Содержание

Краткий обзор: Qwen3-VL-8B — новейший участник семейства Qwen3-VL — теперь доступен на SiliconFlow. Эта компактная Vision-языковая Model обеспечивает полномасштабное Multimodal рассуждение в версиях Instruct и Thinking, с значительно меньшим потреблением видеопамяти (VRAM). Несмотря на размер 8B параметров, она наследует полные возможности флагманской Qwen3-VL-235B — от генерации продвинутого Text до пространственного и Video понимания, превосходя более крупные модели, такие как Gemini 2.5 Flash Lite и GPT-5 Nano. Доказывая, что эффективность сочетается с производительностью, Qwen3-VL-8B теперь доступен через готовый к производству API от SiliconFlow.
Расширяя экосистему Qwen3-VL, SiliconFlow рада представить серию Qwen3-VL-8B в нашем каталоге моделей — компактную, но мощную Dense Vision-языковую модель, которая переопределяет баланс между размером параметров и Multimodal возможностями. Доступна в версиях Instruct и Thinking, она наследует полные возможности своих флагманских собратьев, Qwen3-VL-235B-A22B-Instruct и Qwen3-VL-235B-A22B-Thinking, включая превосходное понимание и генерацию Text, глубокое визуальное восприятие и рассуждения, увеличенную длину контекста, улучшенное пространственное и Video понимание, а также усиленные агентные возможности.
С API Qwen3-VL-8B от SiliconFlow вы можете ожидать:
Доступное по цене ценообразование:
Qwen3-VL-8B-Instruct: $0.18/M tokens (Input) и $0.68/M tokens (Output)
Qwen3-VL-8B-Thinking: $0.18/M tokens (Input) и $2.00/M tokens (Output)
Окно контекста 262K: Поддерживает длинную океану Multimodal понимание через Text, Image и Video.
Бесшовная интеграция: Мгновенно создавайте с API, совместимой с SiliconFlow's OpenAI/Anthropic, или интегрируйте в свой существующий рабочий процесс.
Почему Qwen3-VL-8B важен
Основываясь на фундаменте семейства Qwen3-VL, вариант 8B вводит полный набор улучшений, предназначенных для реальных приложений:
Визуальные агентные возможности: Управляет интерфейсами ПК/мобильных приложений — распознает элементы, понимает функции, вызывает инструменты и завершает задачи автономно.
Продвинутое пространственное восприятие: Оценивает позиции объектов, перспективы и заслоны; обеспечивает более сильное 2D закрепление и позволяет 3D закрепление для пространственного рассуждения и воплощенного ИИ.
Ускорение визуального кодирования: Генерирует Draw.io/HTML/CSS/JS из Image и Video.
Длинное понимание контекста и Video: Нативный контекст 256K (расширяемый до 1M), обрабатывает книги и многочасовые Video с полной реконструкцией и индексированием второго уровня.
Улучшенная Multimodal рассуждательность: Превосходит в STEM/математике с причинно-следственным анализом и логическими, основанными на доказательствах ответами.
Расширенный OCR: Поддерживает 32 языка (по сравнению с 19), с увеличенной устойчивостью к низкой освещенности, размытию и наклону, улучшенная обработка редких или древних символов и технической лексики, а также улучшенный парсинг структуры длинных документов.
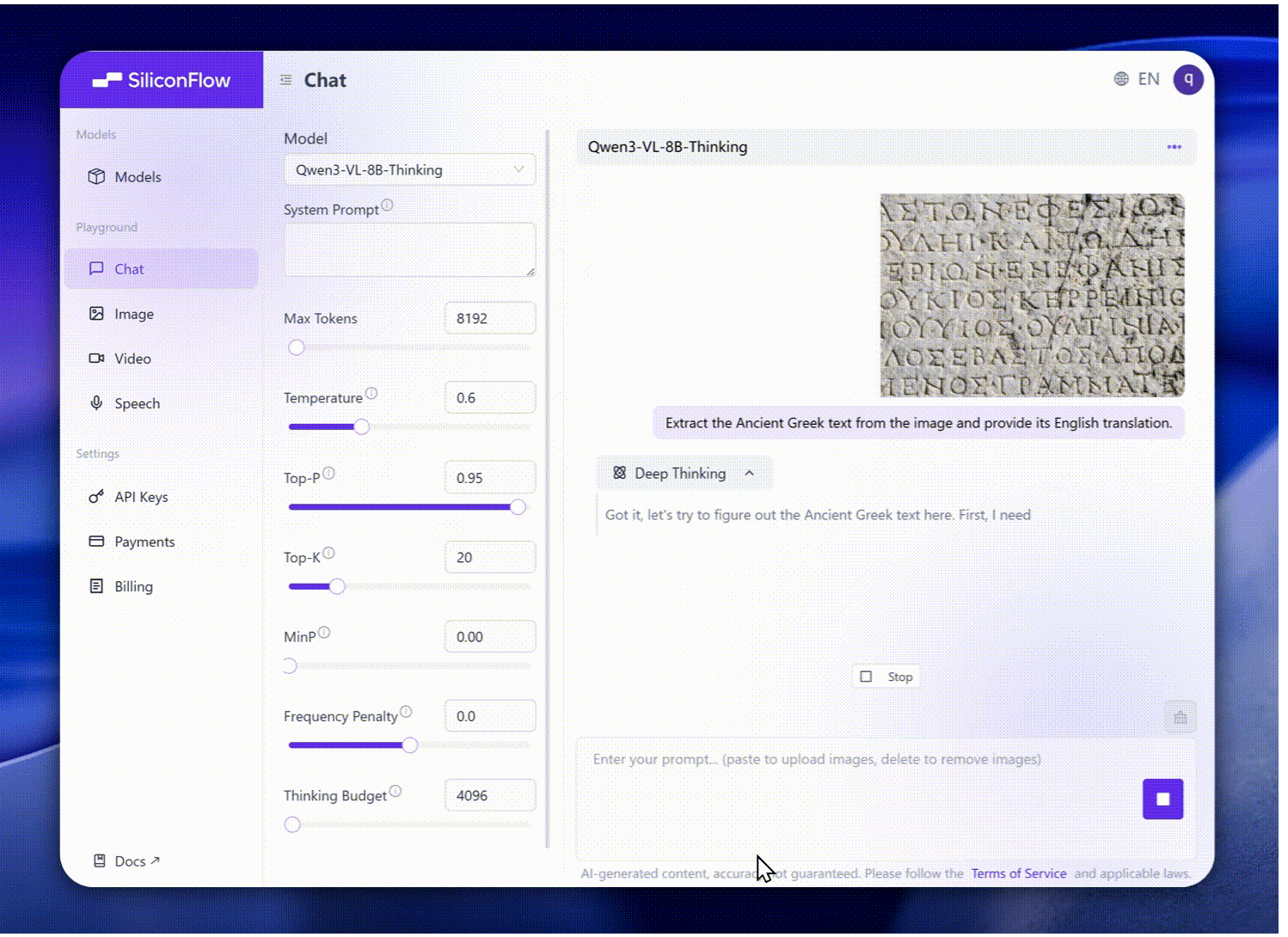
Обновленное визуальное распознавание: Более широкое, более качественное предобучение позволяет полное распознавание — знаменитости, аниме, продукты, достопримечательности, флора/фауна и многое другое.
Понимание Text на уровне чистых LLM: Бесшовное Text-Vision слияние для потерь без потерь, унифицированного понимания.
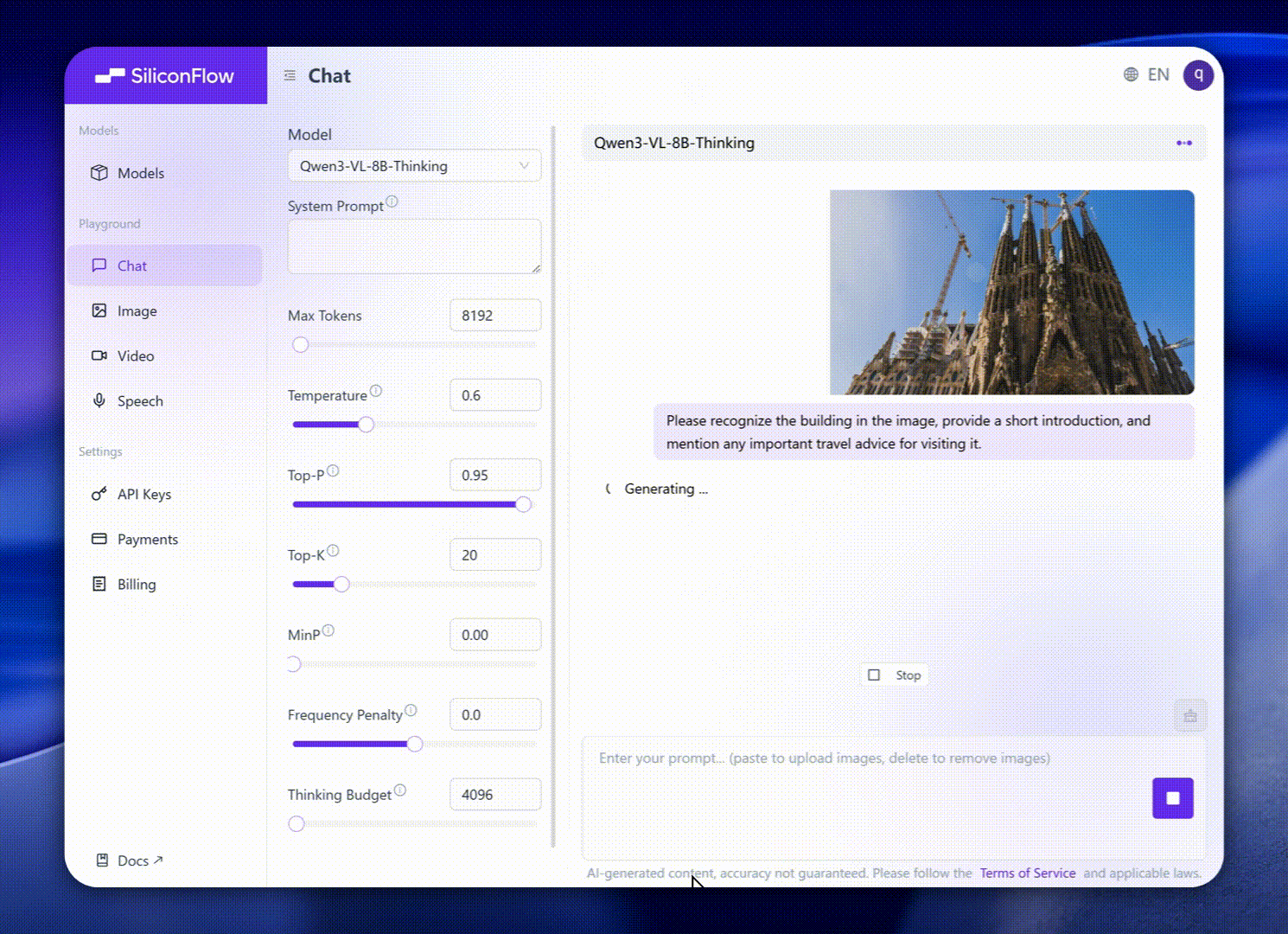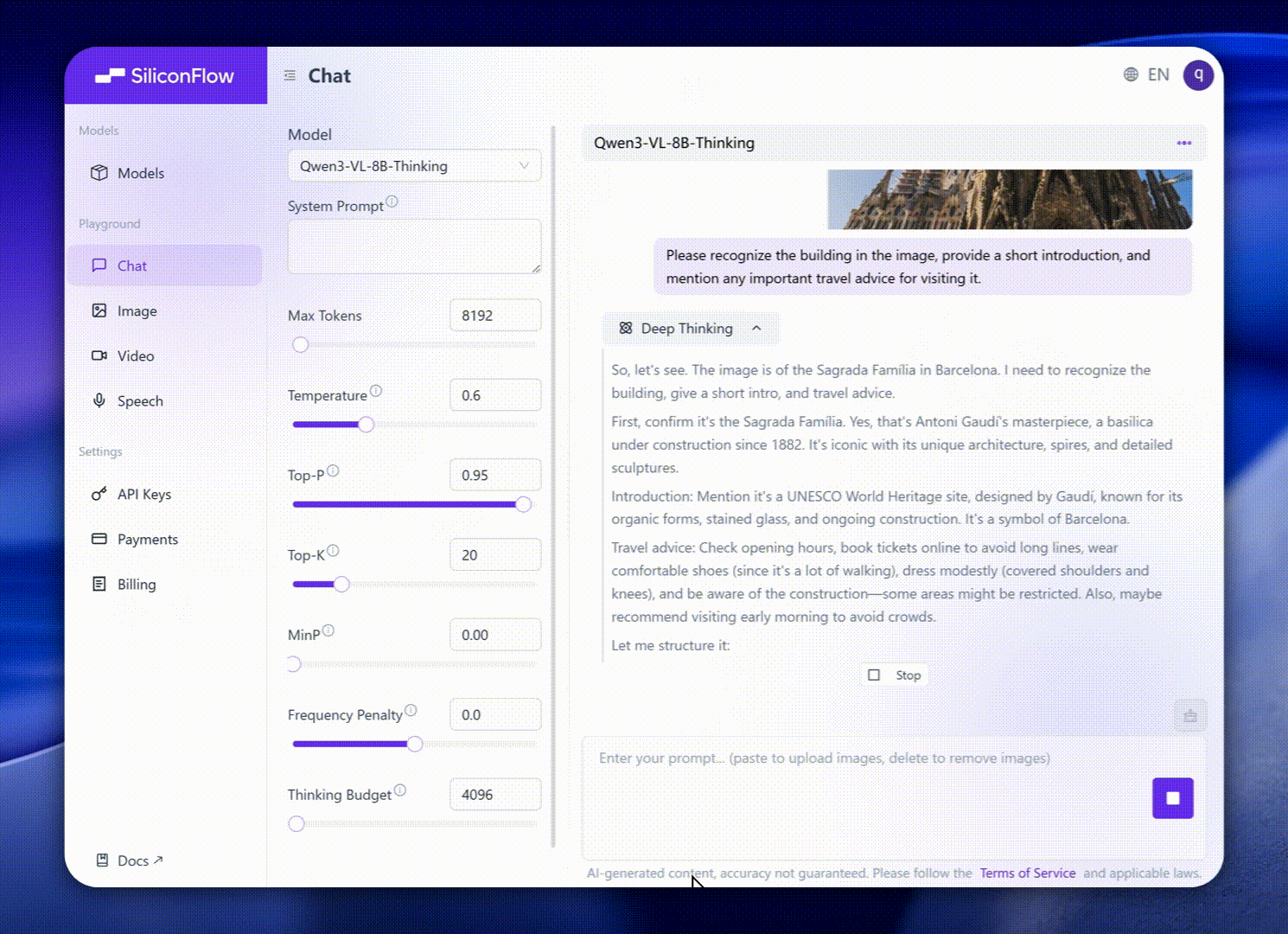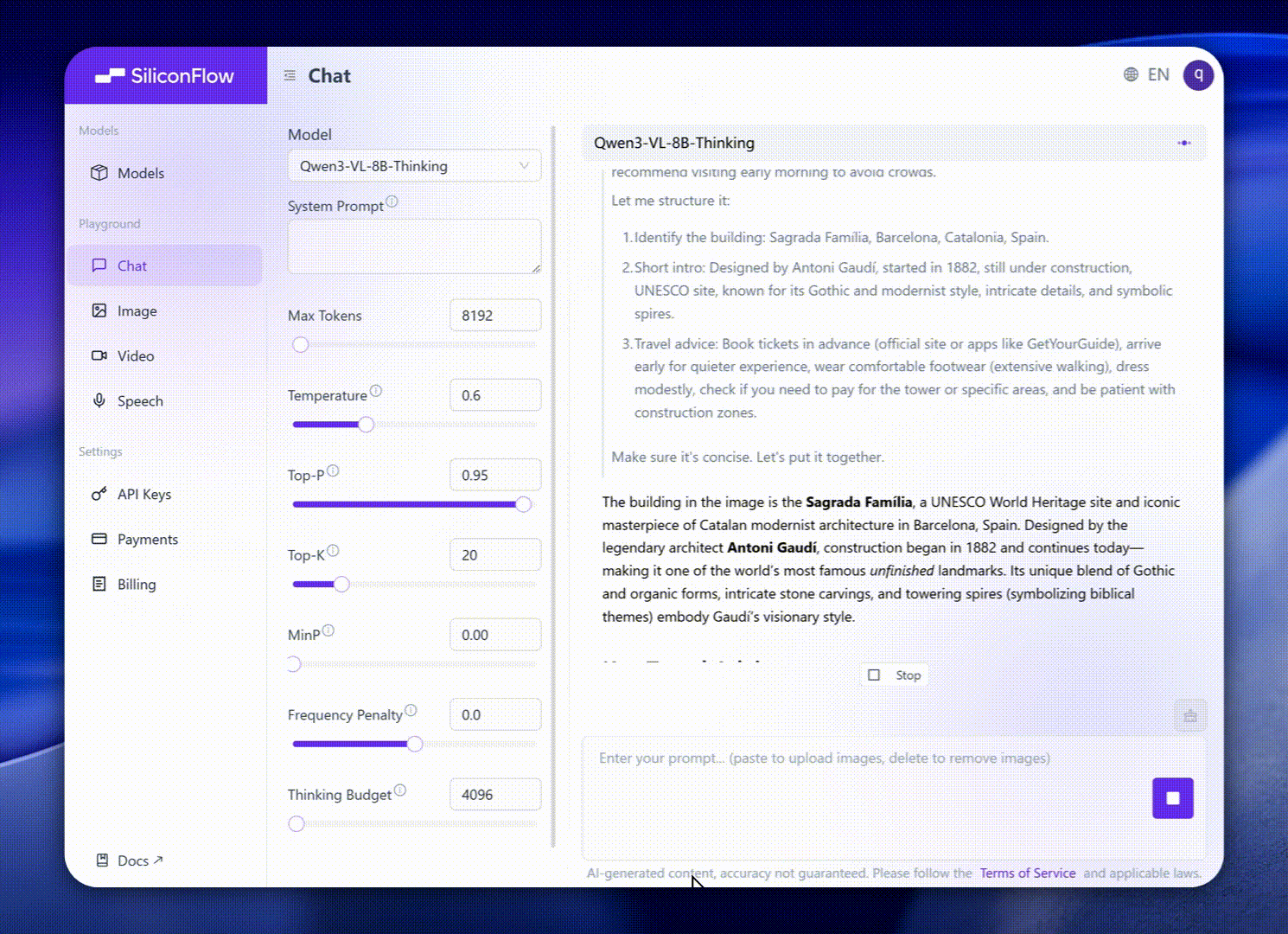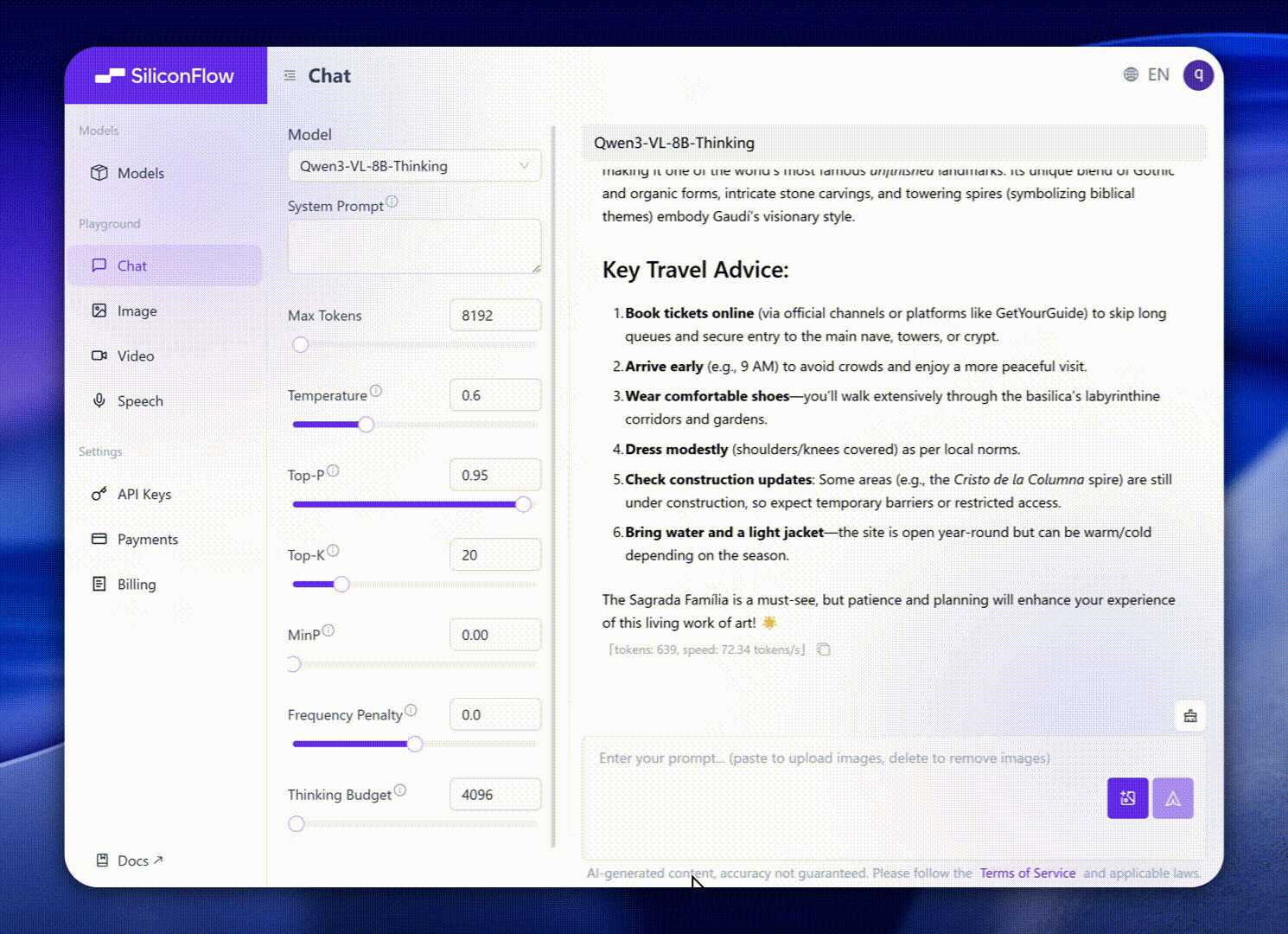
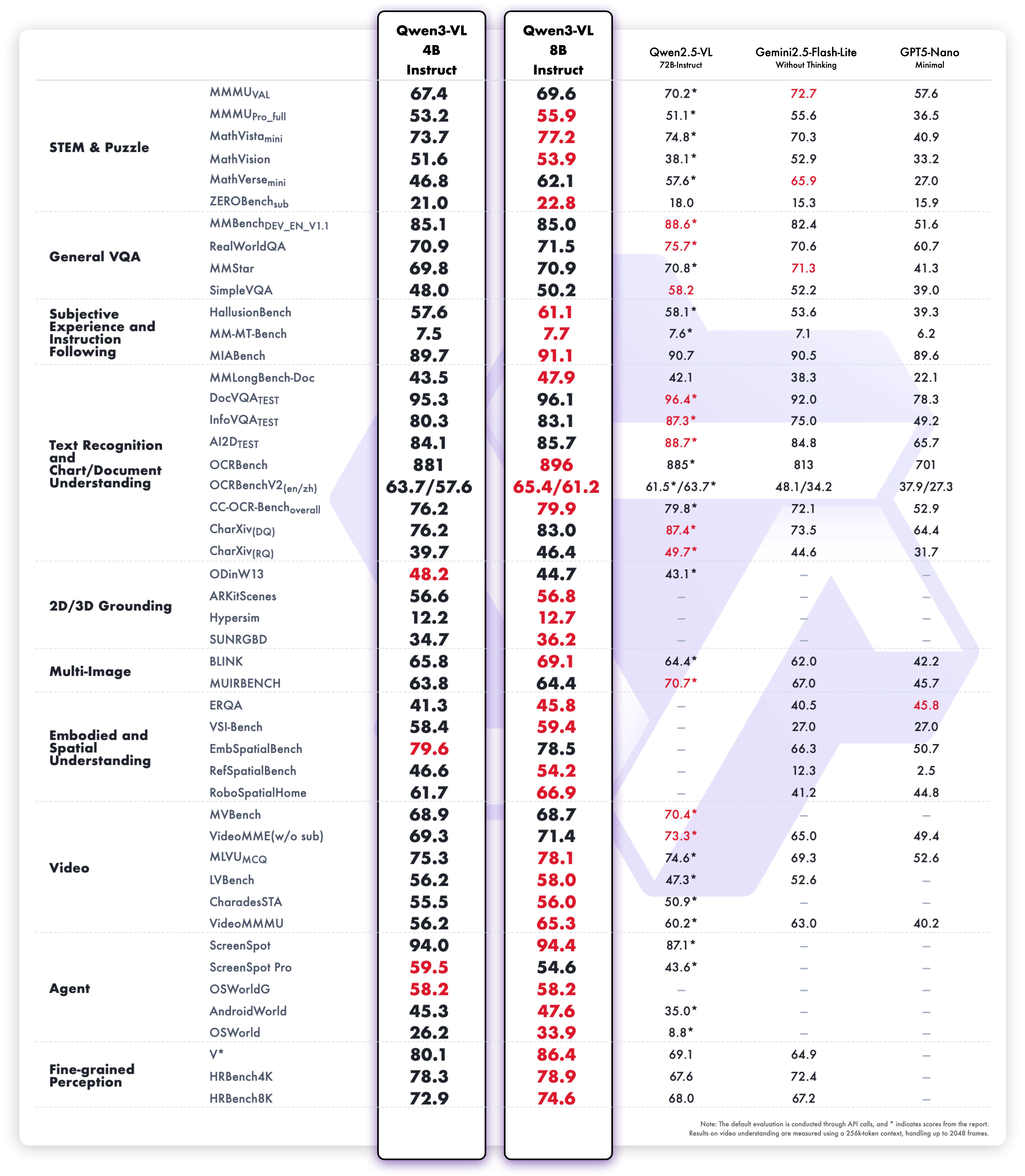
Эти усовершенствования переводятся в исключительную производительность реальных мировых бенчмарков. Qwen3-VL-8B обеспечивает выдающуюся производительность по публичным бенчмаркам в STEM, VQA, OCR, Video понимание и агентные задачи — превосходя Gemini 2.5 Flash Lite и GPT-5 Nano, и даже соперничая с гораздо более крупным Qwen2.5-VL-72B.
Особенно, она достигает впечатляющей пространственной рассуждательности производительности, предлагая прочную основу для продвижения приложений воплощенного интеллекта.
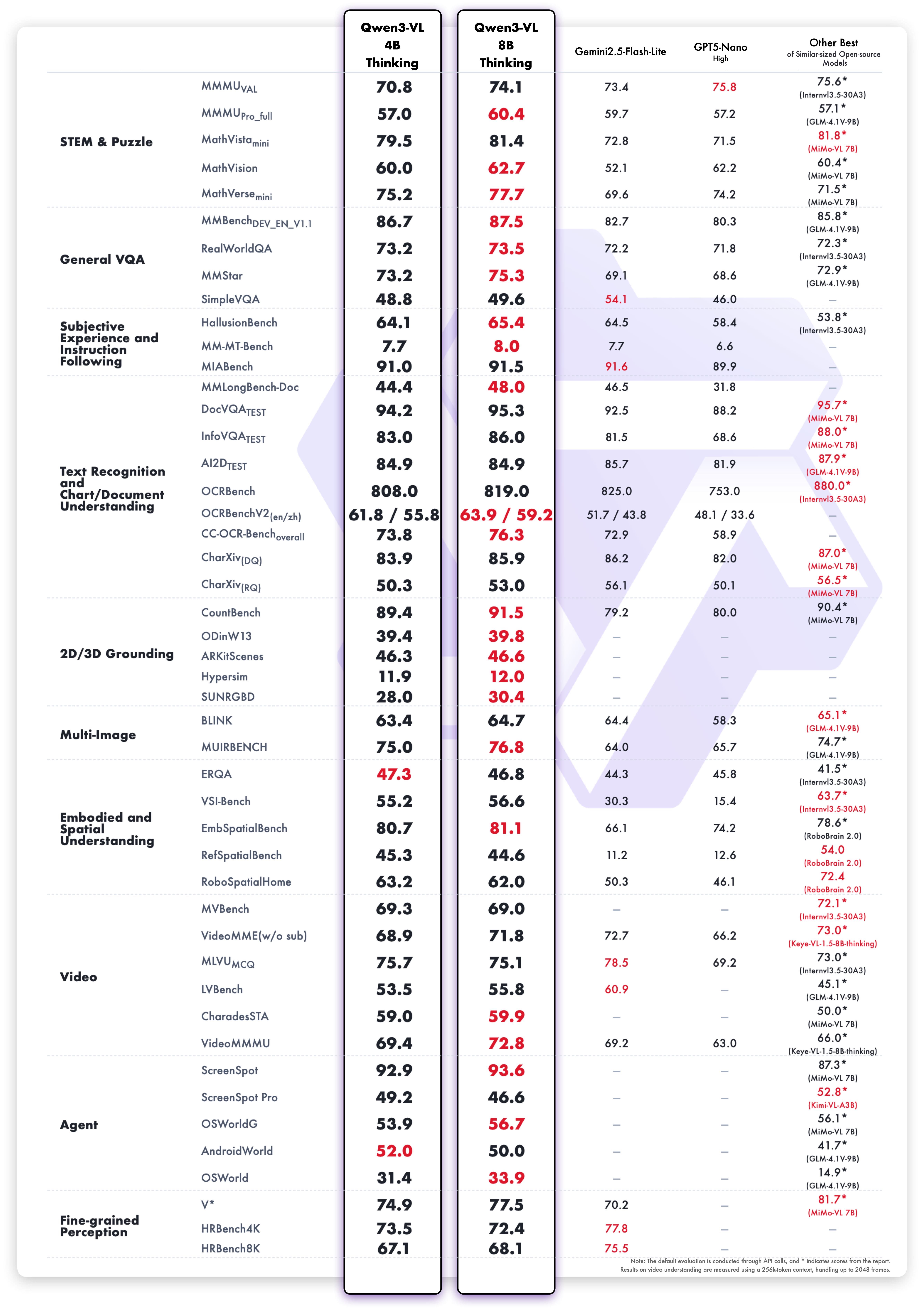
Также небольшие модели Multimodal всегда сталкиваются с фундаментальным компромиссом: улучшение визуальных возможностей часто ущемляет понимание Text, и наоборот. Этот "эффект качелей" долгое время являлся барьером для создания компактных, но способных Vision-языковых моделей. Qwen3-VL-8B преодолевает это ограничение за счет сбалансированной кооптимизации Precision и Text устойчивости.
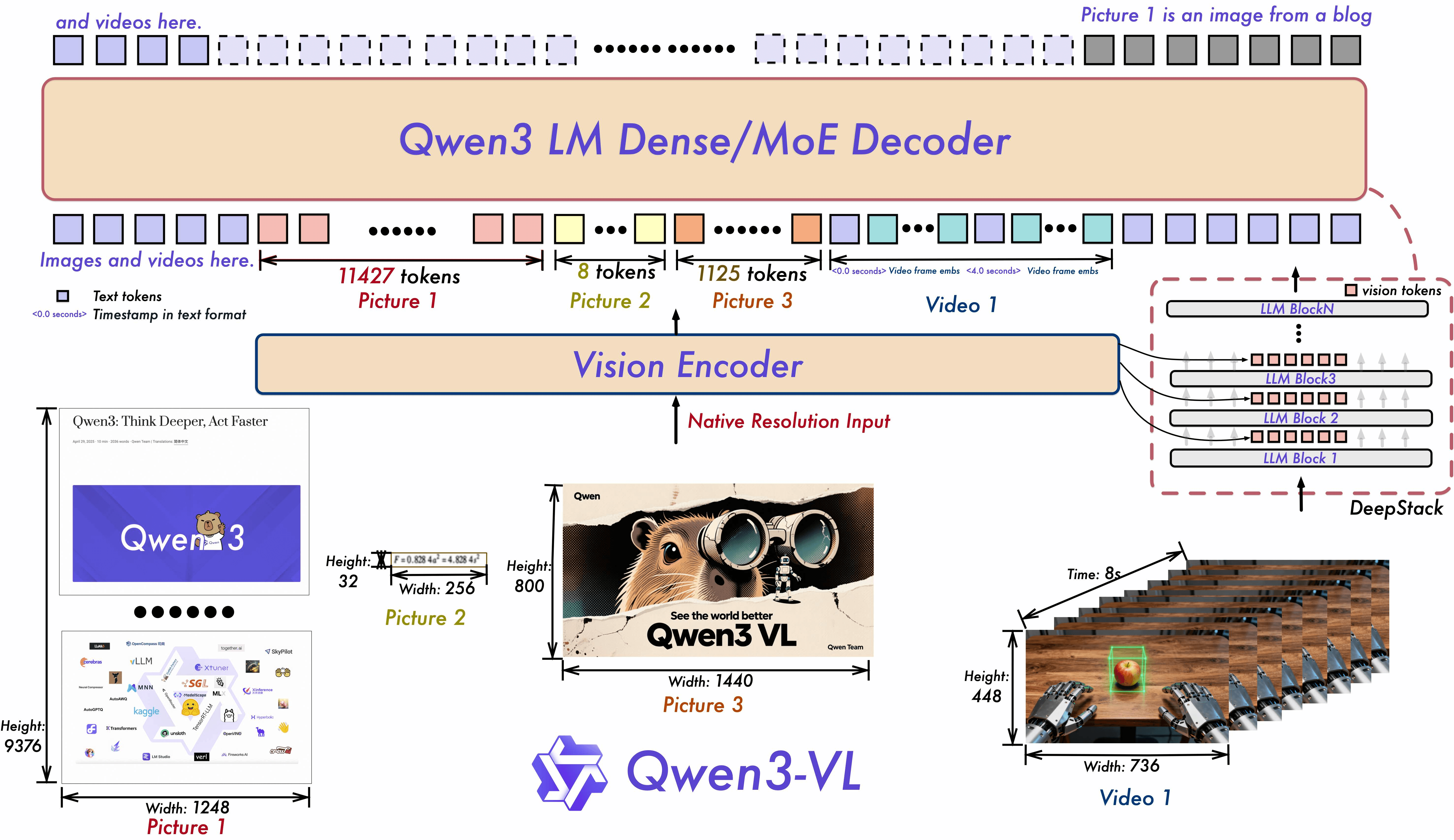
Через архитектурные инновации и техническую оптимизацию модель значительно улучшает Multimodal восприятие, сохраняя мощное Text понимание, продемонстрированное в бенчмарках ниже.
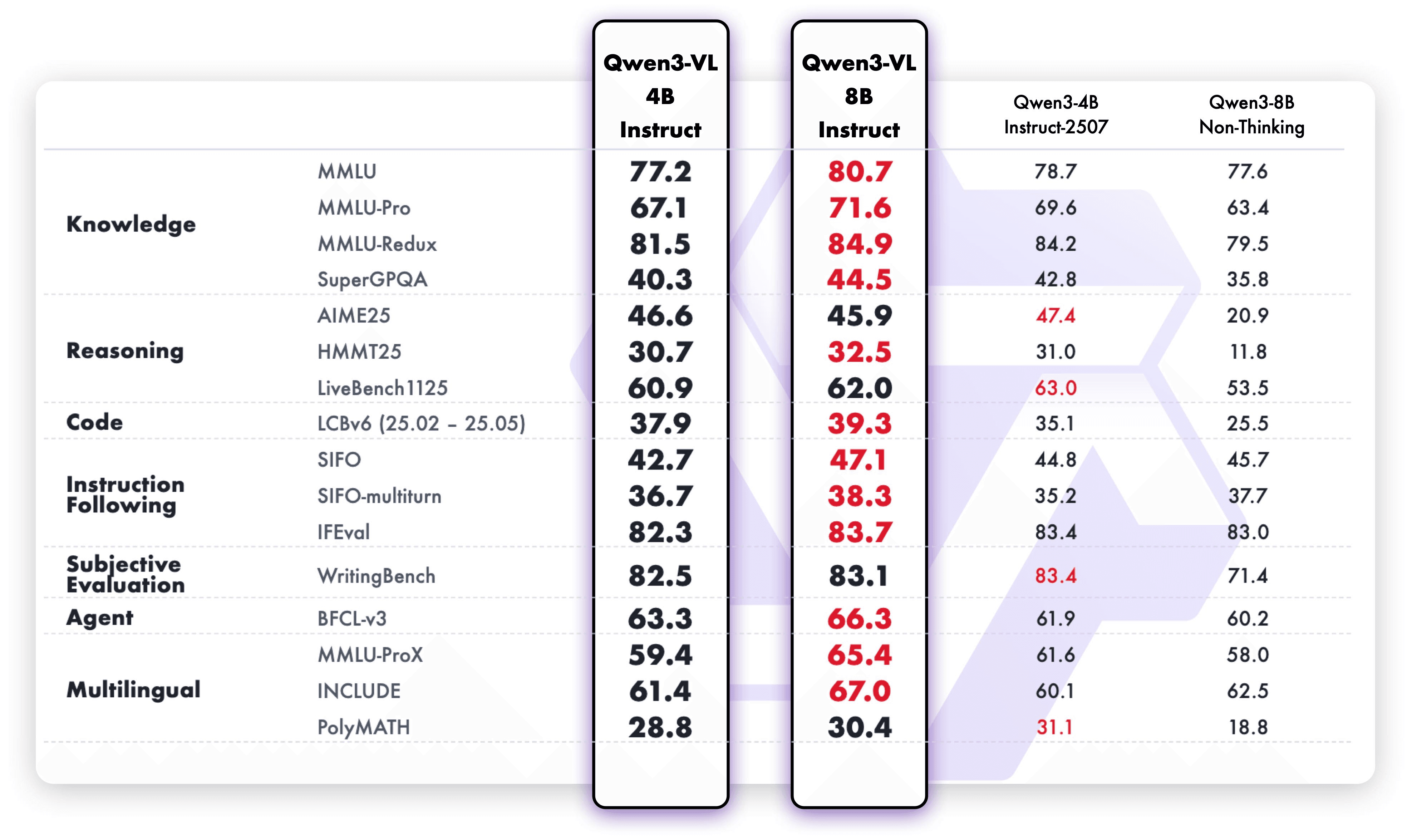
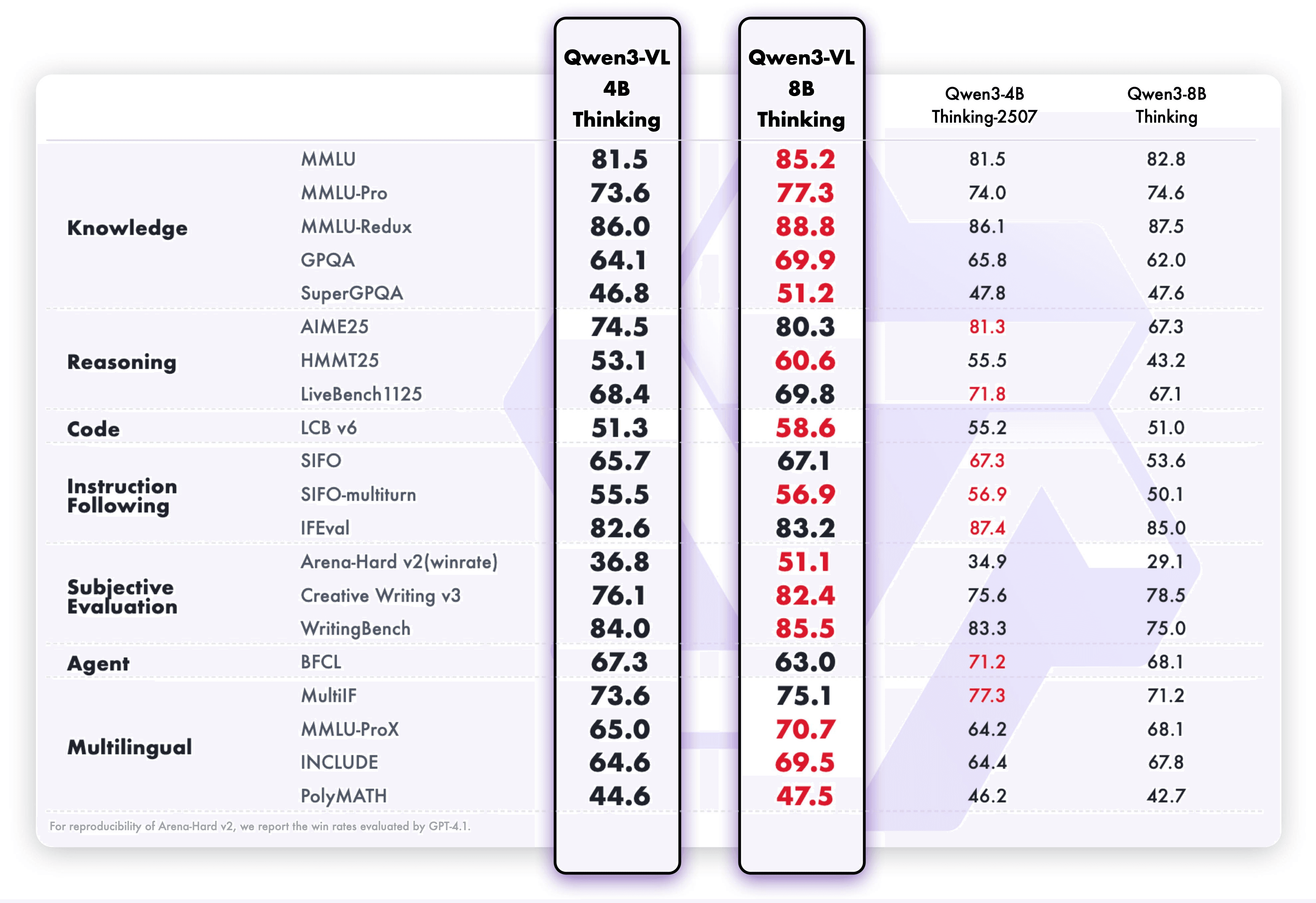
Результат? Больше способностей теперь помещается в меньшую модель — от распознавания до рассуждения, от Text до Image и Video.
Сценарии реального применения
С его компактной 8B Dense архитектурой и полном спектре Multimodal возможностей, Qwen3-VL-8B приносит продвинутый визуальный интеллект в рабочие процессы реального мира:
Визуальные рассуждения и задачи STEM: Интерпретировать диаграммы, графики и математические формулы для решения задач по геометрии, физике или химии с четкими логическими объяснениями. Идеально подходит для образования, исследований и систем AI обучения.
Понимание документов и OCR: Извлечение и резюмирование информации из отсканированных документов, квитанций или технических статей на 32 языках. Поддерживает сложный разбор макетов, распознавание таблиц и преобразование структурированных данных.
Динамическое Vision и агентное взаимодействие: Анализировать кадры Video, распознавать элементы GUI и моделировать взаимодействия в интерфейсах ПК или мобильных — давая возможность автономным агентам "видеть, рассуждать и действовать" в реальных условиях.
Multimodal создание: Преобразовать визуальные входы в креативные или технические выходы, такие как генерация HTML/CSS/JS макетов из скриншотов или написание описательных нарративов из Image и клипов.
Независимо от того, строите ли вы интеллектуальных помощников, системы анализа документов или креативные Multimodal инструменты, Qwen3-VL-8B приносит флагманский уровень Multimodal интеллекта в ваш рабочий процесс через API услуги от SiliconFlow.
Начните сразу же
Исследовать: Попробуйте серию Qwen3-VL-8B в SiliconFlow playground.
Интеграция: Используйте наш API, совместимый с OpenAI. Ознакомьтесь с полными спецификациями API в документации API SiliconFlow.
Начните строить с Qwen3-VL-8B сегодня и испытайте флагманский уровень Multimodal интеллекта через готовый к производству API SiliconFlow!
