Содержание

Краткое содержание (TL;DR): Qwen3-VL — самая мощная модель для работы с визуальными и языковыми данными в серии Qwen — теперь доступна на SiliconFlow. Этот релиз предлагает прорывные обновления: превосходное понимание и создание текста, мультимодальное рассуждение, передовое пространственное и видео восприятие, окна контекста в 262K, OCR на 32 языках и более сильное взаимодействие с агентами. Основанная на архитектурах Dense и MoE с количеством параметров до 235B и инновацией как Interleaved-MRoPE и DeepStack, эта модель устанавливает новый стандарт для мультимодального ИИ.
Теперь доступны обе версии Instruct и Thinking на SiliconFlow. Начните создавать с помощью готового к использованию API от SiliconFlow сегодня!
Мы рады сообщить, что серия Qwen3-VL теперь доступна на SiliconFlow. Как модель следующего поколения для работы с визуальными и языковыми данными, созданная для того, чтобы лучше видеть, понимать и реагировать на мир, Qwen3-VL предоставляет прорывные возможности, которые переопределяют мультимодальный ИИ. Она обеспечивает точное понимание видео, расширенный OCR на 32 языках с улучшенной обработкой редких символов и исторических текстов, и окно контекста в 262K для анализа длинных текстов.
Теперь SiliconFlow предлагает обе версии: Instruct и Thinking: первая оптимизирована для эффективного выполнения, вторая улучшена для более глубоких размышлений, что дает пользователям гибкость в выборе подходящей модели для их нужд.
С помощью API Qwen3-VL от SiliconFlow вы можете ожидать:
Экономически выгодные цены:
Qwen3-VL-30B-A3B-Instruct $0.29/М tokens (Input) и $1/М tokens (Output)
Qwen3-VL-30B-A3B-Thinking $0.29/М tokens (Input) и $1/М tokens (Output)
Qwen3-VL-235B-A22B-Instruct $0.3/М tokens (Input) и $1.5/М tokens (Output)
Qwen3-VL-235B-A22B-Thinking $0.45/М tokens (Input) и $3.5/М tokens (Output)
Окно контекста в 262K: Обеспечивает беспрепятственную обработку массивных документов и многоходовых бесед.
С этими комбинациями — 30B vs 235B, Instruct vs Thinking — SiliconFlow позволяет разработчикам выбирать между эффективностью, глубиной и стоимостью, вводя гибкую мультимодальную интеллектуальность в производство на любом масштабе.
Почему Qwen3-VL имеет значение
Большинство моделей, работающих с визуальными и языковыми данными, сталкиваются с противоречием: широкие возможности или глубокое рассуждение, но редко и то и другое. Общие модели испытывают трудности с сложной логикой, специализированные модели не обладают универсальностью. Видеть не значит понимать — и понимание не гарантирует решения проблемы.
Qwen3-VL решает это с помощью подхода двойного издания:
Instruct: Оптимизирована для широких, повседневных задач в области визуальных и языковых данных с надежной производительностью.
Thinking: Усилена передовыми возможностями рассуждения для решения сложных проблем в области STEM и математики.
Вместе они раскрывают возможности в трех ключевых областях:
1. Агентность
Визуальный агент: Позвольте ИИ управлять приложениями и вебсайтами за вас! Он распознает элементы пользовательского интерфейса, понимает их функции и выполняет многофазные задачи автономно. Он также достигает высшего мирового уровня производительности на таких ориентирах, как OS World, и используя инструменты значительно улучшает свою производительность на задачах тонкого восприятия.
Значительно лучшее пространственное понимание: Связывание в 2D от абсолютных координат до относительных координат. Он может оценивать положения объектов, изменения точек обзора и отношения заслонения. Также поддерживает 3D привязку, закладывая основу для сложного пространственного мышления и приложений ИИ.
От дизайна к коду: Загрузите скриншот или видео и создайте готовые к производству диаграммы Draw.io, HTML, CSS или JavaScript — делая реальностью визуальное программирование "что видишь, то и получаешь".

2. Восприятие и понимание
Понимание длинного контекста и видео: Все модели нативно поддерживают окно контекста в 262K, расширяемое до 1 миллиона tokens. Это означает, что вы можете вводить сотни страниц технической документации, целые учебники и даже часы видео — и модель будет все помнить и точно извлекать детали.
Расширенный OCR: Поддержка 32 языков, надежная работа с размытыми/наклоненными/малоосвещенными изображениями, улучшенная обработка редких символов, древних текстов и технической терминологии, плюс улучшенный разбор структуры для длинных документов.
Обновленное визуальное восприятие и распознавание: Усовершенствующая стратегия предобучения данных теперь позволяет модели распознавать гораздо более широкий круг объектов — от знаменитостей, персонажей аниме, продуктов и достопримечательностей до животных и растений — охватывая все, что нужно как в повседневной жизни, так и в профессиональных «распознать все» задачах.
3. Математика и язык
Более сильное мультимодальное мышление (версии Thinking): Модель Thinking специально оптимизирована для рассуждений в STEM и математике. Столкнувшись со сложными тематическими вопросами, она может замечать мелкие детали, разбивать проблемы на шаги, анализировать причины и следствия и давать логичные, основанные на доказательствах ответы. Она добивается сильных результатов на навигационных областях в области рассуждений, таких как MathVision, MMMU и MathVista.
Превосходная производительность с акцентом на текст: Qwen3-VL использует раннего стадийное совместное предобучение текстовых и визуальных модальностей, постоянно укрепляя свои языковые способности. Ее производительность в задачах, ориентированных на текст, соответствует Qwen3-235B-A22B-2507 — флагманской языковой модели — что делает ее поистине «основной на тексте, мультимодальной мощной» для следующего поколения моделей данных зрения-языка.

Тестовая производительность и обновления технической архитектуры
Qwen3-VL не только демонстрирует обширные навыки работы с данными зрения и языка, но и обеспечивает передовую производительность в чисто текстовых и мультимодальных оценках.
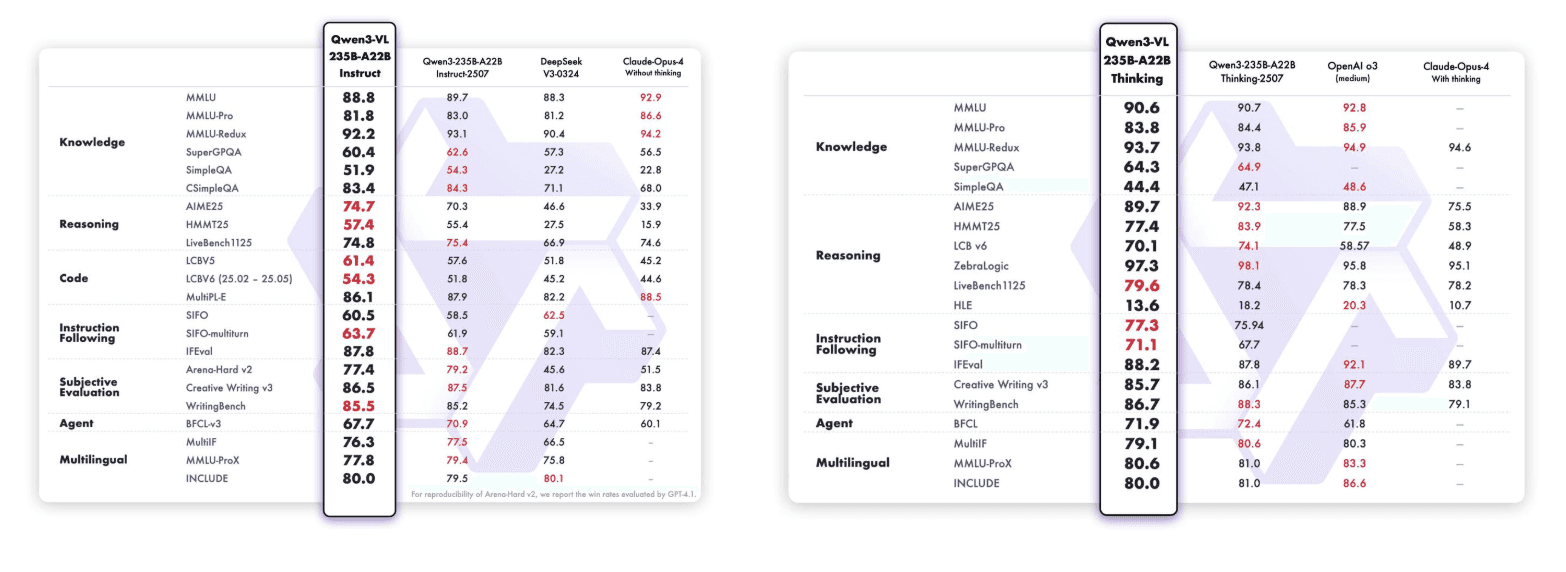
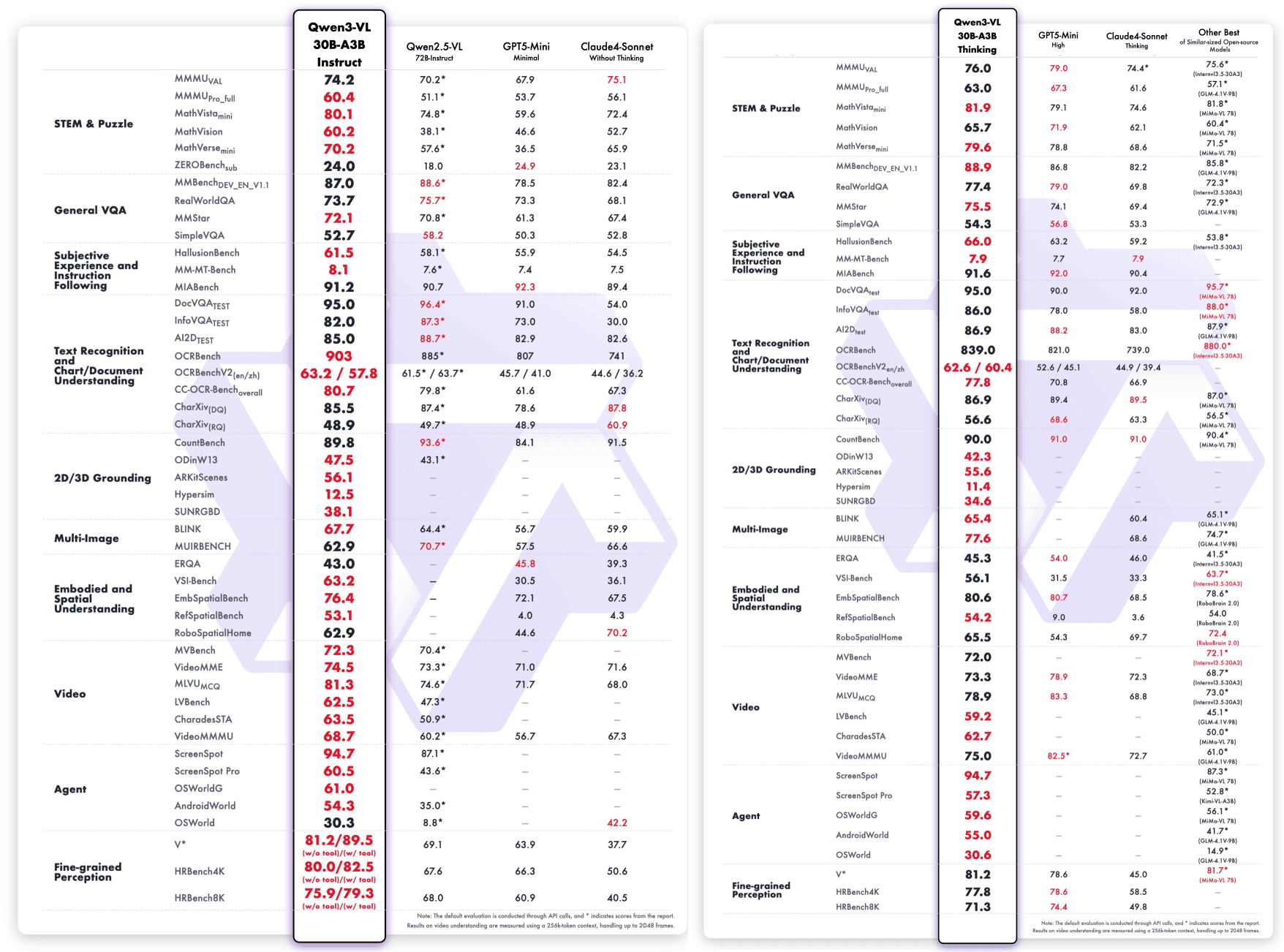
Qwen3-VL-235B-A22B-Instruct и Qwen3-VL-235B-A22B-Thinking:
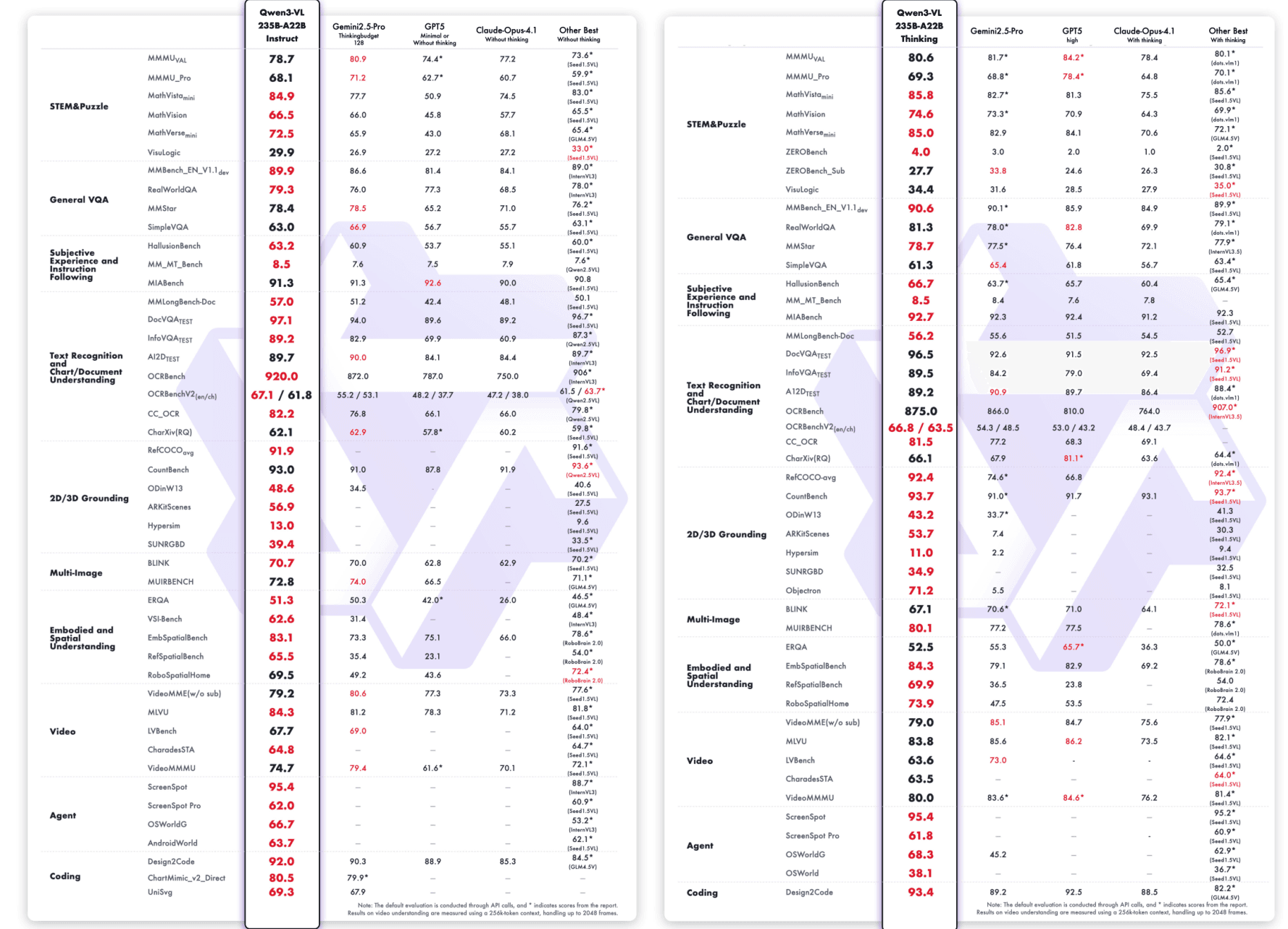
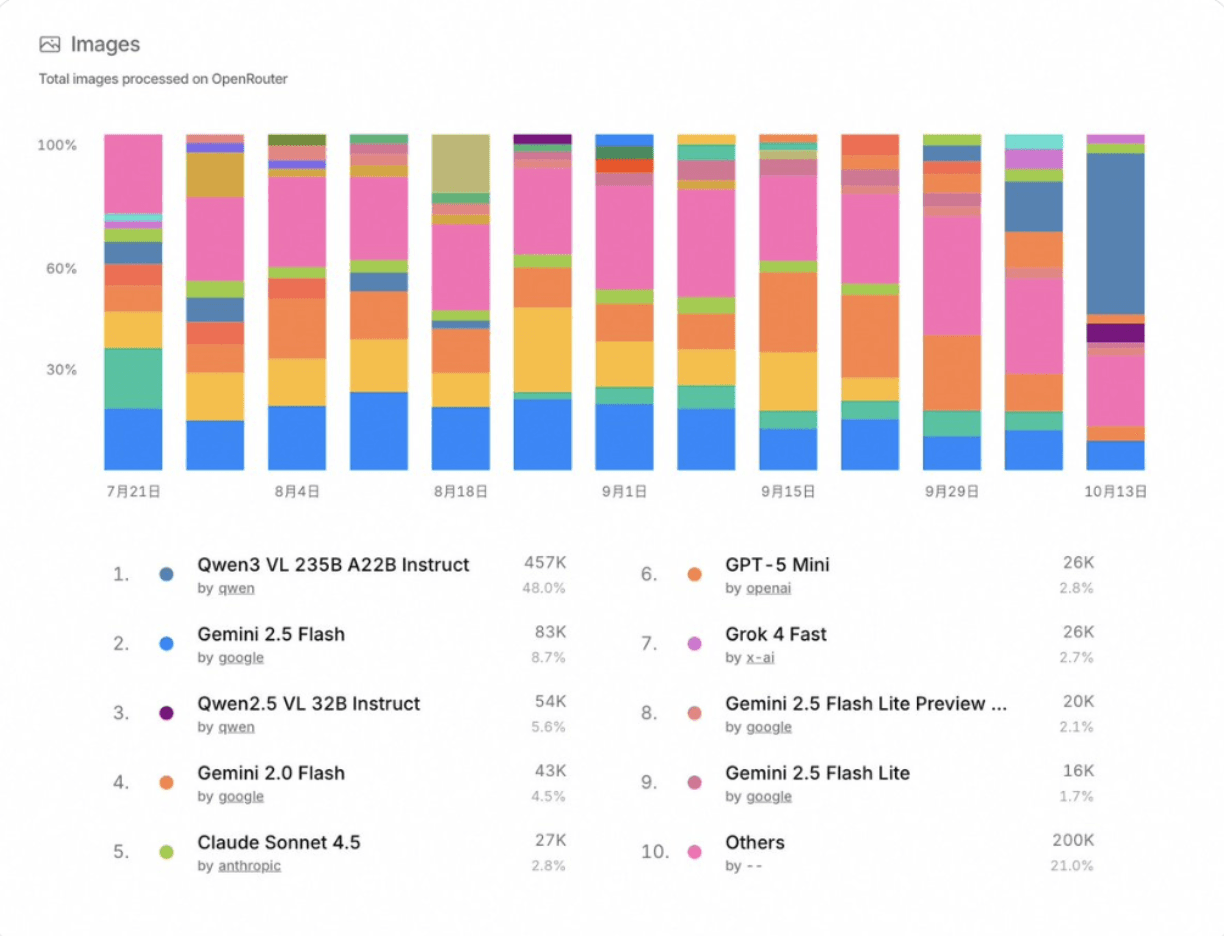
Помимо тестовой производительности, Qwen3-VL-235B-A22B-Instruct также получил замечательную популярность среди открытого сообщества. Согласно последним статистическим данным OpenRouter (октябрь 2025 года), он занимает первое место по обработке изображений с 48% долей рынка, превосходя другие передовые мультимодальные модели, такие как Gemini 2.5 Flash и Claude Sonnet 4.5.
Примечательно, что SiliconFlow также выступает в качестве поставщика на OpenRouter, предлагая Qwen3-VL-235B-A22B-Instruct наряду с другими ведущими моделями, такими как DeepSeek-V3.2-Exp, GLM-4.6, Kimi K2-0905 и GPT-OSS-120B, предоставляя разработчикам унифицированный доступ к широкому спектру передовых моделей.
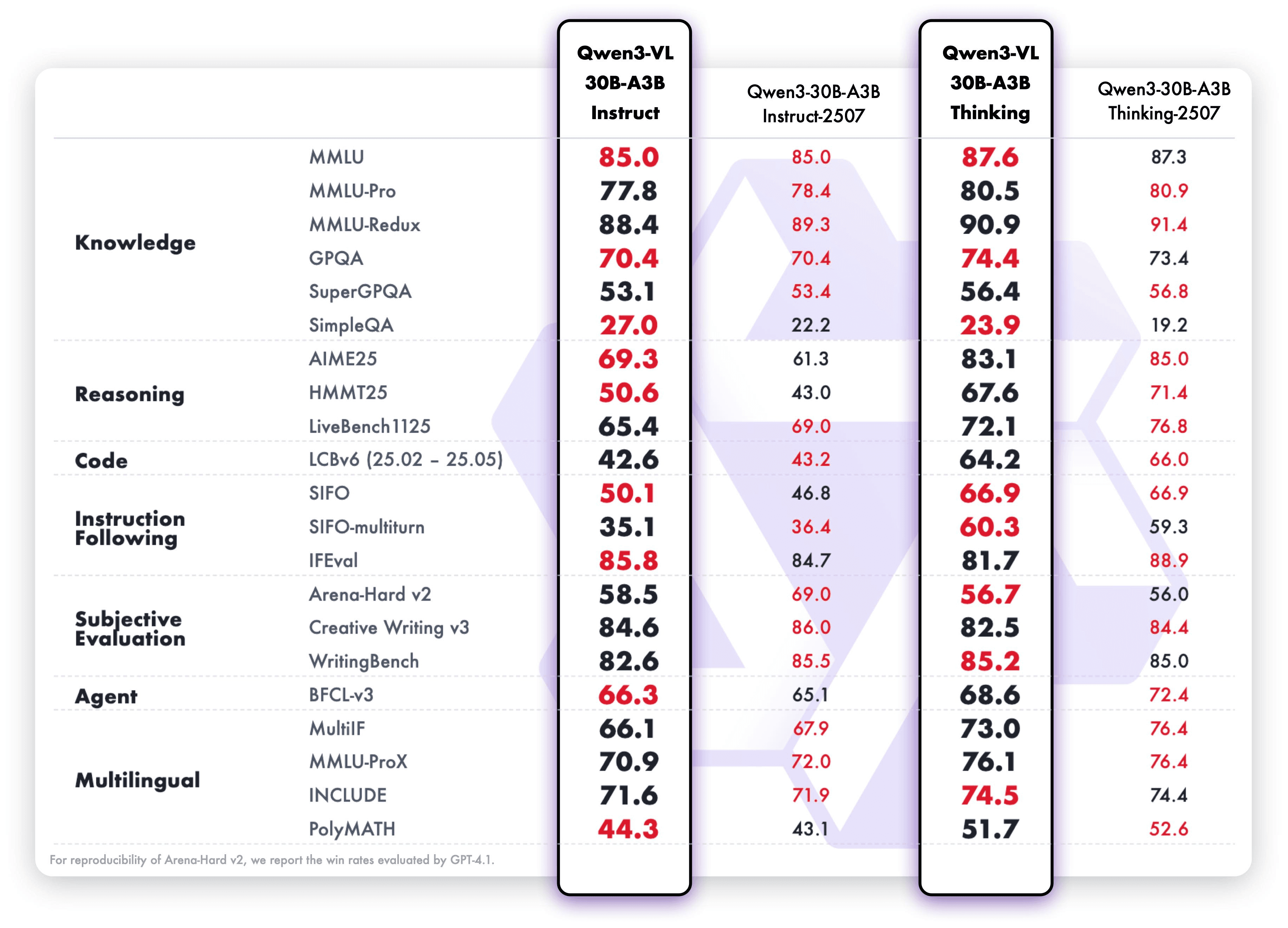
Qwen3-VL-30B-A3B-Instruct и Qwen3-VL-30B-A3B-Thinking:
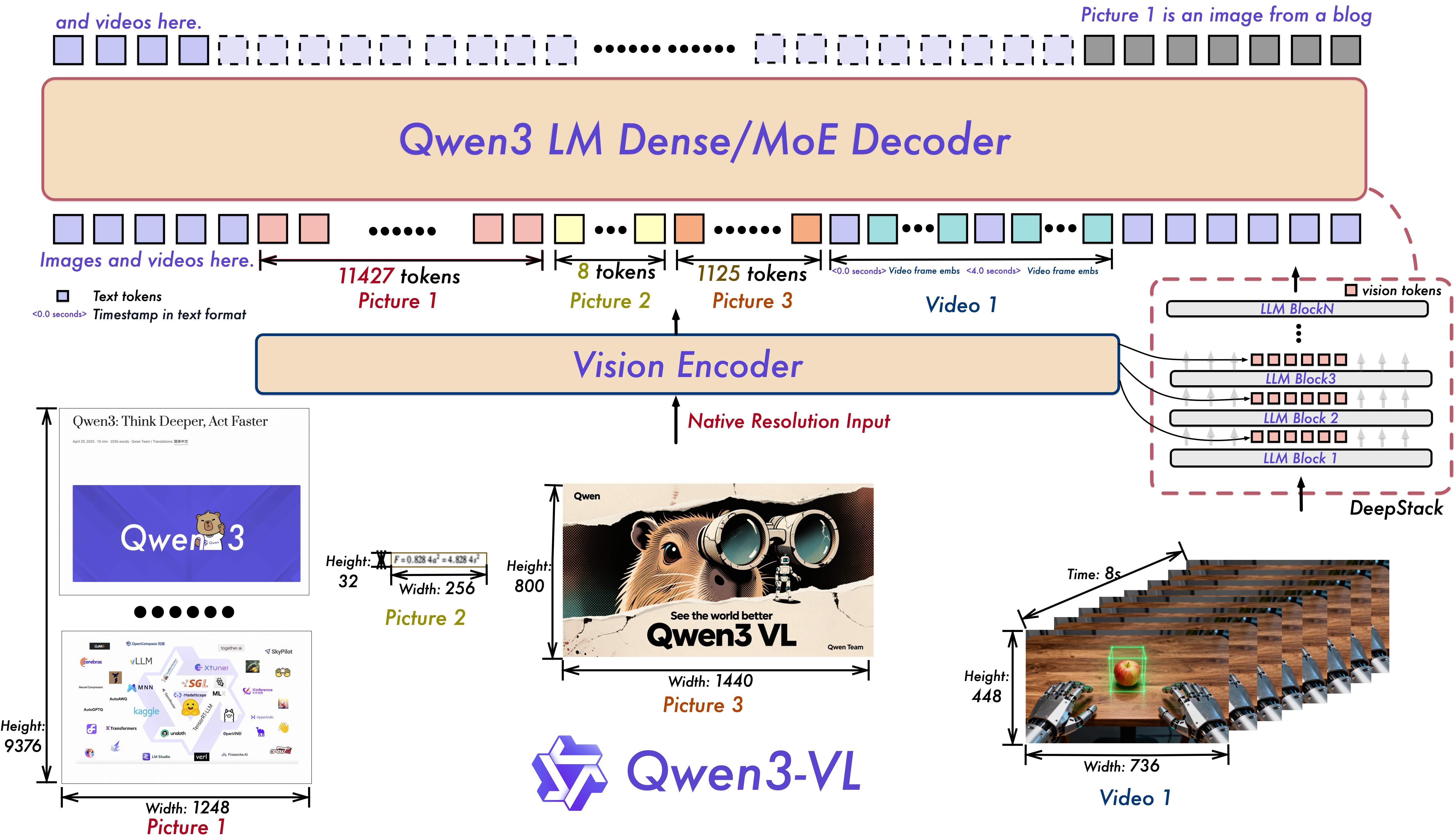
Инновации архитектуры
Три ключевых прорыва делают возможностями Qwen3-VL:
Interleaved-MRoPE: Полное частотное распределение по времени, ширине и высоте через надежные позиционные встраивания, улучшающее рассуждение для долгосрочного видео.
DeepStack: Сливает многоуровневые функции ViT для захвата мелкозернистых деталей и уточнения выравнивания изображений и текста.
Выравнивание текста и временных меток: Переходит за пределы T‑RoPE к точному, основанному на временных метках определению события для более сильного временного моделирования видео.
Реальные сценарии применения
Анализ и индексирование видеоконтента Обработка часов видео с точным пониманием кадров—спросите "Что произошло на 15-й минуте?" или "Кратко изложите ключевые темы, которые обсудил выступающий в красном." Идеально подходит для медиа-компаний, образовательных платформ и модерации контента, требующих эффективного анализа длинных форматов.
Интеллектуальная обработка документов Извлечение структурированной информации из сложных документов на 32 языках—включая исторические архивы, технические руководства и размытые сканы. Обрабатывайте целые книги (до 1M tokens) для юридических исследований, академического анализа или управления знаниями в бизнесе.
Разработка без кода и автоматизация пользовательского интерфейса Загрузите макеты дизайна для создания готового к производству кода или позвольте Visual Agent автономно управлять приложениями—заполняя формы, тестируя рабочие процессы и выполняя многоэтапные задачи. Ускорьте проектирование, автоматизацию QA и сократите время ручного кодирования.
Образование и исследования в STEM Анализ научных диаграмм и математических формул с пошаговым рассуждением. Версия Thinking разбивает сложные проблемы, объясняет причинность и предоставляет доказательные ответы для студентов, исследователей и преподавателей.
Начать использовать немедленно
1. Исследуйте: Попробуйте Qwen3-VL series в песочнице SiliconFlow.
2. Интегрируйте: Используйте наш OpenAI-совместимый API. Изучите полные спецификации API в документации API SiliconFlow.
Будь то создание мультимодальных агентов, автоматизация рабочих процессов пользовательского интерфейса или анализ длинных видео, Qwen3-VL предоставляет возможность видеть, понимать и рассуждать.
Начните использовать готовый к производству API от SiliconFlow и внедрите визуальный интеллект в свой рабочий процесс уже сегодня!
Запросы по бизнесу или продажам →
Присоединяйтесь к нашему сообществу Discord сейчас →
Следите за нами на X, чтобы получать последние обновления →
Исследуйте все доступные модели на SiliconFlow →
