Ling-1T Sekarang Tersedia di SiliconFlow: Lompatan Skala Triliun dalam Penalaran Efisien
Daftar Isi

TL;DR: Ling-1T, model tanpa-berpikir unggulan pertama dalam seri Ling 2.0, sekarang tersedia di SiliconFlow. Dibangun untuk penalaran yang efisien pada skala triliun, mempersembahkan total 1 triliun parameter dengan sekitar 50 miliar aktif per token dan pelatihan Evo-CoT untuk penalaran yang lebih mendalam dan cepat. Memberikan kinerja mutakhir di seluruh tugas matematika, kode, dan front-end, Ling-1T mendefinisikan ulang keseimbangan antara akurasi, kecepatan, dan efisiensi biaya.
Mulailah membangun hari ini dengan API siap-produksi SiliconFlow, sepenuhnya kompatibel dengan OpenAI/Anthropic dan siap untuk diintegrasikan ke dalam alur kerja Anda yang sudah ada!
Hari ini, kami meluncurkan Ling-1T di SiliconFlow — model tanpa-berpikir unggulan pertama dalam seri Ling 2.0. Dibangun dengan 1 triliun parameter dan ~50 miliar aktif per token, dioptimalkan untuk penalaran yang efisien di seluruh tugas yang kompleks. Model ini juga unggul dalam mengubah deskripsi bahasa alami yang kompleks menjadi kode yang dapat dieksekusi, menyelesaikan masalah matematika tingkat kompetisi, dan menghasilkan antarmuka front-end yang menyeimbangkan estetika dan fungsionalitas. Yang lebih penting, mencapai akurasi yang lebih tinggi dengan rantai penalaran yang lebih pendek, yang berarti respon lebih cepat, biaya lebih rendah, dan output lebih andal.
Dengan API Ling-1T SiliconFlow, Anda dapat mengharapkan:
Harga Kompetitif: Ling-1T $0.57/M token (input) dan $2.28/M token (output).
Jendela Konteks Diperpanjang: Jendela konteks 131K memungkinkan Anda memproses dokumen yang lebih panjang dan menjaga konteks di seluruh tugas yang kompleks.
Arsitektur MoE Efisien: 1 triliun total parameter dengan ~50 miliar parameter aktif per token, memberikan penalaran yang kuat tanpa beban komputasi dari model padat sepenuhnya.
Optimasi Evo-CoT: Dilatih sebelumnya pada lebih dari 20 triliun token berkualitas tinggi dan padat penalaran dengan proses chain-of-thought evolusioner (Evo-CoT) yang meningkatkan penyelesaian masalah multi-langkah.
Fitur Utama & Kinerja Tolok Ukur
Penalaran adalah landasan dari kecerdasan. Ling-1T mendorong ini lebih jauh dengan mengombinasikan penalaran efisien dengan generasi kreatif, unggul di dua dimensi utama:
Pemahaman Estetika & Generasi Front-End
Ubah ide menjadi kode front-end elegan: Ling-1T menginterpretasikan maksud UI dan menerjemahkan bahasa alami ke dalam antarmuka yang bersih dan fungsional.
Kode yang terlihat sebagus jalannya: Sistem penghargaan hibrid Sintaks–Fungsi–Estetika memastikan setiap baris kode menyeimbangkan kebenaran, kegunaan, dan daya tarik visual.
Berperingkat #1 di ArtifactsBench: Ling-1T unggul dalam generasi front-end. Gulir ke bawah untuk melihat demo yang dibuat melalui API SiliconFlow.
Kecerdasan Emergen pada Skala Triliun
Skala dengan kecerdasan: Mengungkap kemampuan penalaran emergen dan transfer pada skala triliun, mencapai akurasi panggilan alat ~70% pada BFCL V3 dengan penyetelan minimal.
Memahami maksud Anda: Menginterpretasikan instruksi bahasa alami yang kompleks secara akurat, menyelaraskan maksud dengan penalaran untuk menghasilkan respon yang andal dan berorientasi pada tujuan.
Menjembatani logika dan desain: Mengubah ide abstrak atau langkah penalaran menjadi komponen visual yang fungsional, membantu Anda membuat prototipe lebih cepat dengan logika yang lebih bersih.
Bangun di semua platform: Menghasilkan kode front-end yang responsif dan lintas platform yang siap digunakan dengan penyesuaian minimal.
Menulis dengan gaya dan konteks: Menghasilkan salinan pemasaran dan teks multibahasa yang sesuai dengan nada, audiens, dan identitas merek Anda.
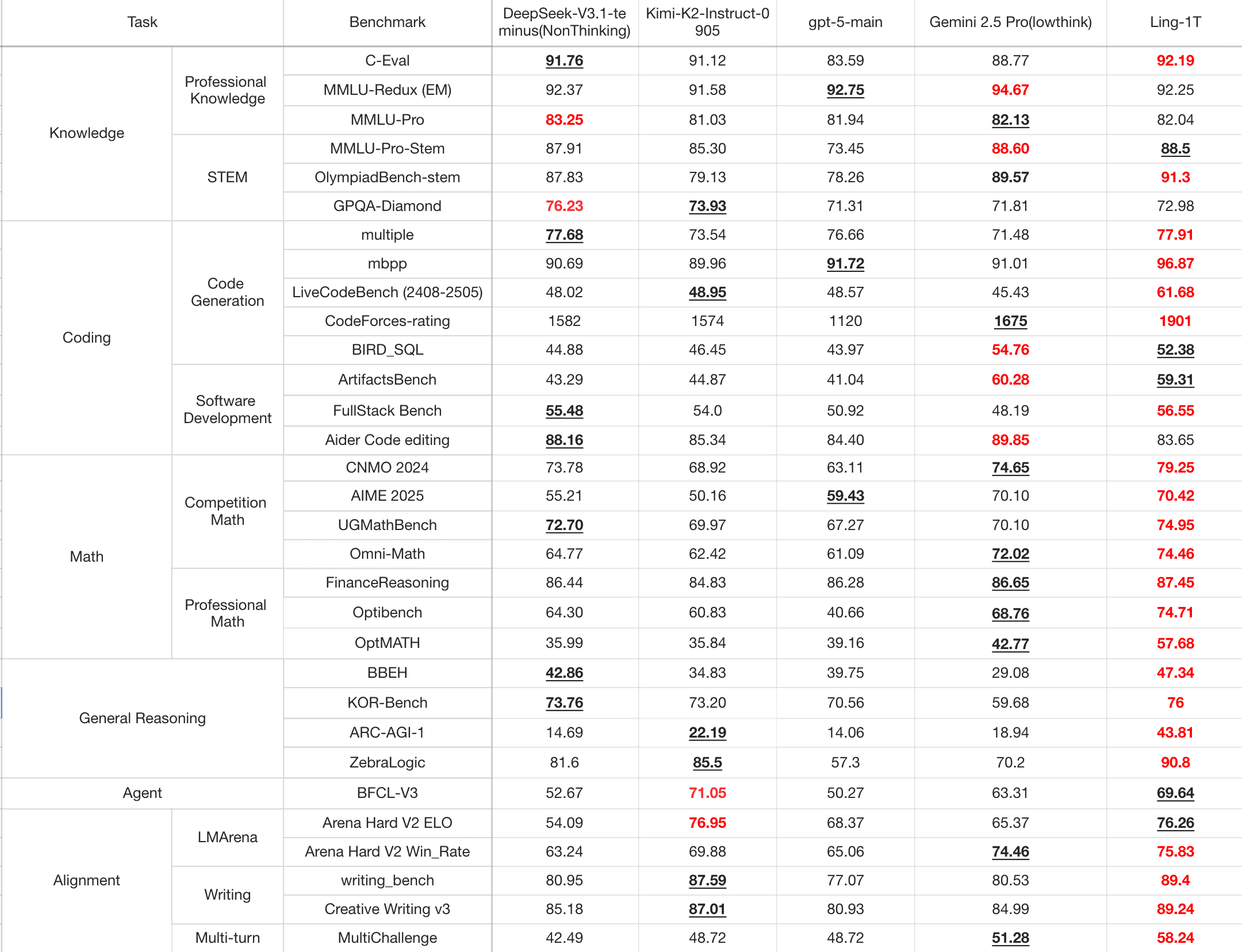
Untuk memastikan evaluasi yang adil dan komprehensif, Ling-1T juga dibenchmark terhadap model unggulan open-source dan closed-source — termasuk DeepSeek-V3.1-Terminus, Kimi-K2-Instruct-0905, GPT-5-main, dan Gemini-2.5-Pro.
Di seluruh generasi kode, pengembangan perangkat lunak, matematika tingkat kompetisi, matematika profesional, dan pemikiran logis, Ling-1T secara konsisten memberikan kinerja penalaran kompleks yang unggul dan menunjukkan keunggulan menyeluruh dibandingkan model terkemuka tersebut.
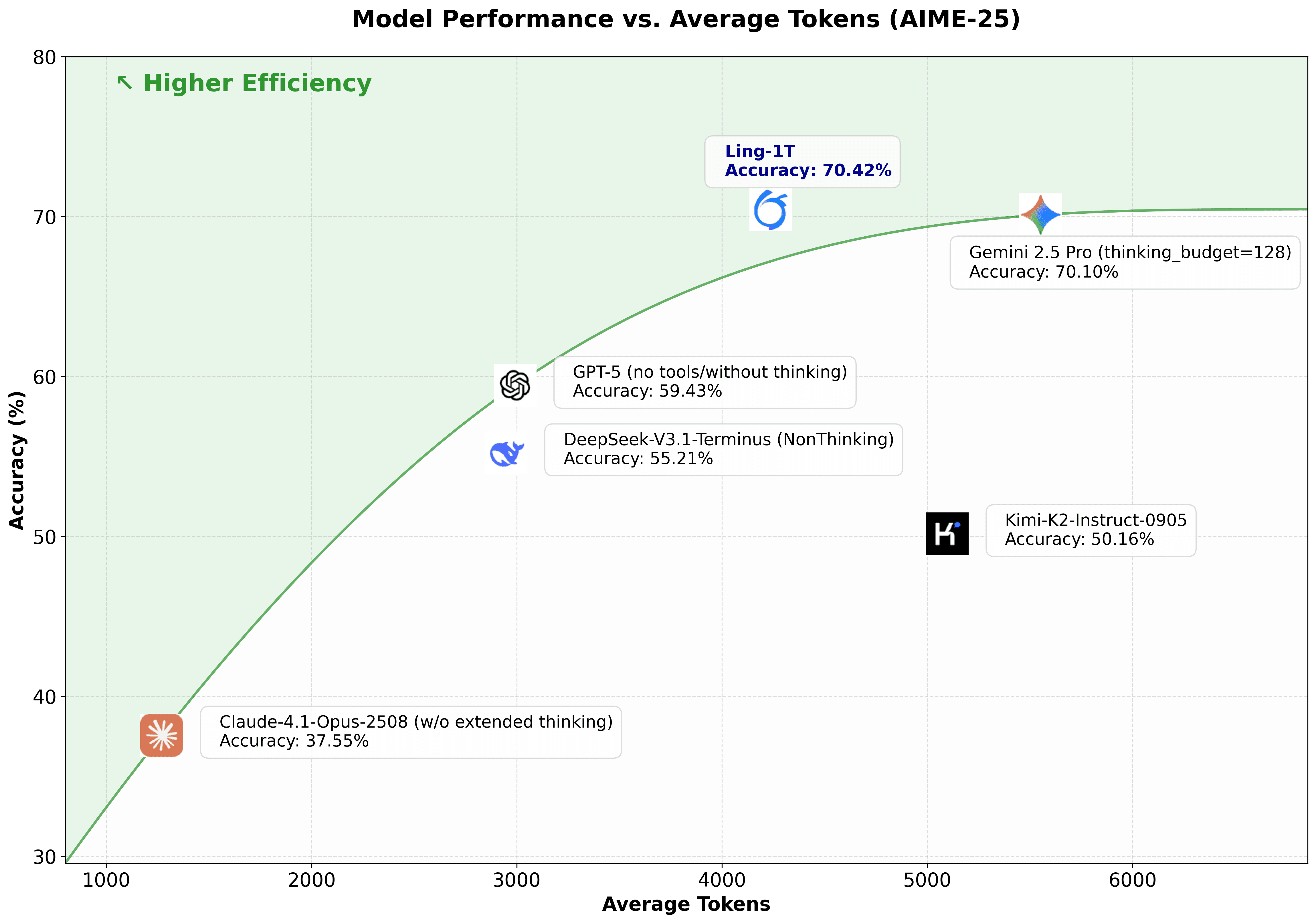
Pada tolok ukur AIME 25, Ling-1T memperluas batas Pareto dari akurasi penalaran vs. panjang penalaran, mencapai akurasi yang lebih tinggi dengan langkah penalaran yang lebih sedikit.
Bagi pengembang yang bekerja pada penalaran kompleks, analisis matematika, atau masalah multi-langkah, ini berarti hasil yang lebih cepat dengan presisi yang lebih tinggi.
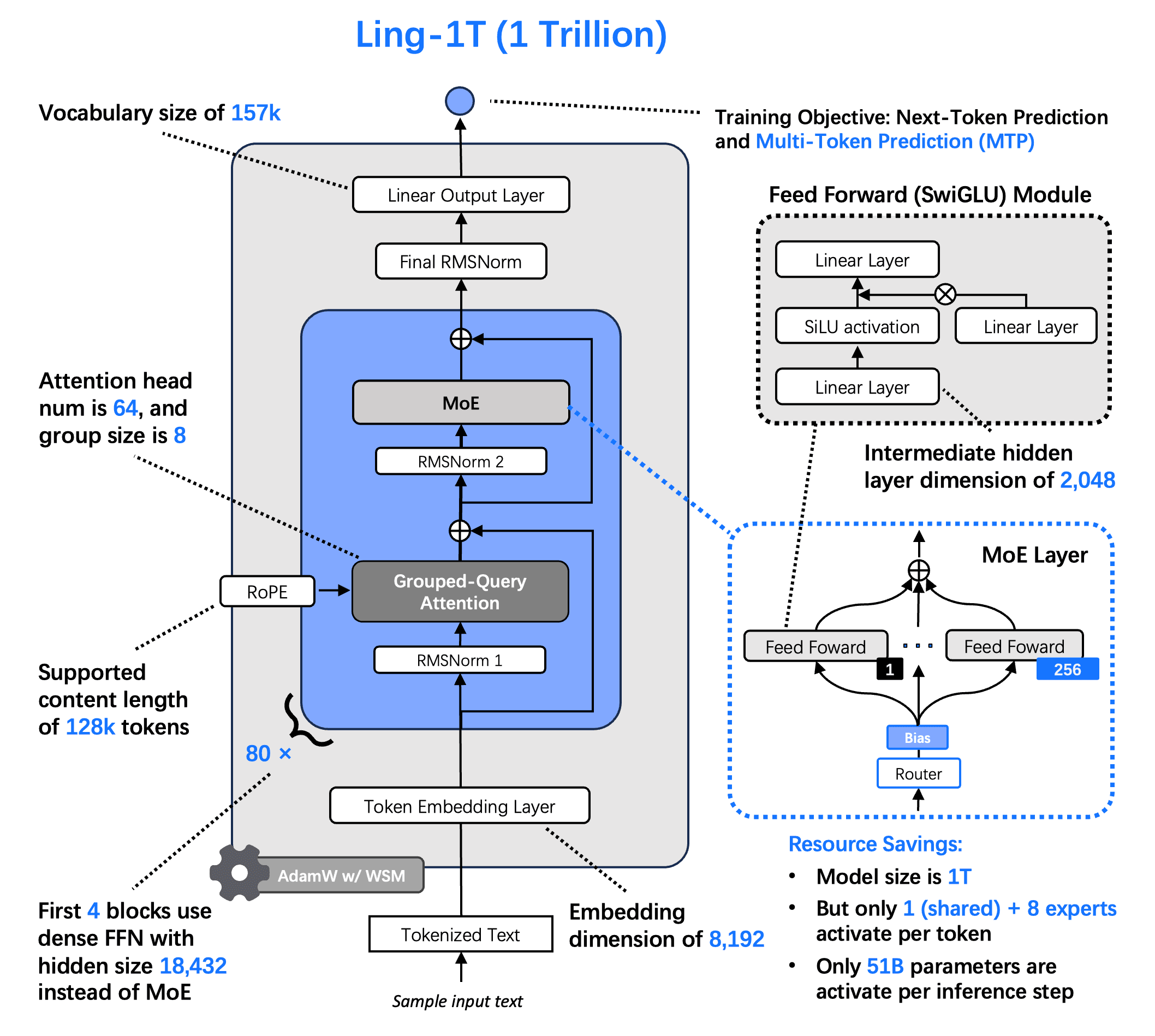
Arsitektur Model & Pelatihan
Inovasi arsitektur kunci:
Dibangun pada arsitektur Ling 2.0 dan dipandu oleh Hukum Penskalaan Ling, Ling-1T dirancang dari awal untuk efisiensi skala triliun, memastikan kinerja penalaran yang stabil pada skala apa pun:
1T total / 50B aktif parameter dengan rasio aktivasi 1/32 MoE
Lapisan MTP untuk penalaran komposisional yang lebih baik
Tanpa kerugian tambahan, pengarahan pakar dengan skor sigmoid dengan pembaruan rata-rata nol
Normalisasi QK untuk konvergensi yang sepenuhnya stabil
Efisiensi Pelatihan:
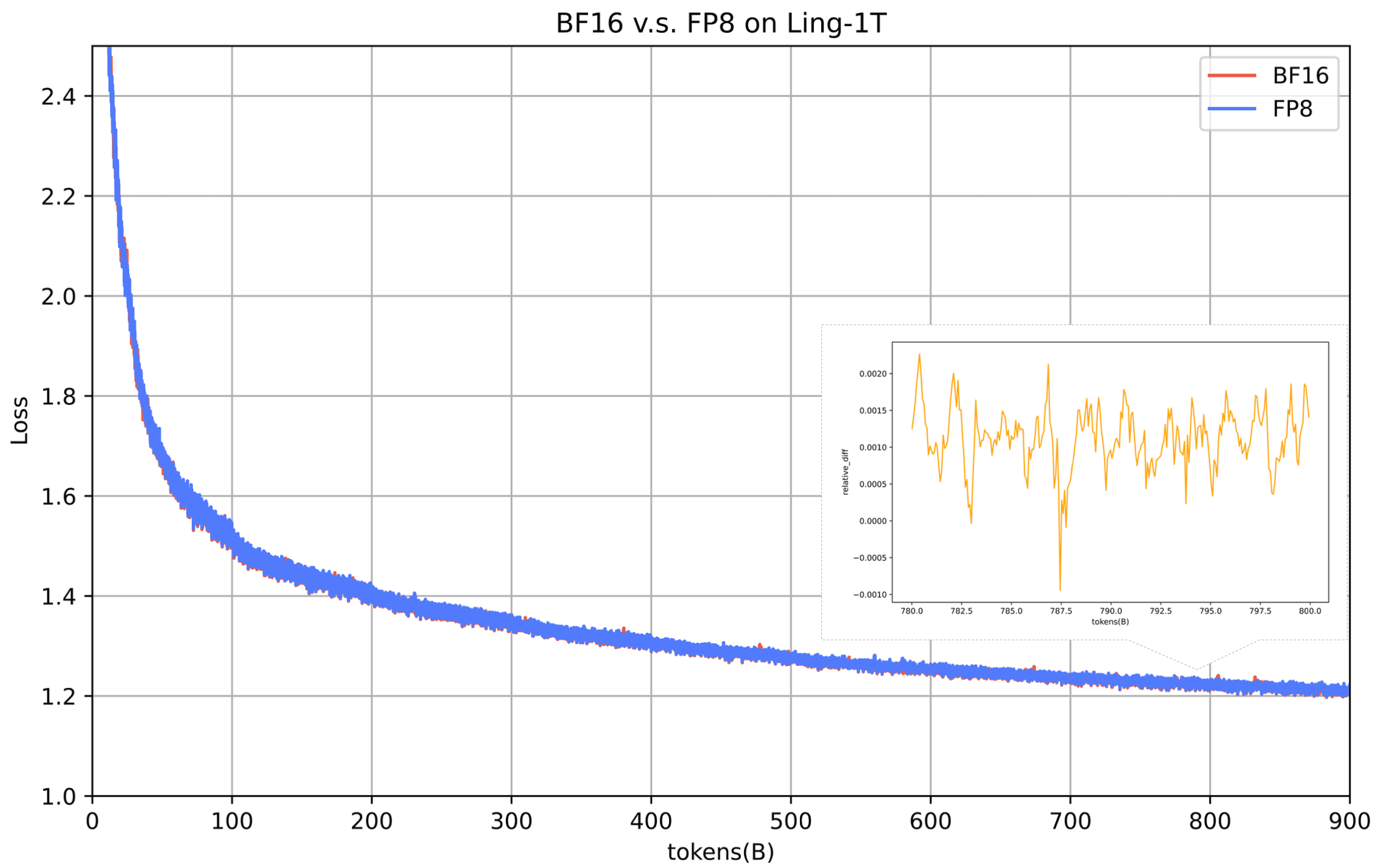
Ling-1T memanfaatkan pelatihan presisi campuran FP8, menjadikannya model fondasi terbesar yang diketahui dilatih dengan cara ini. Dikombinasikan dengan optimasi pipeline heterogen dan penjadwal tingkat pembelajaran WSM, pelatihan mencapai lebih dari 40% percepatan ujung-ke-ujung sambil mempertahankan stabilitas pada skala triliun.
Pelatihan Pra:
Pra-dilatih pada lebih dari 20 triliun token berkualitas tinggi, dengan lebih dari 40% didedikasikan untuk data yang padat penalaran. Fondasi ini memberi kekuatan alami Ling-1T dalam logika, penyelesaian masalah multi-langkah, dan analisis kompleks.
Untuk lebih meningkatkan kemampuan ini, data chain-of-thought yang dikurasi diintegrasikan selama pelatihan menengah, meningkatkan stabilitas penalaran dan generalisasi.
Pelatihan Pasca:
Ling-1T terus menyempurnakan kemampuannya untuk bernalar melalui optimasi canggih:
Evo-CoT (Evolutionary Chain-of-Thought): Secara progresif meningkatkan presisi dan efisiensi penalaran, memungkinkan pemikiran yang lebih logis dengan langkah-langkah perhitungan yang lebih sedikit.
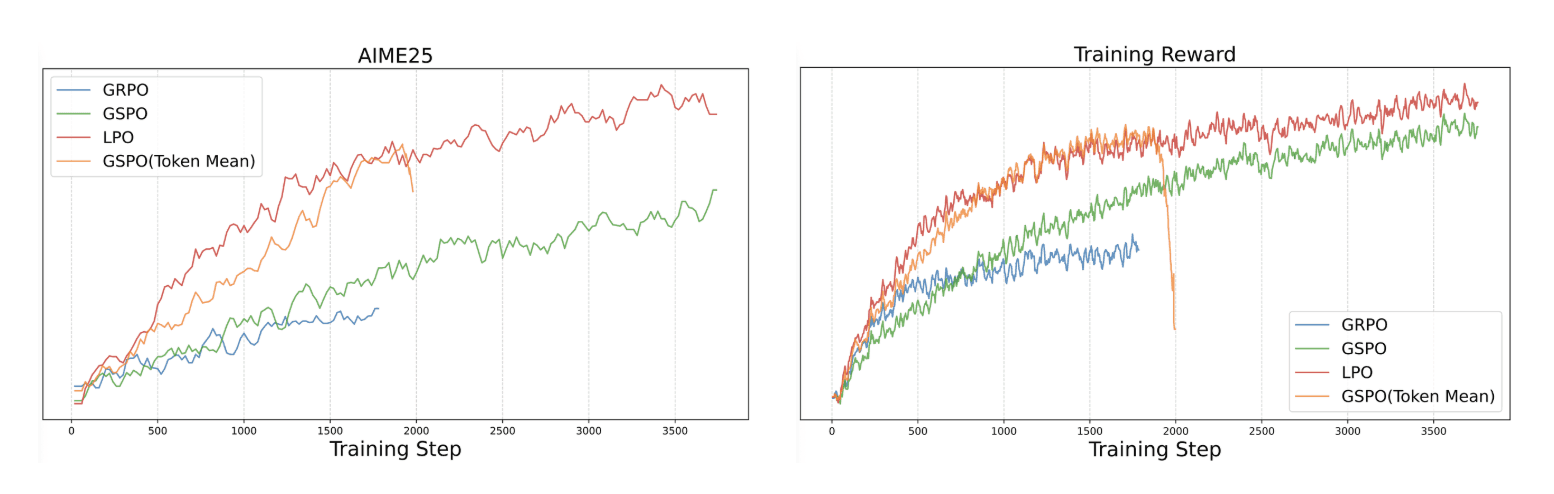
LPO (Pengoptimalan Kebijakan Unit Linguistik): Mengoptimalkan pembelajaran pada tingkat kalimat, menyelaraskan penghargaan dengan makna bahasa alami daripada urutan token.
Mulai Segera
1. Jelajahi: Coba Ling-1T di SiliconFlow Playground.
2. Integrasikan: Gunakan API kompatibel kami dengan OpenAI. Jelajahi spesifikasi lengkap API di dokumentasi API SiliconFlow.
Mulai membangun dengan Ling-1T hari ini melalui API siap-produksi SiliconFlow — menghadirkan penalaran skala triliun dengan efisiensi dan keandalan.
Inkuiri Bisnis atau Penjualan →
Bergabunglah dengan komunitas Discord kami sekarang →
