목차

Qwen이 최근에 Qwen3-235B-A22B-Instruct-2507, 플래그십 모델 Qwen3-235B-A22B Non-thinking의 업그레이드 버전을 출시했습니다. 이는 오픈 소스 도메인에서 큰 도약을 나타내며, 일반 기능이 향상되고 우수한 추론 성능을 가져오며 이제 SiliconFlow에서 사용할 수 있습니다.
이 최첨단 모델은 명령어 따르기, 논리적 추론, 수학, 코딩 및 도구 사용에서 중요한 향상을 제공합니다. 포괄적인 벤치마크에 따르면 Kimi-K2와 DeepSeek-V3-0324 같은 주요 오픈 소스 모델뿐만 아니라 Claude-Opus4-Non-thinking과 같은 독점 모델들을 능가합니다. 이 모델은 기업 애플리케이션 구축, 첨단 연구 수행, 다국어 콘텐츠 생성 또는 지능형 어시스턴트 개발에서 예외적인 성능으로 이러한 작업을 처리합니다.
SiliconFlow의 Qwen3-235B-A22B-Instruct-2507 API를 사용하면 다음을 기대할 수 있습니다:
고속 Inference: 지연 시간이 낮고 처리량이 높은 방식으로 최적화되었습니다.
비용 효율적인 가격: $0.35/M tokens (Input) 및 $1.42/M tokens (Output).
확장된 컨텍스트 윈도우: 복잡한 작업을 위한 256K 컨텍스트 윈도우.
향상된 기능 & 우수한 성능
이제 SiliconFlow에서 사용할 수 있는 업데이트된 Qwen3-235B-A22B-Instruct-2507는 다음의 주요 기능 향상을 제공합니다:
향상된 일반 기능: 명령어 따르기, 논리적 추론, Text 이해, 수학, 과학, 코딩 및 도구 사용 향상.
사용자 선호도에 대한 더 나은 정합: 주관적이고 개방형 작업에서 사용자 선호도와의 보다 정밀한 정합을 통해 보다 유용하고 높은 품질의 응답을 가능하게 합니다.
확장된 다국어 지식: 전문적인 도메인 및 덜 흔한 정보를 포함하여 여러 언어에 걸쳐 장기적인 지식 범위에서 상당한 향상을 가져옵니다.
확장된 컨텍스트 이해: 256K의 장기 컨텍스트 이해 기능.
이러한 기능은 Qwen3가 주요 경쟁 업체들을 일관되게 능가하는 포괄적인 벤치마크 평가에서 명확하게 입증됩니다:
고급 과학적 추론: GPQA에서 77.5를 기록하면서 Kimi K2 (75.1)와 Claude Opus 4 Non-thinking (74.9)를 능가하며 대학원 수준의 과학적 추론 및 복잡한 문제 해결 능력을 보여줍니다.
수학적 문제 해결: AIME25에서 70.3를 기록하며 Kimi K2 (49.5)와 DeepSeek-V3-0324 (46.6)를 크게 앞서 나가며 고급 경쟁 수학 능력을 입증합니다.
실제 코딩 성능: LiveCodeBench v6에서 51.8을 기록하며 Kimi K2 (48.9)와 DeepSeek-V3-0324 (45.2)를 능가하며 실무 시나리오에서 강력한 프로그래밍 능력을 입증합니다.
우수한 대화 성능: Arena-Hard v2에서 79.2를 기록하면서 DeepSeek-V3 (66.1) 및 Qwen3-235B-A22B Non-thinking (52.0)를 능가하며, 복잡하고 개방형 작업에서 강력한 인력 선호도 정합능력을 보여줍니다.
도구 사용 및 기능 호출: BFCL-v3에서 70.9를 기록하며 Qwen3-235B-A22B Non-thinking (68.0)와 Kimi K2 (65.2)를 앞서며, 외부 도구 통합 및 API 사용에서 뛰어난 능력을 보여줍니다.
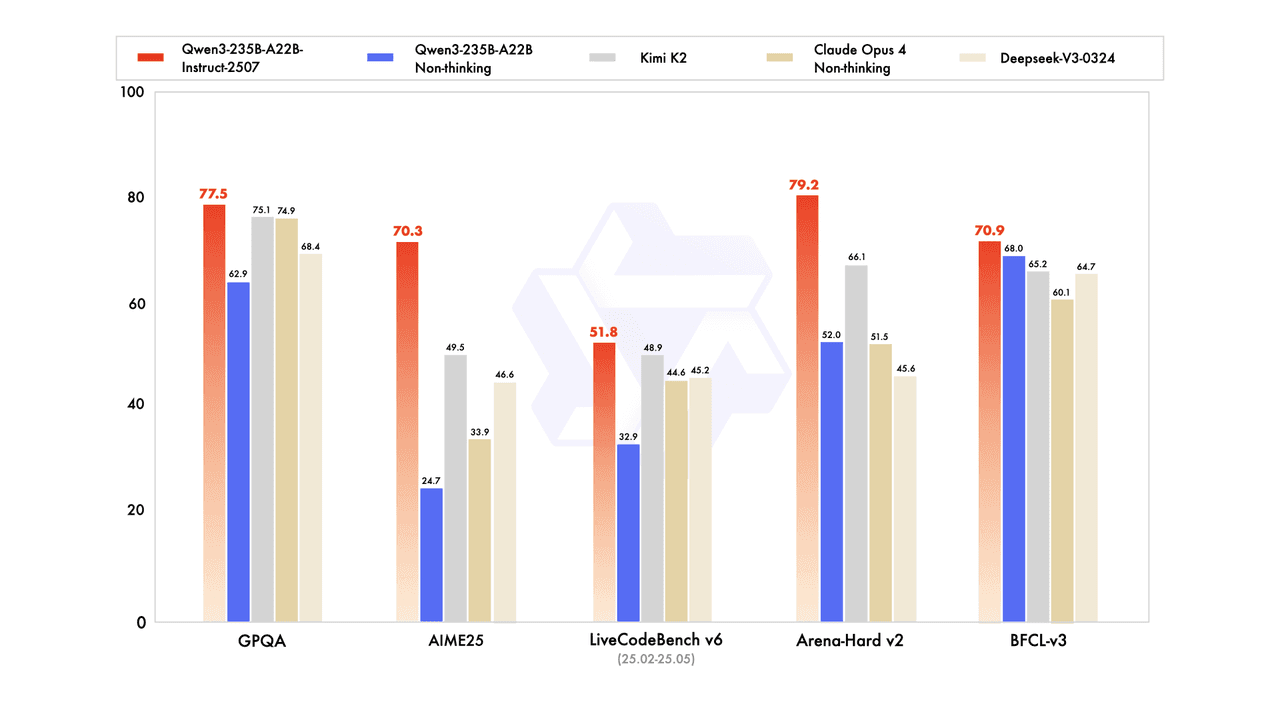
이러한 놀라운 결과는 오픈 소스 AI 개발의 중요한 이정표를 강조합니다. Qwen3-235B-A22B-Instruct-2507는 여러 벤치마크에서 Claude Opus 4 Non-thinking과 같은 독점 모델을 능가할 뿐만 아니라 오픈 소스 모델이 새로운 능력의 정점에 도달했음을 보여줍니다.
즉시 시작하세요
탐험: Qwen3-235B-A22B-Instruct-2507를 SiliconFlow Playground에서 시도해보세요.
통합: OpenAI 호환 API를 사용하십시오. SiliconFlow API 문서에서 전체 API 사양을 탐색하십시오.
지금 SiliconFlow에서 사용해보고 이 강력한 기능을 직접 탐색해보세요!
