
目次

## はじめに
*注意: これはQwQの発音です: /kwju:/ 、"quill"という単語に似ています。*
人工知能の急速に進化する分野では、推論モデルが技術革新の魅力的な最前線として浮上しています。これらのAIシステムは、人間のような推論能力をシミュレートし、問題解決と意思決定の限界を押し広げることを目的としています。エキサイティングな開発の最前線に立っている[Qwen Team](https://qwenlm.github.io/)は、[Alibaba Cloud](https://www.alibabacloud.com/en/solutions/generative-ai/qwen?_p_lc=1)からQwQ (Qwen with Questions) を公開しました - AIの推論と分析能力を革新することを約束したオープンソースの実験的研究Modelです。
## Modelの仕様
QwQ-32B-Previewは、現在のAIエコシステムで際立つ印象的な技術仕様を備えた洗練されたAI Modelです。トランスフォーマーアーキテクチャに基づいて構築されたこのModelは、RoPE (Rotary Position Embedding)、SwiGLUアクティベーション、RMS正規化、Attention QKVバイアスなどの先進技術を組み込んでいます。32.5億のパラメーター(31.0億ノン-Embedding)を持ち、64層で構成されており、Q用の40ヘッドとKV用の8ヘッドを備えた高度なアテンションメカニズムを活用しています。
QwQの最も注目すべき特徴の1つは、その広範なコンテキスト長で、32,768 tokensをフルサポートすることです。この広範なコンテキストウィンドウにより、Modelは複雑な推論タスクにおいて一貫性と深みを維持することができ、多くの既存Modelよりもより洗練された包括的な応答を可能にします。
## 素晴らしいパフォーマンスメトリクス
QwQ Modelは、さまざまなベンチマークで非常に優れたパフォーマンスを示し、OpenAIの提供といった著名なModelに匹敵する競争力のある推論AIとしての地位を築きました。そのパフォーマンスメトリクスは特に注目に値します:
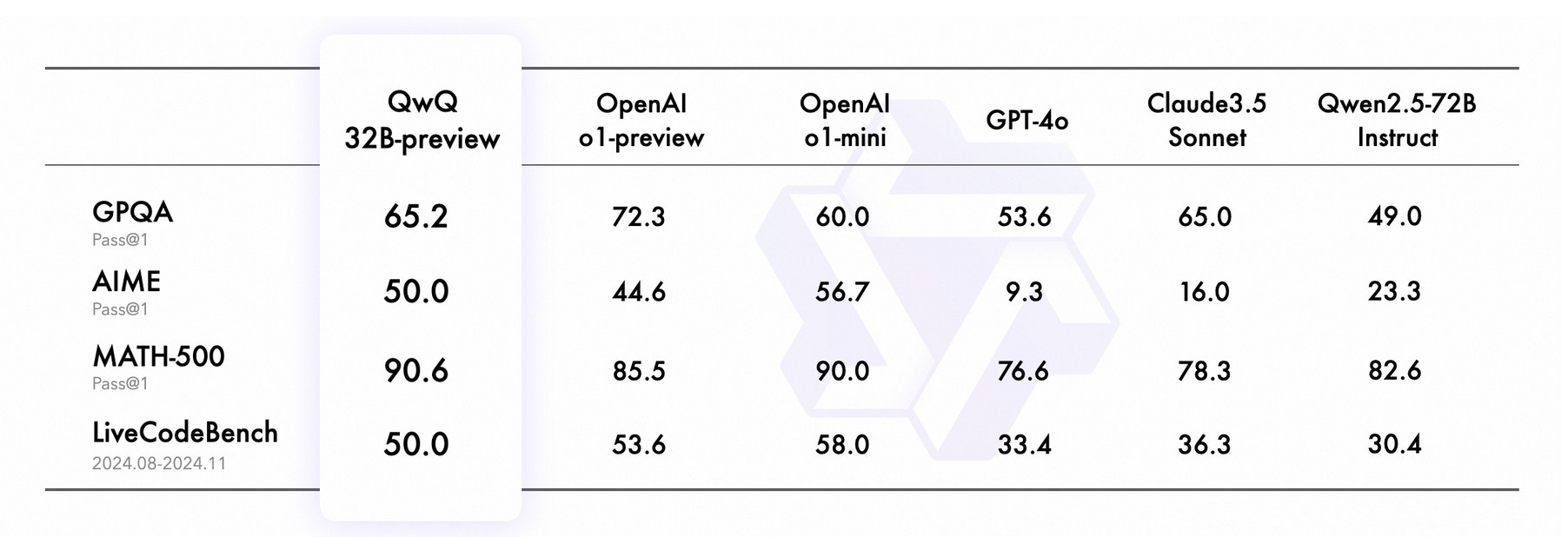
さまざまなベンチマークにおけるQwQ 32B-previewのパフォーマンスは、さまざまな分野での多用途性と強さを示しています。大学院レベルの質疑応答(GPQA)ベンチマークでは、QwQは65.2%という印象的なスコアを達成しました。この結果はClaude3.5 Sonnet(65.0%)と競争できますが、OpenAI o1-previewの先行する72.3%のパフォーマンスには及びません。それにもかかわらず、QwQの達成は科学的推論におけるその先進的能力を強調し、この領域で複雑な質問に対処するための信頼できるツールとなっています。
数学的問題解決においては、QwQはAIMEベンチマークで50.0%を本当に達成し、数学に焦点を当てた推論へのバランスの取れたアプローチを示しています。しかし、MATH-500でのパフォーマンスは特に優れており、驚異的な90.6%に達しました。このスコアは、GPT-4oなどの他のModelを凌駕し、多様なトピックにわたる高度な数学的問題解決でのその熟練度を証明しています。
QwQはまた、プログラミングタスクでも強力な結果を出し、LiveCodeBenchベンチマークで50.0%をスコアしました。このメトリックは、実際のコードシナリオを効果的に処理する能力を反映しています。問題を解釈し解決するその一貫した能力は、汎用性のあるプログラミングアシスタントとしての潜在力を強調しています。
全体として、QwQのパフォーマンスは、数学と科学的推論における際立った能力を持つバランスの取れたModelを明らかにしています。複雑なクエリに対するその精度と適応性を示す「Strawberry Question」のような難しい質問に答える能力は、さらなる改善の余地があるにもかかわらず、競争の激しいAI Modelの風景において強力な競争者であり、広範な応用と実用的な利用を提供しています。
## 高度な推論能力
QwQを真に際立たせるものは、その高度な推論方法論です。Modelは単に答えを提供するだけではなく、複雑な推論プロセスに関与します。深い内省を伴う複雑な思考プロセスを構築し、多段階推論を実行する能力を示しています。これには以下が含まれます:
* 自らの仮定を問い直す
* 思慮深い自己対話に参加する
* 推論プロセスの各ステップを分析する
このメタ認知的アプローチにより、QwQ Modelはより洗練され反射的な応答を生成し、従来の言語モデルよりも人間に近い推論を模倣します。
## コミュニティからの洞察
最近のYouTubeビデオ「Yup, QwQ is CRACKED: Prompt Chaining with Qwen and QwQ reasoning model (Ollama + LLM)」は、QwQの能力とその可能性のアプリケーションへの実世界の洞察を提供します。このビデオはQwQのModelの強さと限界の両方を探求し、その実装に関する実用的な視点を提供しています。
### 1. プロンプトチェイニング: ゲームを変える技術
ビデオで最もエキサイティングな開発の1つは、プロンプトチェイニングの概念です。この革新的な技術は、1つのプロンプトのOutputを別のプロンプトのInputとして使用し、AIインタラクションをより洗練され微妙なものにすることを含みます。YouTuberはこの手法をOllama Qwen 2.5コーダーModelを使用して実演し、連続プロンプトがAIのパフォーマンスを大幅に向上させる方法を示しました。
### 2. 実用例
ビデオはまた、プロンプトチェイニングのいくつかの実用的な応用を、特にコンテンツ生成に焦点を当てて強調しています。たとえば、SEO最適化されたタイトルを生成する2ステッププロセスを示しました。このアプローチはOutputの質を向上させるだけでなく、Modelが複雑で多段階の推論作業に従事する能力を示しています:
* 最初のプロンプトは推論エンジンとして機能し、潜在的なタイトルを生成することができます
* 二番目のプロンプトは、これらのタイトルを抽出し、軽量Modelを使用して精緻化します
このビデオは、QwQのようなソリューションがAI開発における有望な進路を表していることを示唆し、ローカルAIモデルに関する希望に満ちた見通しで締めくくられています。スピーカーは、2025年の予測を含む将来のコンテンツを示唆し、コミュニティの参加とプロンプトエンジニアリング技術の継続的な探求を奨励しています。
## 限界と考慮事項
その印象的な能力にもかかわらず、QwQは事実上まだ実験的なプレビューリリースであり、ユーザーと研究者が注意すべきいくつかの重要な制限が存在します:
**言語混合** が課題であり、Modelが予期せず言語を切り替えることがあり、応答の明確さに影響を与えることがあります。また、**再帰的推論ループ**に入る傾向があり、決定的な答えに達することなく長い応答を生成する可能性があります。
**安全性と倫理的考慮事項** は、AIの世界で特に重要性を持っています。Modelは信頼性と安全な性能を確保するための強化された安全対策を必要とします。ユーザーは、展開中に注意を払い、そのOutputを慎重に評価することが推奨されます。同時に、QwQは数学とコーディングの分野で優れているにもかかわらず、常識的な推論や微妙な言語理解のようなベンチマークで改善の余地があります。
## QwQへのアクセス
この画期的なModelを探求することに興味のある研究者と開発者は、以下の複数のプラットフォームを通じてアクセスすることができます:
* **GitHub:** [https://github.com/QwenLM/Qwen2.5](https://github.com/QwenLM/Qwen2.5)
* **HuggingFace Model:** [https://huggingface.co/Qwen/QwQ-32B-Preview](https://huggingface.co/Qwen/QwQ-32B-Preview)
* **ModelScope Model:** [https://modelscope.cn/models/Qwen/QwQ-32B-Preview](https://modelscope.cn/models/Qwen/QwQ-32B-Preview)
* **HuggingFace Demo:** [https://huggingface.co/spaces/Qwen/QwQ-32B-preview](https://huggingface.co/spaces/Qwen/QwQ-32B-preview)
## 結論
Qwen Teamの反省的な結論は、この革新的な試みの精神を捉えています: "この旅がどこに導くのか正確にはわかりませんが、揺るぎない決意で進み続けます - 真実、知性、そして素晴らしさの領域へ向かって。” AIが進化し続ける中で、QwQ-32B-previewのようなModelは、より知的で反省的で微妙な人工推論システムへの重要なステップを表しています。完璧ではありませんが、AIがより人間に近い認知プロセスに関与できる未来を垣間見ることができます。
最後になってしまいますが、このエキサイティングな技術的フロンティアの最新情報にご期待ください!
