Table of Contents

TL; DR: GLM-5.1 is now available on SiliconFlow. This next-generation flagship model achieves state-of-the-art performance on SWE-Bench Pro (58.4) and can work autonomously on complex tasks for up to 8 hours. With overall capabilities aligned with Claude Opus 4.6 and significantly stronger long-horizon execution, GLM-5.1 delivers production-grade results through sustained optimization over hundreds of rounds. Integrate SiliconFlow's API into your workflow now and unlock next-level efficiency.
Designed for Long-horizon Tasks
GLM-5.1, Z.AI's latest flagship model designed for long-horizon agentic engineering, is now officially live on SiliconFlow.
This release brings unprecedented sustained execution capabilities and significantly stronger coding performance, enabling developers to achieve autonomous task completion—from planning and execution to iterative optimization and delivery—with greater efficiency and reliability. GLM-5.1 sets a new benchmark for complex systems engineering and real-world development workflows.
Through SiliconFlow's GLM-5.1 API, You Can Get:
Competitive Pricing + Cache Support: $0.26 / $1.40 / $4.40 per 1M tokens (Cached Input / Input / Output)
SOTA on SWE-Bench Pro (58.4): outperforming models like GPT-5.4 and Claude Opus 4.6
205K Context Window: Perfect for long documents, complex reasoning, and extended agentic tasks requiring sustained context over hours-long sessions
Seamless Integration: Instantly deploy via SiliconFlow's OpenAI/Anthropic-compatible API, or plug into your existing stack through Claude Code, Gen-CLI and Cline, and also available through OpenRouter
Whether you're building autonomous coding agents, complex system engineering tools, or long-horizon optimization pipelines, SiliconFlow's GLM-5.1 API delivers an ideal foundation.
Key Features & Benchmark Performance
Most models excel at quick initial responses but plateau rapidly, exhausting their repertoire within minutes and failing to improve even when given more time. GLM-5.1 resolves this through iterative optimization architecture, achieving both leading benchmark scores and sustained productivity over hours-long sessions.
Unlike previous models that apply familiar techniques for quick gains then stall, GLM-5.1 breaks complex problems down, runs experiments, reads results, and identifies blockers with real precision—revisiting its reasoning and revising its strategy through repeated iteration.
Highlights
Balanced General Capability and Coding Performance: GLM-5.1 ranks among the world's top-tier models
State-of-the-Art Agentic Coding Performance: Achieves 58.4 on SWE-Bench Pro, outperforming GPT-5.4 (57.7), Claude Opus 4.6 (57.3), and all other frontier models
Long-Horizon Autonomous Execution: Can work continuously on a single task for up to 8 hours, completing the full loop from planning to delivery
Sustained Optimization: Maintains effectiveness over hundreds of rounds and thousands of tool calls, with performance improving the longer it runs
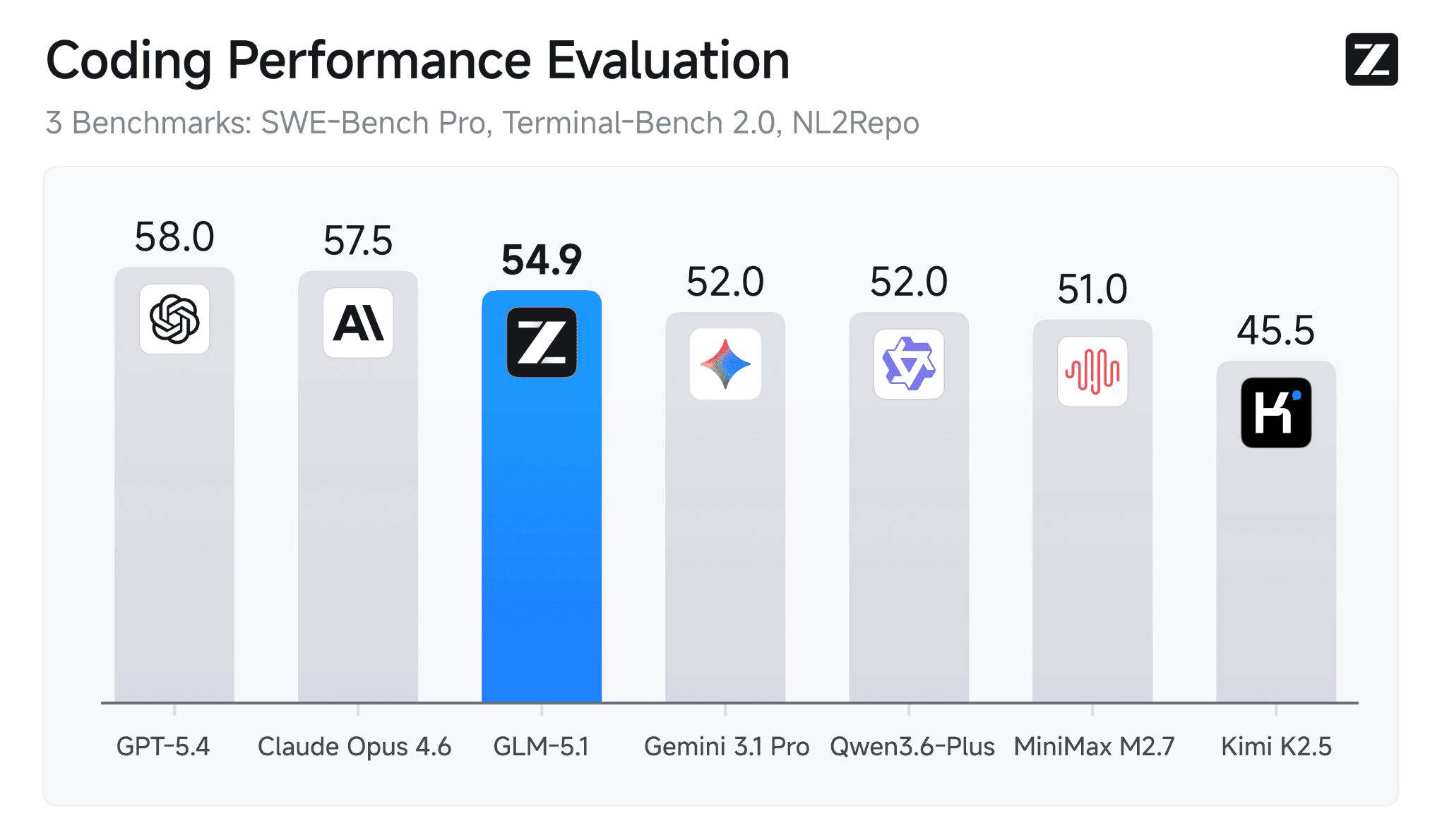
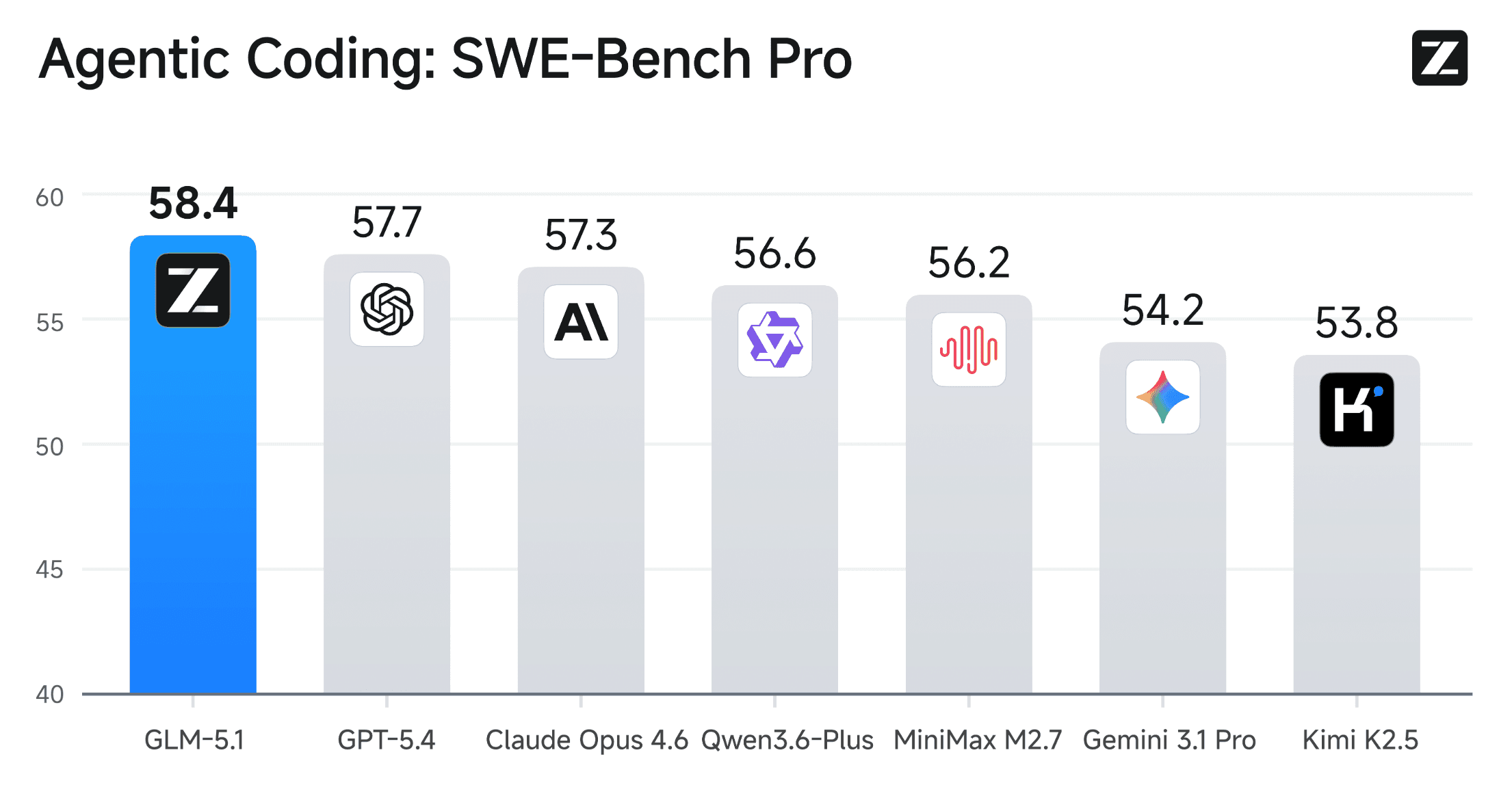
Benchmark results confirm these advantages:
SWE-Bench Pro: 58.4 (state-of-the-art, surpassing all frontier models)
NL2Repo (Repository Generation): 42.7 (significantly ahead of GLM-5's 35.9)
Terminal-Bench 2.0: 63.5 with Terminus-2, 69.0 with Claude Code (substantial improvement over GLM-5's 56.2)
CyberGym: 68.7 (leading performance in cybersecurity tasks)
BrowseComp: 68.0 without context management, 79.3 with context management
GLM-5.1 consistently outperforms previous-generation models including GLM-5, GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro in agentic engineering tasks, complex coding problems, and long-running development workflows with multiple stages and strong interdependencies.
Technical Innovations
GLM-5.1 introduces long-horizon agentic architecture enhancements such as:
Iterative Reasoning Framework: Enables the model to sustain optimization over hundreds of rounds by continuously revisiting its reasoning, running experiments, analyzing results, and revising strategy—rather than exhausting its repertoire in the first few attempts
Enhanced Judgment for Ambiguous Problems: Handles complex, poorly-specified problems with better decision-making, staying productive over longer sessions where other models would plateau
Closed-Loop Optimization: Completes the full engineering cycle from planning and execution to testing, fixing, and delivery autonomously, without requiring constant human intervention
Asynchronous RL Infrastructure: Builds on GLM-5's "slime" training system, enabling more fine-grained post-training iterations that improve both first-pass performance and sustained execution capability
All these make GLM-5.1 uniquely suited for real-world engineering scenarios where problems are ambiguous, requirements evolve, and solutions require sustained iteration.
Real-World Applications
GLM-5.1 empowers developers and businesses to create cutting-edge solutions for:
Autonomous Software Engineering: Hand GLM-5.1 a complex coding objective and let it run a complete "experiment–analyze–optimize" loop autonomously over hours, rather than orchestrating dozens of short-lived tool calls manually. The model can build a complete Linux desktop environment from scratch in 8 hours
Complex System Optimization: Deploy GLM-5.1 on vector database performance tuning, infrastructure configuration, or architectural refactoring tasks where it can perform hundreds rounds of autonomous iteration, improving performance through persistent experimentation and adjustment
Long-Horizon Development Workflows: Integrate GLM-5.1 into Claude Code, OpenClaw, Hermes Agent or custom agentic frameworks for multi-stage development tasks involving research, implementation, testing, debugging, and deployment—where sustained context and iterative refinement are critical to success
From startup engineering teams to enterprise DevOps pipelines, the model helps teams move faster and tap into entirely new AI-powered opportunities by handling the full complexity of real-world engineering work autonomously.
Get Started Immediately
Explore: Try GLM-5.1 in the SiliconFlow playground
Integrate: Use our OpenAI-compatible API. Explore the full API specifications in the SiliconFlow API documentation
Join our Discord community now →
Follow us on X for the latest updates →
Explore all available models on SiliconFlow →
