目次

Qwenは、フラッグシップモデルQwen3-235B-A22B Non-thinkingのアップグレードバージョンであるQwen3-235B-A22B-Instruct-2507をリリースしました。これにより、オープンソースドメインにおいて大きな進歩を遂げ、一般的な機能と優れた推論性能が向上し、SiliconFlowで利用可能になりました。
この最先端のModelは、指示のフォロー、論理的推論、数学、コーディング、およびツールの使用において大幅な改善をもたらします。包括的なベンチマークによれば、Kimi-K2やDeepSeek-V3-0324といった先進的なオープンソースモデル、およびClaude-Opus4-Non-thinkingのようなプロプライエタリモデルを凌駕します。企業アプリケーションの構築、高度な研究の実施、多言語コンテンツの作成、インテリジェントアシスタントの開発など、さまざまなタスクにおいてこのModelは卓越したパフォーマンスを発揮します。
SiliconFlowのQwen3-235B-A22B-Instruct-2507 APIを使用すると、以下のことが期待できます:
高速推論: 低遅延と高スループットに最適化。
コスト効率の高い価格設定: $0.35/M tokens(Input)および$1.42/M tokens(Output)。
拡張されたコンテキストウィンドウ: 複雑なタスクに向けた256Kのコンテキストウィンドウ。
強化された機能と優れた性能
更新されたQwen3-235B-A22B-Instruct-2507は、SiliconFlowで以下の主要な強化を備えています:
強化された一般的な機能: 指示のフォロー、論理的推論、Text理解、数学、科学、コーディング、ツールの使用が向上しました。
ユーザーの整合性向上: 主観的でオープンエンドなタスクにおいて、ユーザーの好みにより正確に整合し、より有益で高品質な応答を可能にします。
多言語の知識拡張: 複数の言語における長尾の知識のカバー範囲が大幅に向上し、専門的、特定のドメイン、あまり一般的でない情報も含まれています。
拡張されたコンテキスト理解: 256Kの長いコンテキスト理解能力。
これらの機能は包括的なベンチマーク評価で明確に示されており、Qwen3は先進的な競合を一貫して上回っています:
高度な科学的推論: GPQAで77.5を記録し、Kimi K2(75.1)とClaude Opus 4 Non-thinking(74.9)を上回り、大学院レベルの科学的推論と複雑な問題解決能力を示しています。
数学的問題解決: AIME25で70.3を記録し、Kimi K2(49.5)とDeepSeek-V3-0324(46.6)を大きく上回り、先進的な競技数学のスキルを証明しています。
リアルワールドのコーディング性能: LiveCodeBench v6で51.8を記録し、Kimi K2(48.9)とDeepSeek-V3-0324(45.2)を上回り、実用シナリオでの強力なプログラミング能力を確認しています。
優れた会話性能: Arena-Hard v2で79.2を記録し、DeepSeek-V3(66.1)とQwen3-235B-A22B Non-thinking(52.0)を凌駕し、複雑でオープンエンドなタスクにおいて優れた能力と人間の好みに沿った強力な整合性を確認しています。
ツールの使用と関数呼び出し: BFCL-v3で70.9を記録し、Qwen3-235B-A22B Non-thinking(68.0)とKimi K2(65.2)をリードし、外部ツールの統合とAPIの使用における先進的な能力を示しています。
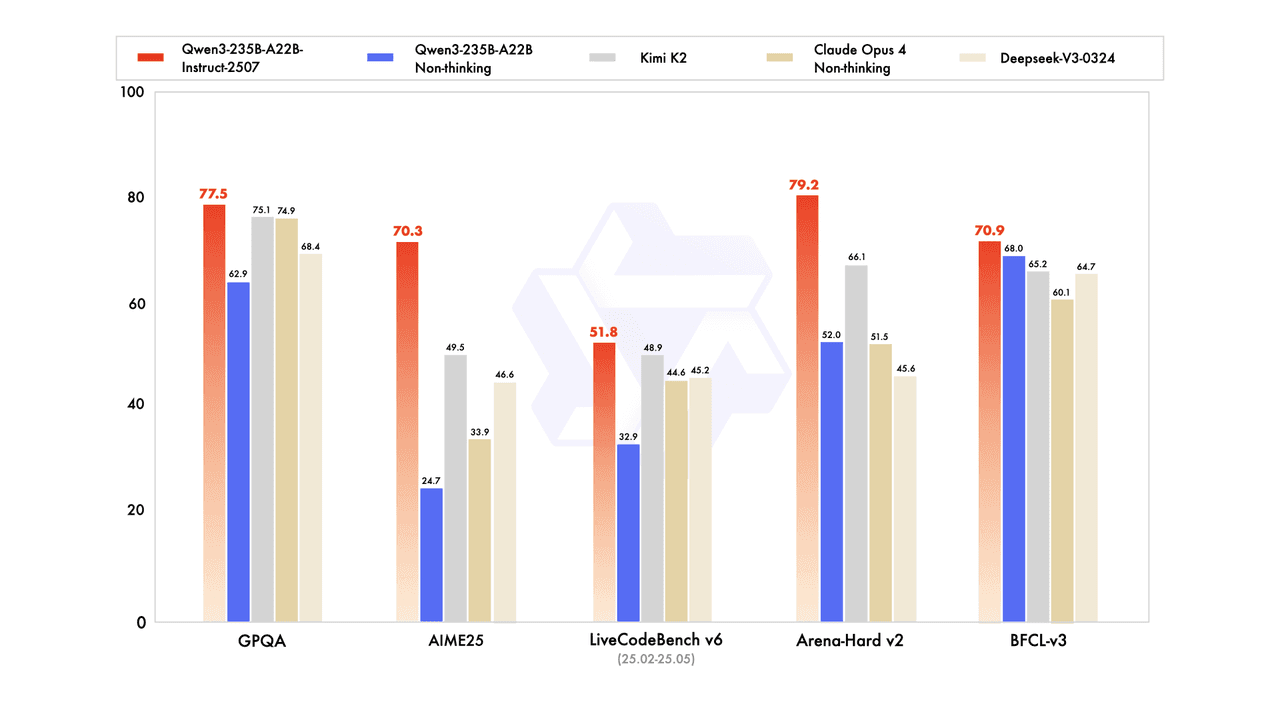
これらの印象的な結果は、オープンソースAI開発において重要なマイルストーンを強調しています。Qwen3-235B-A22B-Instruct-2507は、複数のベンチマークでプロプライエタリモデルであるClaude Opus 4 Non-thinkingを上回るだけでなく、既存のモデルをも凌駕し、オープンソースモデルが新たな能力の高みへと到達していることを示しています。
すぐに始めましょう
探索: Qwen3-235B-A22B-Instruct-2507をSiliconFlow Playgroundで試してみてください。
統合: OpenAI互換APIを使用します。SiliconFlow API Documentationで完全なAPI仕様を探索してください。
今すぐSiliconFlowでお試しいただき、これらの強力な機能を直接体験してください!
