
目錄

## 介紹
在不斷發展的數字技術領域中,視頻內容已成為溝通、娛樂和教育的基石。認識到這一領域的巨大潛力和創新需求,[騰訊](https://www.tencentcloud.com/products/ivh) 作為全球技術和數字解決方案的領導者,驕傲地推出了 [Hunyuan Video](https://hunyuanvideoai.com/)。這一尖端的開源平台旨在革新我們創建、互動和傳播視頻內容的方式。在這篇博客中,我們將深入探討 Hunyuan Video 的功能、優勢以及其變革性影響。
## Hunyuan Video 的關鍵功能
### 1. AI 驅動的視頻編輯
* **智能編輯工具:** Hunyuan Video 利用先進的 AI 算法提供智能視頻內容編輯建議。這些工具可以分析視頻素材,推薦最佳的剪切點,確保最終產品平滑且吸引人。
* **建議的過渡效果:** AI 可以建議場景之間具有視覺吸引力的過渡效果,增強視頻的整體流暢性和美感,包括淡入、淡出、溶解及其他使視頻更具動態的效果。
### 2. 雲渲染與部署
* **快速渲染:** Hunyuan Video 使用基於雲的渲染技術,以快速處理和完成視頻內容。這消除了對強大本地硬體的需求,並加快了周轉時間。
* **跨平台部署:** 該工具支持視頻內容在多個平台上的無縫部署,包括社交媒體、流媒體服務和網絡。這確保您的內容不論觀眾選擇在哪裡觀看都能輕鬆訪問。
### 3. 實時互動流媒體
* **低延遲流媒體:** Hunyuan Video 提供實時流媒體服務,並將延遲降至最低,確保現場活動流暢和不間斷。這對於保持與觀眾的互動和參與至關重要。
* **多用途應用:** 實時互動流媒體非常適合各種應用,包括虛擬會議、現場音樂會、教育課程和網絡研討會。它為內容創作者提供了一個靈活且動態的平台,以實時連接其受眾。
## Hunyuan Video 架構揭秘
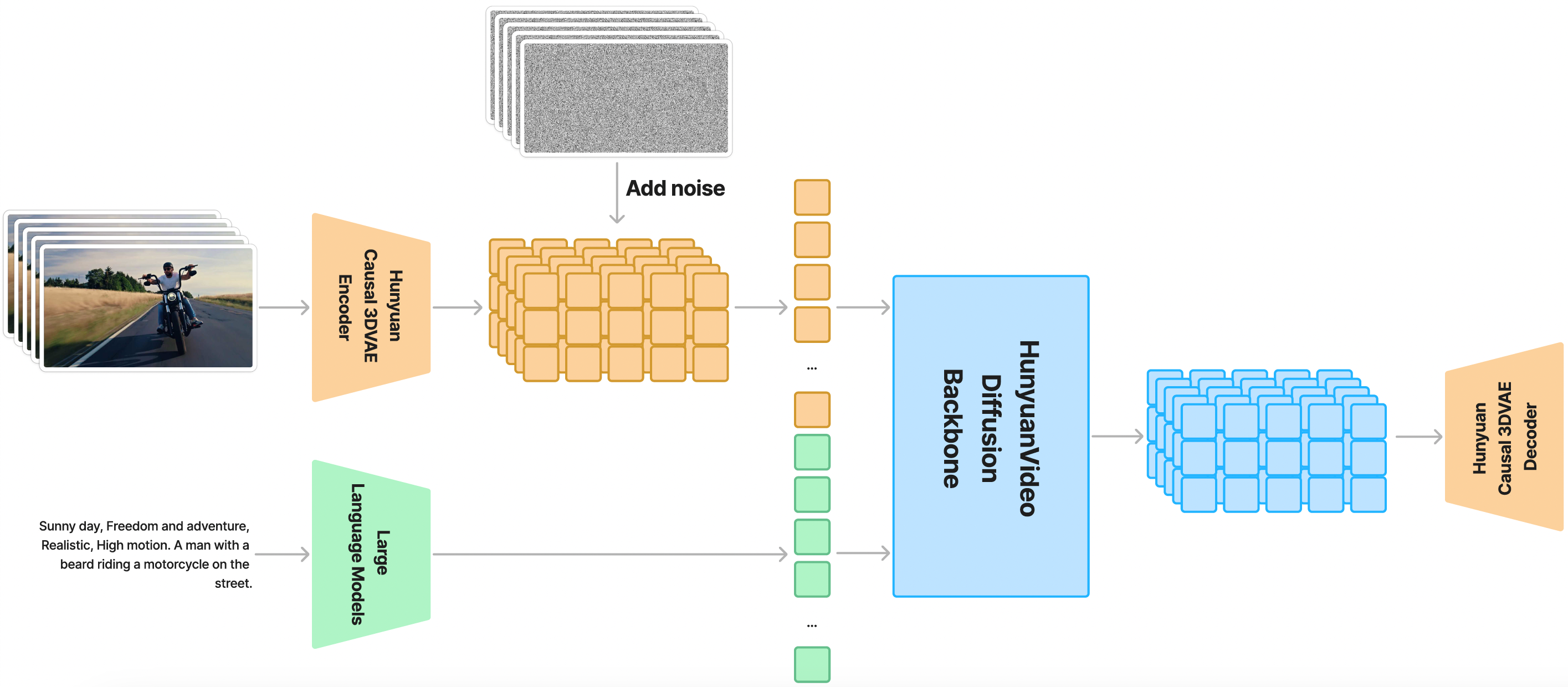
從此圖中,我們可以了解到 Hunyuan Video 通過因果 3D VAE 訓練在一個空間-時間壓縮的潛在空間中,文本提示通過大型語言模型處理並作為條件輸入。此圖中的示例將高斯噪聲和條件輸入作為輸入,生成輸出潛在。然後,該潛在輸出使用 3D VAE 解碼器解碼成圖像或視頻。
### 1. 統一的圖像和視頻生成架構
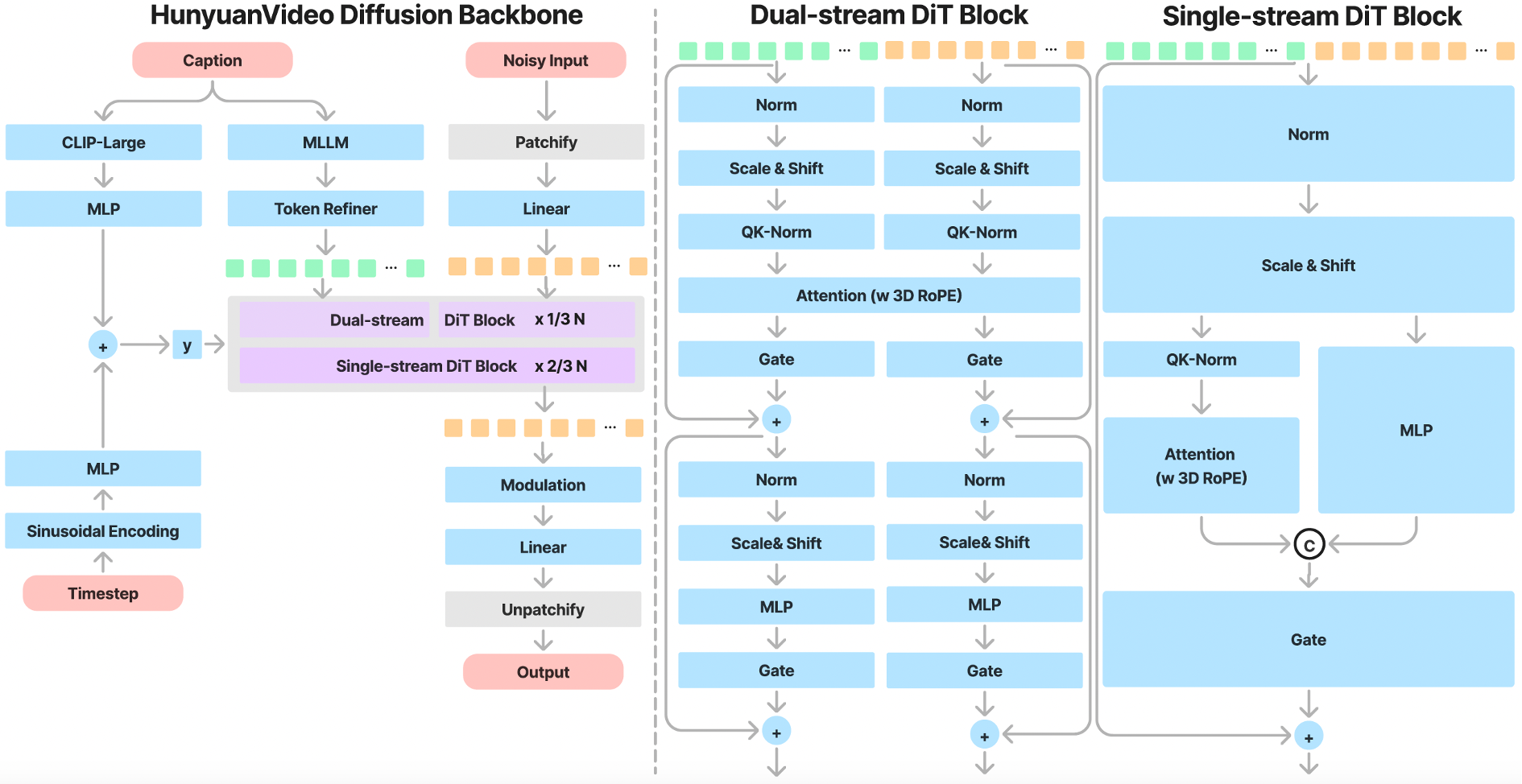
* **全注意力機制的變壓器設計:** 支持統一的圖像和視頻生成。
* **雙流到單流混合模型:** **雙流階段:** 視頻和文本令牌通過多個變壓器塊分別處理。
* **單流階段:** 連接的令牌經過後續的變壓器塊以進行有效的多模態融合,捕捉視覺和語義信息之間的複雜交互。
### 2. MLLM 文本編碼器:增強多模態對齊
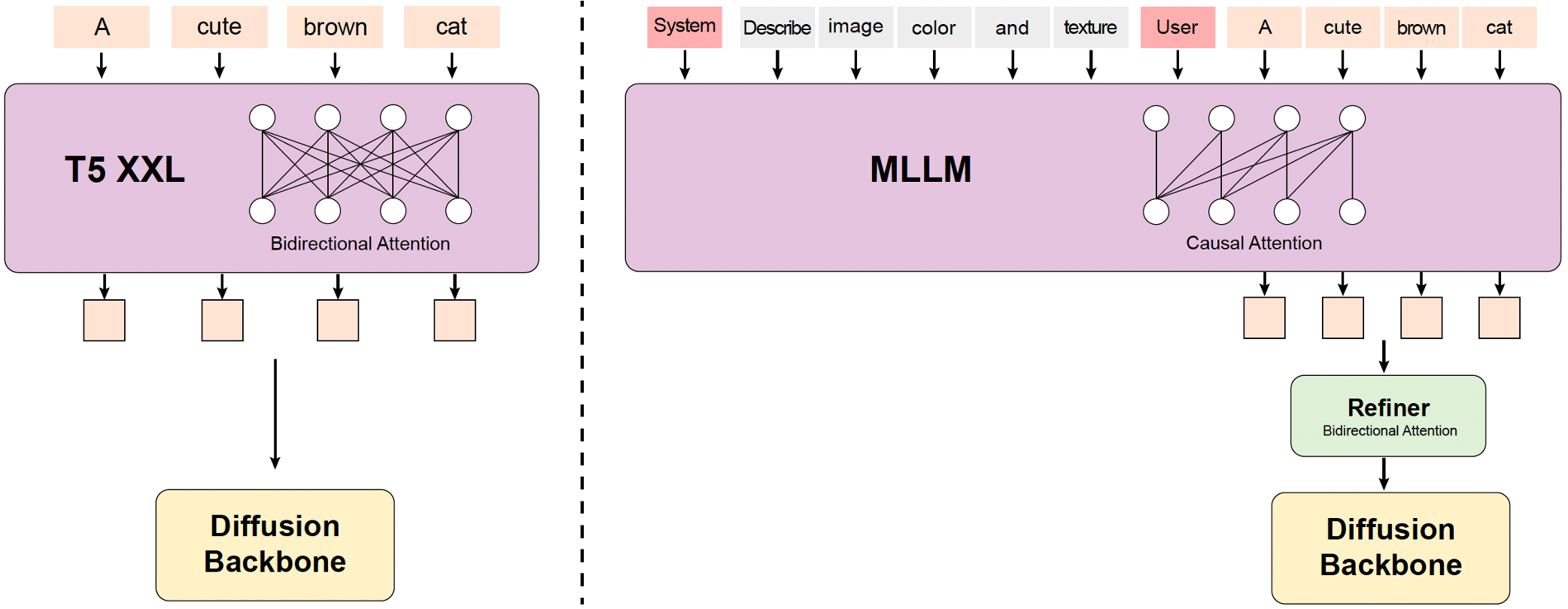
* **僅解碼器結構:** 與傳統編碼器(如 CLIP、T5-XXL)相比,提供更好的圖像文本對齊和更優的圖像細節描述。
* **零樣本學習能力:** 遵循系統指令附加用戶提示,增強關鍵信息的註重。
* **雙向令牌細化器:** 引入以增強文本特徵,用於更好地引導擴散模型。
### 3. 3D VAE 用於高效壓縮

* **CausalConv3D:** 訓練 3D VAE 將視頻和圖像壓縮到一個緊湊的潛在空間。
* **壓縮比:** 視頻長度(4x)、空間(8x)和通道(16x)。
## 深入探討:釋放 Hunyuan 模型的力量
YouTuber 首先介紹道,Hunyuan 模型具備令人印象深刻的規模,擁有 130 億個參數,在生成高解析度視頻方面超越了競爭對手如 Runway Gen 3 和 Luma 1.6。這一巨大的參數數量使模型能夠生成極其詳細和真實的內容,使其成為內容創作者的首選。此外,Hunyuan 的先進多模態特徵的文本到視頻生成可以創建更具沉浸感和細節的內容。通過結合文本、圖像和其他數據類型,Hunyuan 可以生成不僅在視覺上令人驚嘆且具有豐富上下文和細節的視頻,提供了一個全新的創造性深度。
雖然該模型需要大量視頻內存(45-60 GB),但此 YouTuber 提供了一份兼容 GPU 的詳細安裝指南,確保擁有必要硬件的人可以充分利用其功能。這使得創作者更容易設置和開始使用 Hunyuan,即使他們不是技術專家。此外,上傳短片並嘗試解析度的能力開辟了更多創造性和視頻增強的途徑,讓 YouTubers 可以推動內容的邊界。此外,Hunyuan 模型通過各種演示展示其多功能性和潛力。從夜間駕駛場景的生動細節到 YouTuber 提供的文本提示的奇幻探索,這些示例展示了該模型處理各種內容類型和風格的能力。這種多樣性使其成為任何希望創建高質量、吸引人視頻並吸引觀眾的 YouTuber 的寶貴工具。
## 基準表現:引領文本到視頻合成的前沿
HunyuanVideo 已在[這篇文章](https://arxiv.org/abs/2412.03603)中評估了五個其他領先的視頻生成模型。評估涉及使用 1,533 個文本提示來生成每個模型的視頻。然後,根據三個標準評估這些視頻:文本對齊、運動質量和視覺質量。HunyuanVideo 超過其他所有模型,特別是在運動質量方面表現優異。它在生成具有真實和平滑運動的視頻方面展示出了顯著的優勢。雖然所有模型在文本對齊方面表現出色,HunyuanVideo 還生成了{
