Qwen3-VL pada SiliconFlow: VLM Generasi Selanjutnya dengan Pemahaman Dunia yang Lebih Baik
Daftar Isi

TL;DR: Qwen3-VL — model bahasa viso yang paling kuat dalam seri Qwen — sekarang tersedia di SiliconFlow. Rilis ini menawarkan peningkatan terobosan: pemahaman & penghasilan teks yang unggul, alasan multimodal, persepsi spasial & video yang canggih, jendela konteks 262K, OCR dalam 32 bahasa, dan interaksi agen yang lebih kuat. Didukung oleh arsitektur Dense & MoE hingga 235B parameter dengan inovasi seperti Interleaved-MRoPE dan DeepStack, ini menetapkan standar baru untuk AI multimodal.
Sekarang, varian Instruct dan Thinking sudah tersedia di SiliconFlow. Mulailah membangun dengan API siap-produksi SiliconFlow hari ini!
Kami sangat senang mengumumkan bahwa seri Qwen3-VL sekarang tersedia di SiliconFlow. Sebagai model bahasa viso generasi berikutnya yang dibangun untuk lebih memahami, mengerti, dan merespon dunia, Qwen3-VL menawarkan kemampuan terobosan yang mendefinisikan ulang AI multimodal. Ini memungkinkan pemahaman video yang tepat, OCR yang diperluas dalam 32 bahasa dengan penanganan yang lebih baik untuk karakter langka dan teks historis, dan jendela konteks 262K untuk analisis konten yang sangat panjang.
SiliconFlow sekarang menawarkan kedua edisi Instruct dan Thinking: yang pertama dioptimalkan untuk eksekusi yang efisien, dan yang terakhir ditingkatkan untuk penalaran yang lebih dalam—memberikan fleksibilitas kepada pengguna untuk memilih model yang tepat untuk kebutuhan mereka.
Melalui Qwen3-VL API dari SiliconFlow, Anda dapat mengharapkan:
Harga Efektif Secara Biaya:
Qwen3-VL-30B-A3B-Instruct $0.29/M token (input) dan $1/M token (output)
Qwen3-VL-30B-A3B-Thinking $0.29/M token (input) dan $1/M token (output)
Qwen3-VL-235B-A22B-Instruct $0.3/M token (input) dan $1.5/M token (output)
Qwen3-VL-235B-A22B-Thinking $0.45/M token (input) dan $3.5/M token (output)
Jendela Konteks 262K: Memungkinkan pemrosesan dokumen panjang dan percakapan multi-belokan secara lancar.
Dengan kombinasi ini—30B vs 235B, Instruct vs Thinking—SiliconFlow memungkinkan pengembang untuk memilih keseimbangan antara efisiensi, kedalaman, dan biaya, membawa kecerdasan multimodal yang fleksibel ke produksi pada setiap skala.
Mengapa Qwen3-VL Penting
Kebanyakan model bahasa viso menghadapi dilema: kemampuan luas atau penalaran dalam, tetapi jarang keduanya. Model umum kesulitan dengan logika kompleks, model khusus kurang memiliki keserbagunaan. Melihat tidak berarti mengerti—dan mengerti tidak berarti menyelesaikan masalah.
Qwen3-VL mengatasi ini dengan pendekatan dual-edisi:
Instruct: Dioptimalkan untuk tugas bahasa viso sehari-hari yang luas dengan kinerja andal.
Thinking: Ditingkatkan dengan kemampuan penalaran canggih untuk pemecahan masalah kompleks dalam STEM dan matematika.
Bersama-sama, mereka membuka kemampuan di tiga area utama:
1. Agenik
Agen Visual: Biarkan AI menavigasi aplikasi dan situs web! Ia mengenali elemen UI, memahami fungsi mereka, dan melaksanakan tugas multi-langkah secara otomatis. Ini juga mencapai kinerja global tertinggi pada tolok ukur seperti OS World, dan penggunaan alat secara signifikan meningkatkan kinerjanya pada tugas persepsi halus.
Pemahaman Spasial yang Jauh Lebih Baik: Pemetaan 2D dari koordinat absolut ke koordinat relatif. Ini dapat menilai posisi objek, perubahan sudut pandang, dan hubungan occlusion. Ini juga mendukung dasar 3D, meletakkan dasar untuk penalaran spasial kompleks dan aplikasi AI yang terwujud.
Dari Desain ke Kode: Unggah tangkapan layar atau video, dan hasilkan diagram Draw.io siap-produksi, HTML, CSS, atau JavaScript — menjadikan pemrograman visual "apa yang Anda lihat adalah apa yang Anda dapatkan" menjadi kenyataan.

2. Persepsi & Pemahaman
Pemahaman Konteks Panjang & Video Panjang: Semua model mendukung jendela konteks 262K, dapat diperluas hingga 1 juta token. Ini berarti Anda dapat memasukkan ratusan halaman dokumen teknis, seluruh buku pelajaran, dan bahkan video berdurasi jam — dan model akan mengingat semuanya dan mengambil detail secara akurat.
OCR yang Diperluas: Dukungan untuk 32 bahasa, kinerja yang kuat dengan gambar buram/miring/cahaya rendah, penanganan yang lebih baik untuk karakter langka, teks kuno, dan jargon teknis, ditambah pemrosesan struktur yang ditingkatkan untuk dokumen panjang.
Persepsi & Pengakuan Visual yang Ditingkatkan: Dengan memperbaiki kualitas dan keragaman data pra-pelatihan, model sekarang dapat mengenali rentang objek yang jauh lebih luas — mulai dari selebriti, karakter anime, produk, dan landmark, hingga hewan dan tumbuhan — meliputi kebutuhan "mengenali apa pun" dalam kehidupan sehari-hari dan profesional.
3. Matematika & Bahasa
Penalaran Multimodal yang Lebih Kuat (Versi Thinking): Model Thinking secara khusus dioptimalkan untuk penalaran STEM dan matematika. Ketika menghadapi pertanyaan subjek yang kompleks, itu dapat memperhatikan detail halus, memecahkan masalah langkah demi langkah, menganalisis hubungan sebab akibat, dan memberikan jawaban yang logis dan berbasis bukti. Itu mencapai kinerja kuat pada tolok ukur penalaran seperti MathVision, MMMU, dan MathVista.
Performa Berbasis Teks yang Unggul: Qwen3-VL menggunakan prapelatihan bersama tahap awal dari modalitas teks dan visual, secara terus menerus memperkuat kapabilitas bahasa. Kinerjanya pada tugas berbasis teks sebanding dengan Qwen3-235B-A22B-2507 — model bahasa unggulan — menjadikannya benar-benar sebuah "kekuatan multimodal berbasis teks" untuk generasi berikutnya dari model bahasa viso.

Kinerja Penilaian & Pembaruan Arsitektur Teknis
Qwen3-VL tidak hanya menunjukkan keterampilan bahasa viso yang luas tetapi juga memberikan kinerja mutakhir di antara evaluasi multimodal dan murni teks.
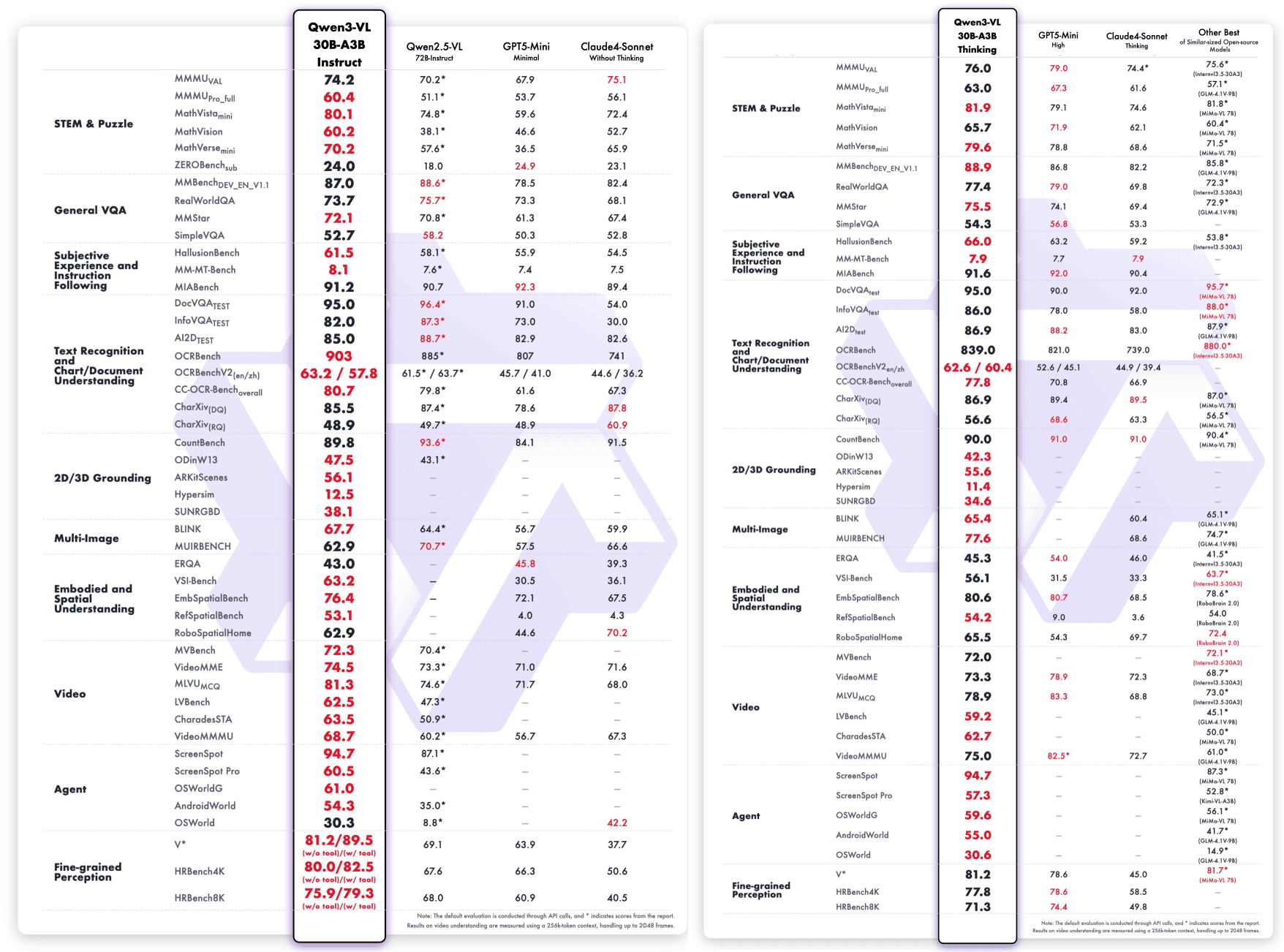
Qwen3-VL-235B-A22B-Instruct & Qwen3-VL-235B-A22B-Thinking:
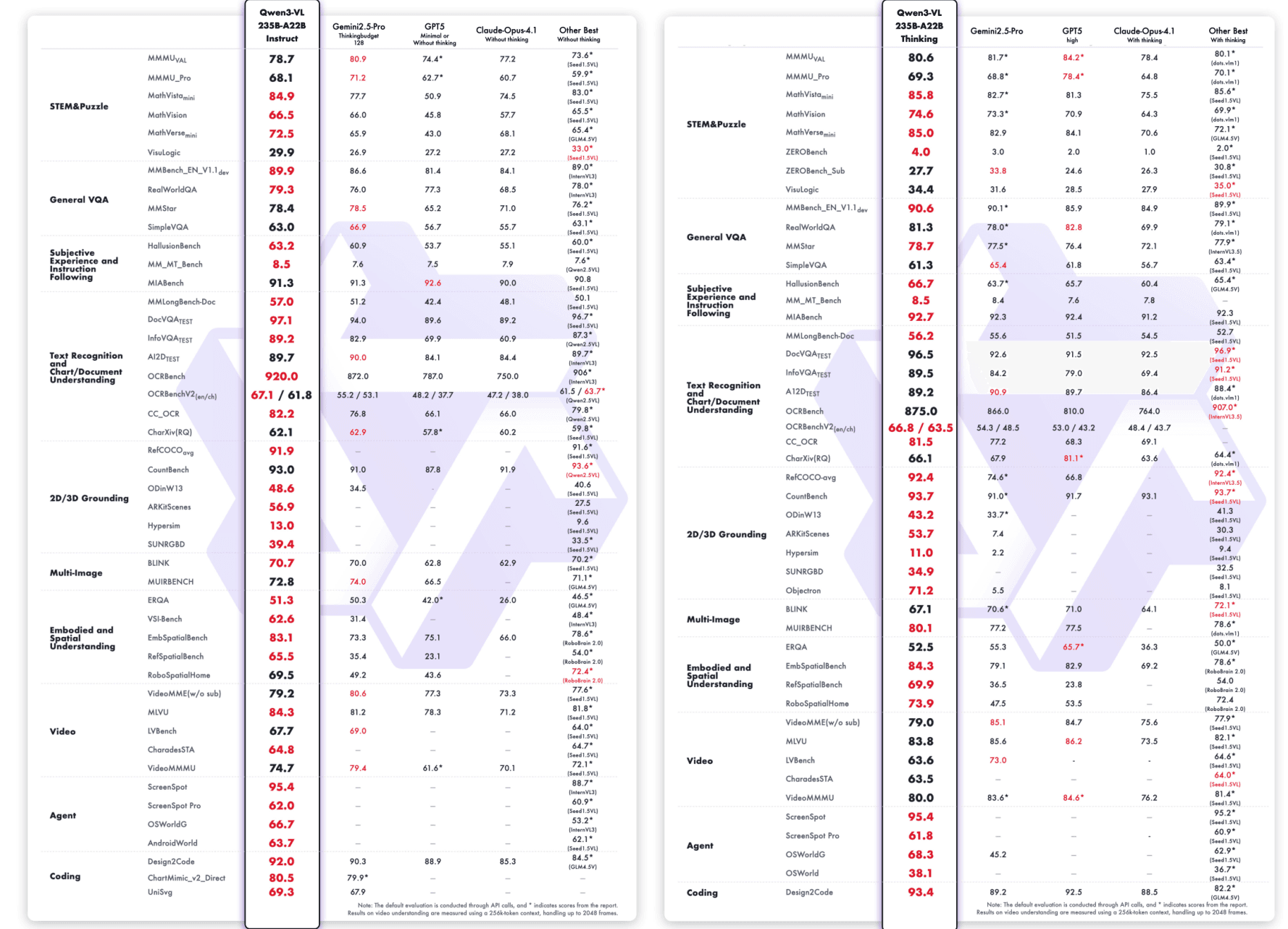
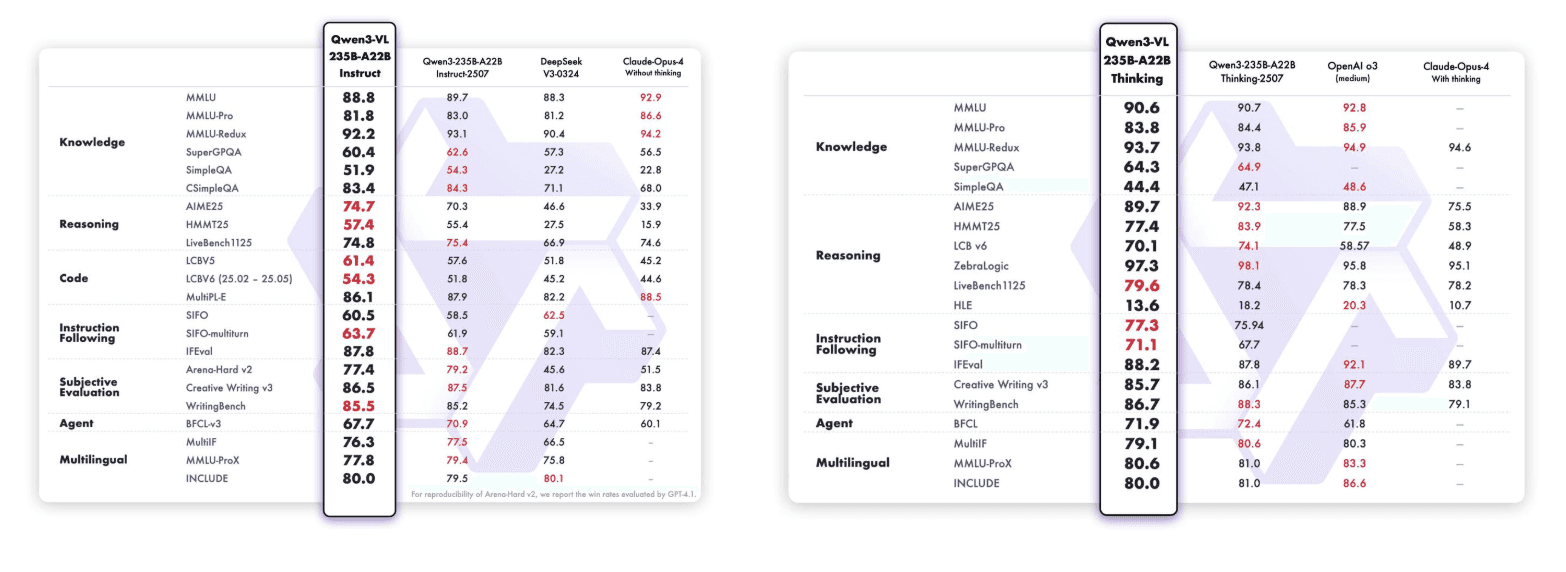
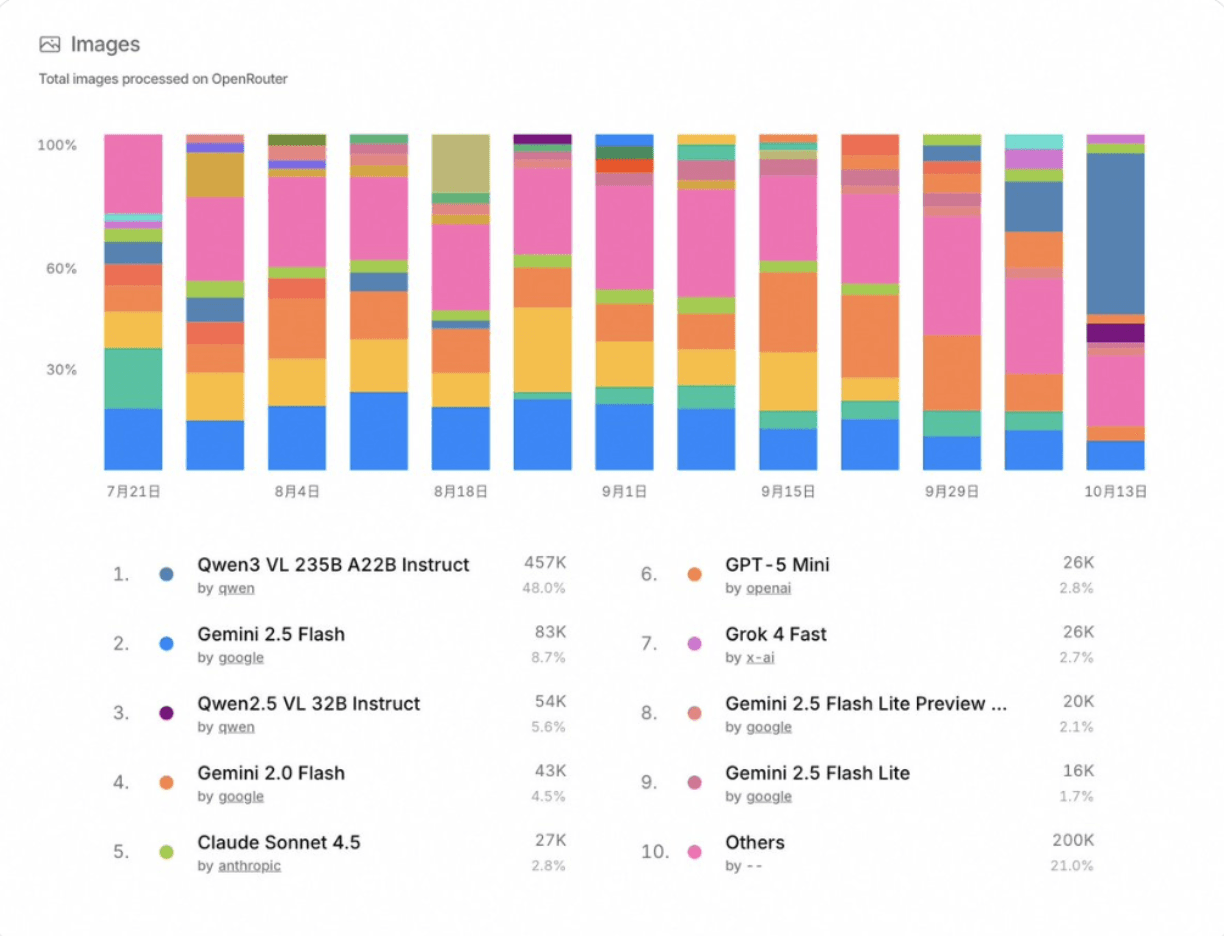
Di luar kinerja tolok ukur, Qwen3-VL-235B-A22B-Instruct juga mencapai daya tarik luar biasa di komunitas sumber terbuka. Menurut statistik terbaru dari OpenRouter (Oktober 2025), ini menempati peringkat #1 untuk pemrosesan gambar dengan pangsa pasar 48%, melampaui model multimodal terkemuka lainnya seperti Gemini 2.5 Flash dan Claude Sonnet 4.5.
Perlu dicatat, SiliconFlow juga berperan sebagai penyedia di OpenRouter, menawarkan Qwen3-VL-235B-A22B-Instruct bersamaan dengan model terkemuka lainnya seperti DeepSeek-V3.2-Exp, GLM-4.6, Kimi K2-0905, dan GPT-OSS-120B, memberikan akses terpadu kepada pengembang untuk berbagai model mutakhir.
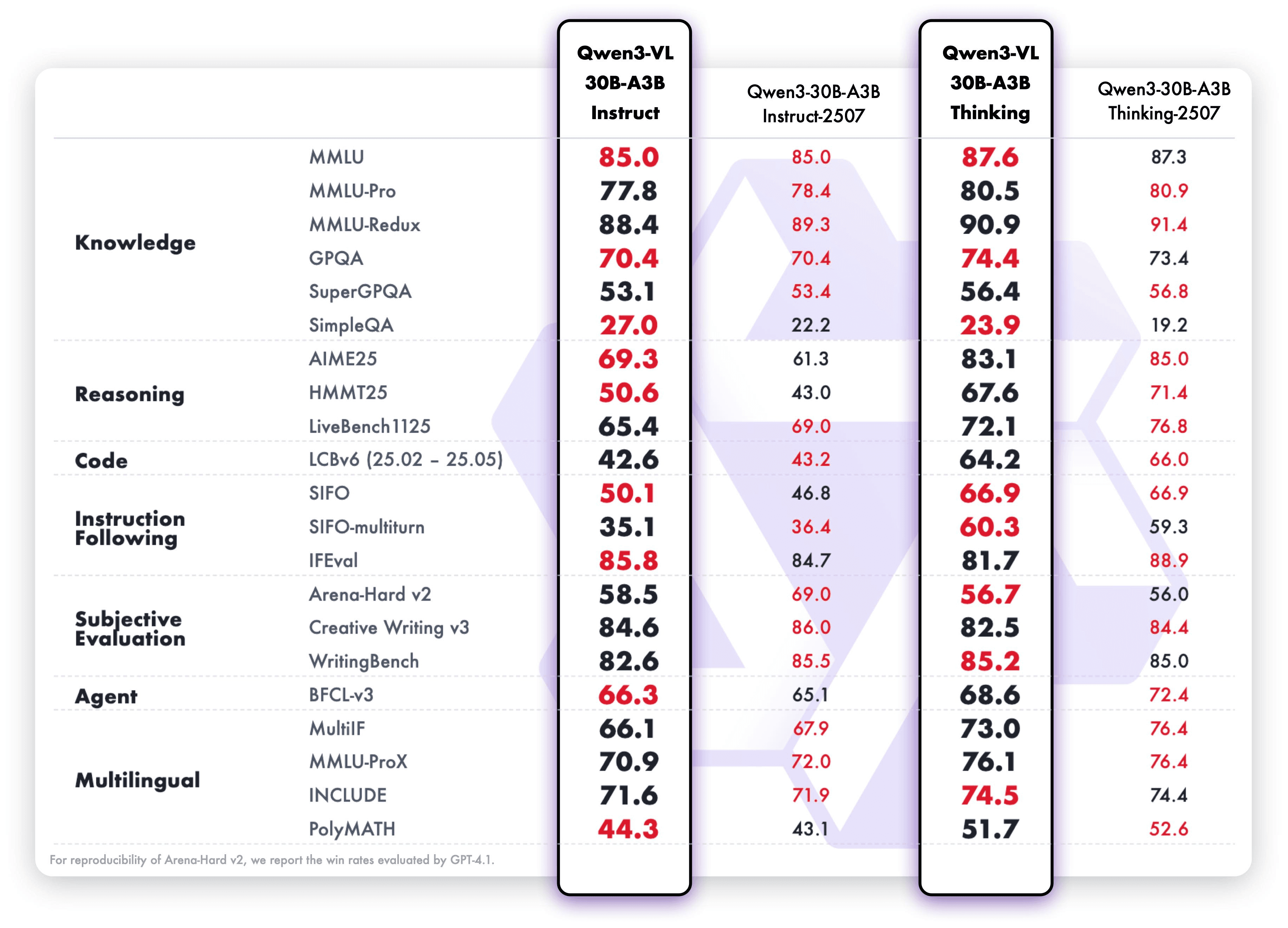
Qwen3-VL-30B-A3B-Instruct & Qwen3-VL-30B-A3B-Thinking:
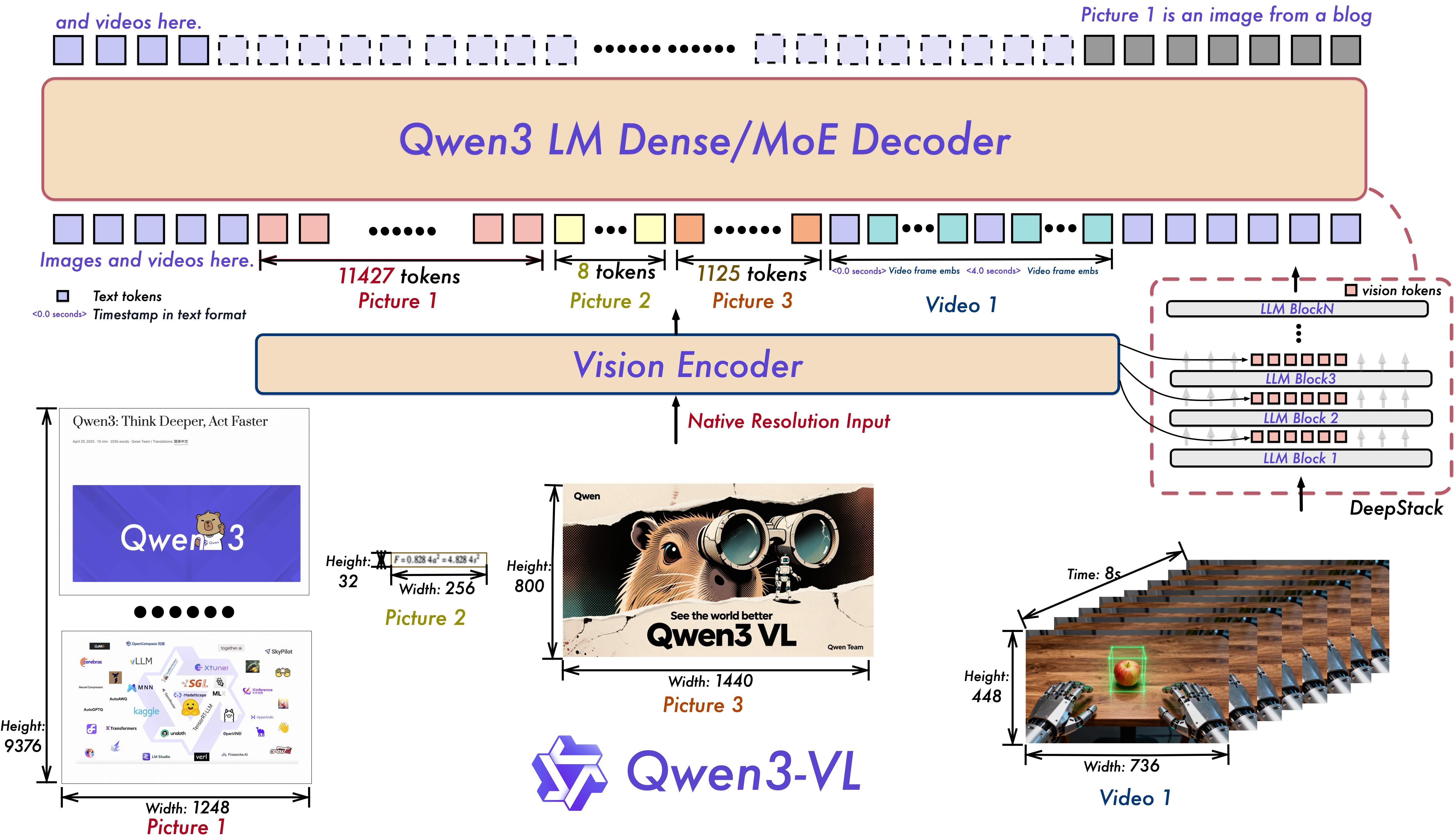
Inovasi Arsitektur
Tiga terobosan inti memacu kemampuan Qwen3-VL:
Interleaved-MRoPE: Alokasi frekuensi penuh sepanjang waktu, lebar, dan tinggi melalui penyematan posisi yang kuat, meningkatkan alasan video jangka panjang.
DeepStack: Menggabungkan fitur ViT multi-level untuk menangkap detail halus dan mempertajam penyesuaian gambar–teks.
Penyelarasan Teks–Stempel Waktu: Bergerak melampaui T-RoPE ke lokasi peristiwa yang berlandaskan stempel waktu, dengan model temporal video yang lebih kuat.
Skenario Aplikasi Dunia Nyata
Analisis & Pengindeksan Konten Video Memproses jam video dengan pemahaman frame-accurate—tanya "Apa yang terjadi pada menit ke-15?" atau "Ringkaskan topik utama yang dibahas oleh pembicara dalam warna merah." Ideal untuk perusahaan media, platform edukasi, dan moderasi konten yang membutuhkan analisis bentuk panjang yang efisien.
Pemrosesan Dokumen Cerdas Mengekstrak informasi terstruktur dari dokumen kompleks dalam 32 bahasa—termasuk arsip sejarah, manual teknis, dan pemindaian buram. Tangani seluruh buku (hingga 1M token) untuk penelitian hukum, analisis akademis, atau manajemen pengetahuan perusahaan.
Pengembangan Tanpa Kode & Otomasi UI Unggah mockup desain untuk menghasilkan kode siap-produksi, atau biarkan Agen Visual menavigasi aplikasi secara otomatis—mengisi formulir, menguji alur kerja, dan mengeksekusi tugas multi-langkah. Mempercepat pembuatan prototipe, otomasi QA, dan mengurangi waktu pengkodean manual.
Pendidikan & Penelitian STEM Menganalisis diagram ilmiah dan persamaan matematika dengan penalaran langkah-demi-langkah. Edisi Thinking memecahkan masalah kompleks, menjelaskan hubungan sebab akibat, dan memberikan jawaban berbasis bukti untuk siswa, peneliti, dan pendidik.
Mulai Sekarang
1. Jelajahi: Coba seri Qwen3-VL di playground SiliconFlow.
2. Integrasikan: Gunakan API kami yang kompatibel dengan OpenAI. Jelajahi spesifikasi lengkap API di dokumentasi API SiliconFlow.
Baik Anda sedang membangun agen multimodal, mengotomatisasi workflow UI, atau menganalisis jam-jam video, Qwen3-VL memberi Anda kekuatan untuk melihat, memahami, dan beralasan.
Mulai segera dengan API siap-produksi SiliconFlow dan bawa kecerdasan visual ke alur kerja Anda hari ini!
Pertanyaan Bisnis atau Penjualan →
Bergabunglah dengan komunitas Discord kami sekarang →
Ikuti kami di X untuk pembaruan terbaru →
Jelajahi semua model yang tersedia di SiliconFlow →
