目录

Qwen刚刚发布了Qwen3-235B-A22B-Instruct-2507,这是其旗舰模型Qwen3-235B-A22B Non-thinking的升级版本。这标志着开源领域的重大进步,带来了增强的通用能力和卓越的推理性能,现已在SiliconFlow上可用。
这一尖端模型在指令跟随、逻辑推理、数学、编码和工具使用方面提供了显著的改进。根据综合基准测试,它优于领先的开源模型,如Kimi-K2和DeepSeek-V3-0324,以及专有模型如Claude-Opus4-Non-thinking。无论您是在构建企业应用、进行高级研究、创建多语言内容还是开发智能助手,这个模型都能以卓越的性能处理这些任务。
使用SiliconFlow的Qwen3-235B-A22B-Instruct-2507 API,您可以期待:
高速推理:优化以降低延迟和提高吞吐量。
具有成本效益的定价: $0.35/百万tokens(Input),$1.42/百万tokens(Output)。
扩展的上下文窗口:适用于复杂任务的256K上下文窗口。
增强能力&卓越性能
更新后的Qwen3-235B-A22B-Instruct-2507现在在SiliconFlow中提供,具有以下关键增强功能:
增强的通用能力:改进的指令跟随、逻辑推理、Text理解、数学、科学、编码和工具使用。
更好的用户对齐:在主观和开放式任务中与用户偏好更精确对齐,提供更有帮助和更高质量的响应。
扩展的多语言知识:在多种语言中长尾知识覆盖方面取得显著进展,包括专业、特定领域和不常见的信息。
扩展的上下文理解:具有256K长上下文理解能力。
在综合基准评估中,这些能力得到明确展示,Qwen3始终优于领先竞争对手:
高级科学推理:在GPQA中得分77.5,优于Kimi K2(75.1)和Claude Opus 4 Non-thinking(74.9),在研究生水平的科学推理和复杂问题解决能力方面表现出色。
数学问题解决:在AIME25中得分70.3,显著领先于Kimi K2(49.5)和DeepSeek-V3-0324(46.6),证明了高级竞赛数学技能。
实际编码性能:在LiveCodeBench v6中得分51.8,超过Kimi K2(48.9)和DeepSeek-V3-0324(45.2),验证了在实际场景中的强大编程能力。
出色的对话性能:在Arena-Hard v2中得分79.2,优于DeepSeek-V3(66.1)和Qwen3-235B-A22B Non-thinking(52.0),证明了在复杂的开放式任务中卓越的能力和与人类偏好的强对齐。
工具使用和函数调用:在BFCL-v3中得分70.9,领先于Qwen3-235B-A22B Non-thinking(68.0)和Kimi K2(65.2),展示了在外部工具集成和API使用方面的高级能力。
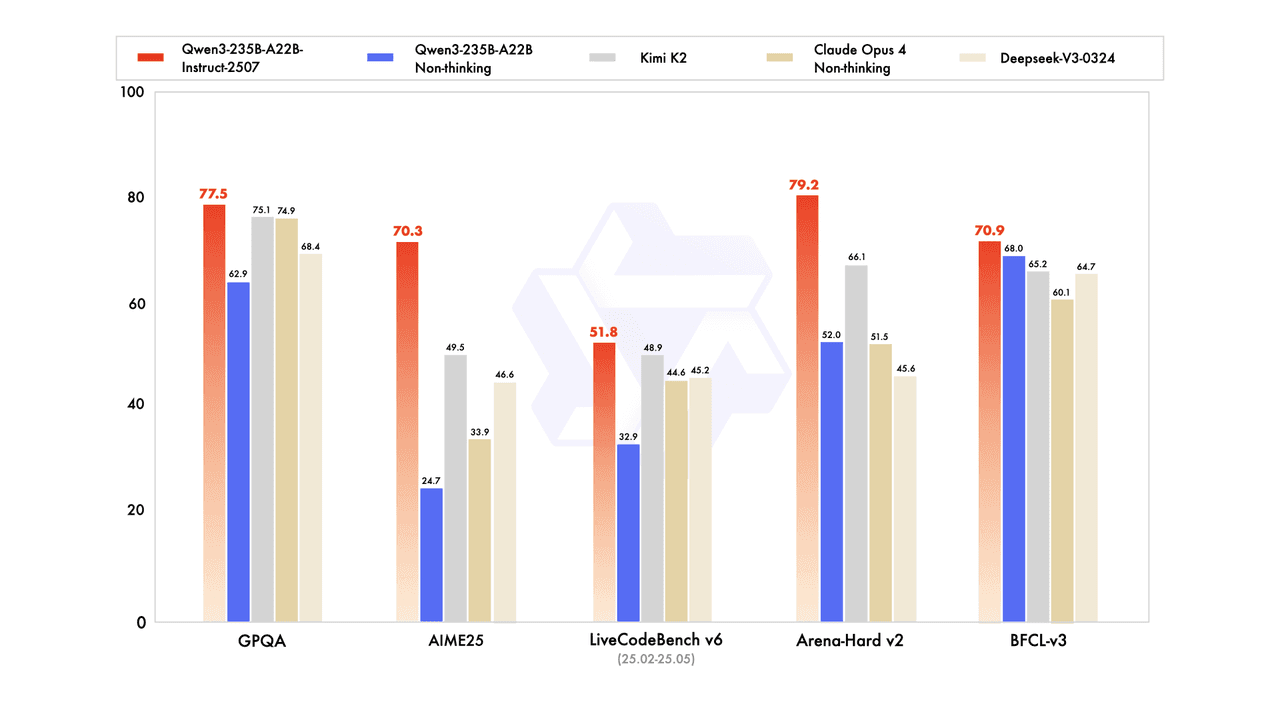
这些令人印象深刻的结果标志着开源AI开发中的一个重大里程碑。Qwen3-235B-A22B-Instruct-2507不仅匹敌,还超越了多个基准上的专有模型,如Claude Opus 4 Non-thinking,展示了开源模型正在达到新的能力高度。
立即开始
集成:使用我们的OpenAI兼容API。在SiliconFlow API文档中探索完整的API规范。
现在就在SiliconFlow上尝试,亲身探索这些强大的能力!
