目录

Step3,Stepfun最新的尖端Multimodal推理模型现已在SiliconFlow上可用。基于一个规模庞大的MoE架构,总参数达到321B,活跃参数为38B,该模型在Vision-语言推理中提供了卓越的性能。它为企业和开发者的需求提供了优化的解码效率,实现了可靠的Multimodal推理,具有准确的视觉解读和减少的幻觉。
使用SiliconFlow的Step3 API,您可以期待:
经济实惠的价格:Step3 $0.57/M tokens (Input) 和 $1.42/M tokens (Output)。
上下文长度:支持64K上下文长度。
本地支持工具使用/函数调用。
关键能力与基准性能
Step3具有强大的视觉感知和高级推理能力,能够准确理解跨领域、多模态数学推理和现实世界的视觉理解任务。
这些能力通过跨行业标准基准的出色表现得以展示,突显了其在需要视觉理解和推理的任务中的有效性:
VLM基准性能:Step3在开源VLM模型中实现了最高的MMMU分数(74.2),超越了Gemini 2.5 Flash(73.2)等专属性VLM;在Hallusion Bench中取得64.2的成绩,表现优于包括Claude Opus 4(59.9)、Claude Sonnet 4(57.0)和o3(60.1)在内的领先专属模型,展示了Step3在复杂视觉推理、真实性和跨领域理解中的卓越表现。
LLM基准性能:Step3在AIME25中保持82.9,在GPQA-Diamond中保持73.0,在LiveCodeBench中保持67.1,展示了强大的数学推理、顶级毕业生级别推理和代码生成能力。
除了顶级性能外,Step3还具有较低的成本——使其成为您的负担得起的工作负载选择。

技术亮点
Step3通过模型架构设计、训练管道和部署的全栈优化解决了Multimodal对齐、解码成本和推理效率的关键挑战:
预训练模型架构:Step3采用了一种新颖的多矩阵分解注意力(MFA)机制,减少了KV缓存开销和计算成本,同时保持模型能力和推理效率。
Multimodal能力:
Step3使用5BVision编码器,带有双层2D卷积降采样,将视觉tokens减少到原始大小的1/16,以提高效率;
训练采用两阶段方法:首先增强编码器感知,然后冻结Vision编码器以优化主干和连接层。
AFD系统架构:Step3实现了注意力-FFN解耦(AFD),将计算任务分解为专用子系统,具有多阶段管线调度,有效提高整体吞吐效率。
在SiliconFlow上的实际表现
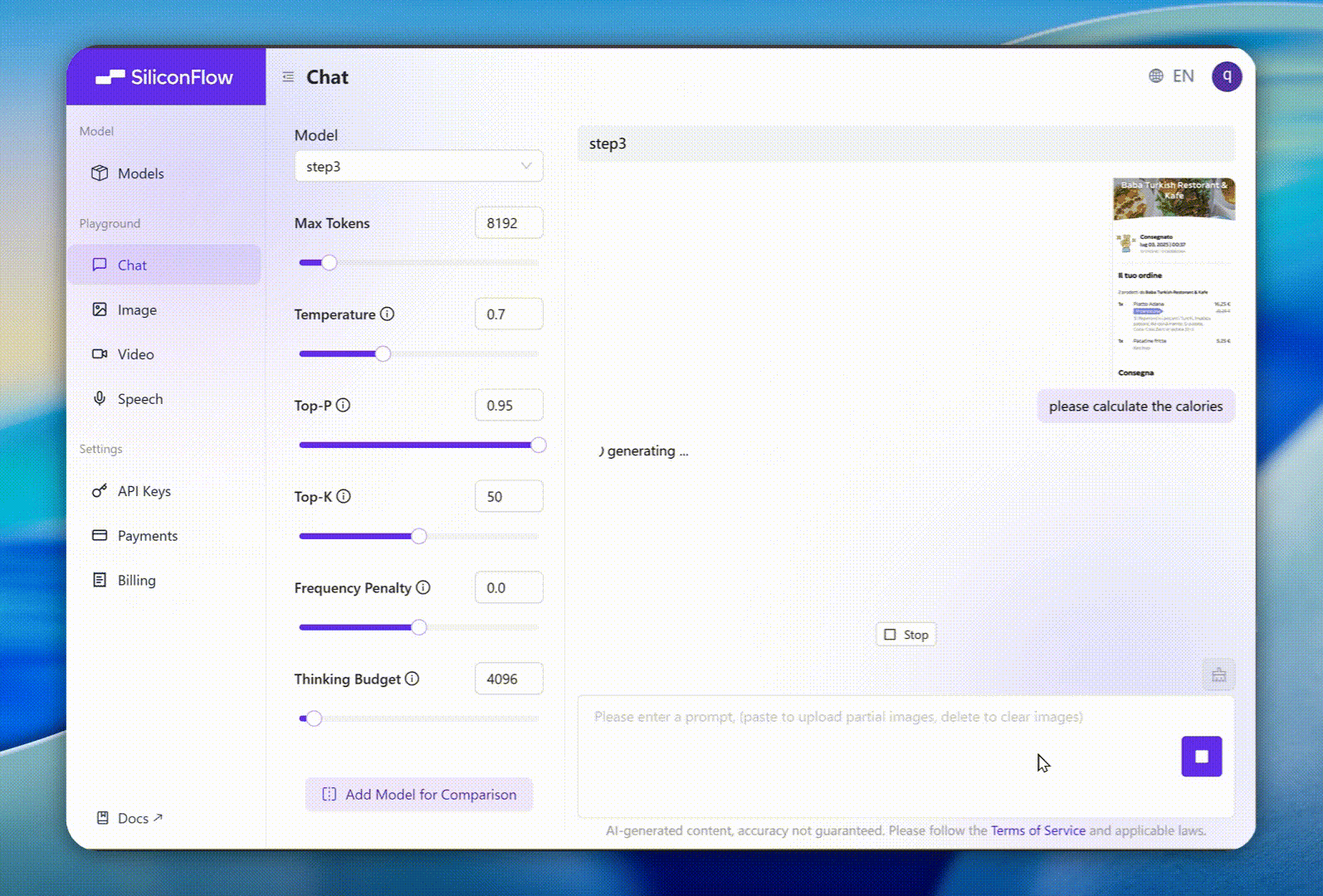
上传餐厅小票到SiliconFlow上的Step3以计算餐点的卡路里。它准确识别食物项目,解析复杂描述,分类菜肴,将其与卡路里值匹配,并估算总卡路里(例如,900-1330千卡)。
这个过程形成了一个完整的闭环——从原始数据到概念识别、计算,最后解释——在每个阶段都有清晰一致的逻辑。
立即开始
探索:在Step3的SiliconFlow 模型广场中尝试。
集成:使用我们的OpenAI兼容API。在SiliconFlow API文档中探索完整的API规格。
解锁Visual AI的力量!立即在SiliconFlow上尝试Step3!
