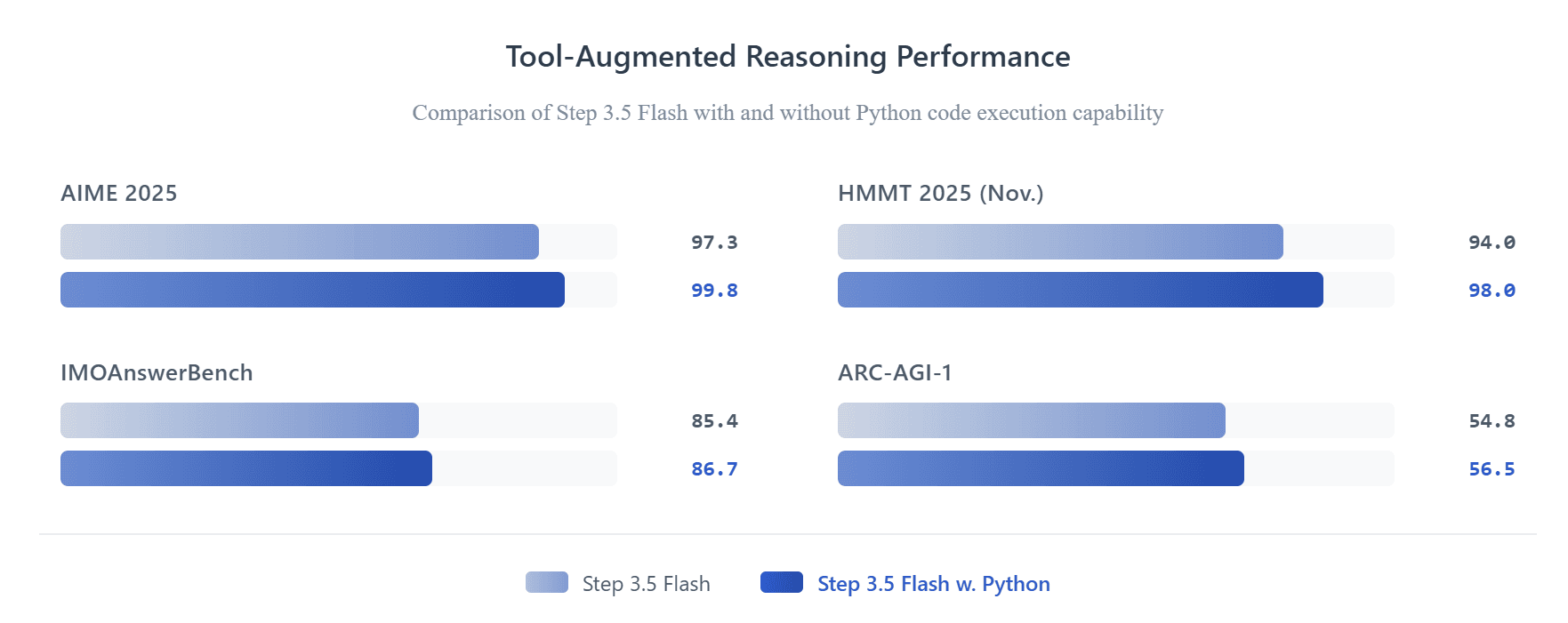
Step 3.5 Flash's superior tool-use capability is further evidenced by the performance metrics below. By integrating Python code execution within its Chain-of-Thought reasoning, the model achieves substantial performance gains across elite logic and mathematics benchmarks, including AIME 2025 (99.8), HMMT 2025 Nov. (98.0), IMOAnswerBench (86.7), and ARC-AGI-1 (56.5).
Get Started Immediately
Explore: Try Step 3.5 Flash in the SiliconFlow playground.
Integrate: Use our OpenAI-compatible API. Explore the full API specifications in the SiliconFlow API documentation.
