目錄

TL;DR: Qwen3-VL—Qwen系列中最強大的視覺語言模型—現在在SiliconFlow上可用。這次發布帶來突破性升級:卓越的文本理解與生成、多模態推理、高級空間與視頻感知、262K上下文窗口、32種語言的OCR,以及更強的代理交互。由密集與MoE架構支持,最高達235B參數,並結合Interleaved-MRoPE及DeepStack等創新技術,為多模態AI設立了新標杆。
現在,Instruct和Thinking變體均已在SiliconFlow上啟動。立即開始使用SiliconFlow的生產就緒API進行構建!
我們很高興宣布Qwen3-VL系列現在在SiliconFlow上可用。作為次世代視覺語言模型,旨在更好地看到、理解和回應世界,Qwen3-VL提供突破性能力,重新定義多模態AI。它實現了精確的视频理解、32種语言扩展的OCR,能够更好地处理罕见字符和古代文本,以及262K上下文窗口,用于超长内容分析。
SiliconFlow現在提供Instruct和Thinking版本:前者優化為高效執行,後者增強了深度推理——讓用戶能選擇最合適他們需求的模型。
通過SiliconFlow的Qwen3-VL API,您可以期待:
劃算的定價:
Qwen3-VL-30B-A3B-Instruct $0.29/M tokens(输入)和$1/M tokens(输出)
Qwen3-VL-30B-A3B-Thinking $0.29/M tokens(输入)和$1/M tokens(输出)
Qwen3-VL-235B-A22B-Instruct $0.3/M tokens(输入)和$1.5/M tokens(输出)
Qwen3-VL-235B-A22B-Thinking $0.45/M tokens(输入)和$3.5/M tokens(输出)
262K上下文窗口:支持无缝处理长篇文档及多次对话。
通過這些組合—30B與235B,Instruct與Thinking—SiliconFlow使開發者能夠選擇效率、深度與成本之間的平衡,將靈活的多模態智能引入生產行業,滿足各種規模需求。
為何Qwen3-VL很重要
大多数视觉语言模型面临权衡:广泛的能力或深度推理,但很少同时具备。一般模型在复杂逻辑上挣扎,专用模型则缺乏通用性。看到并不等于理解,理解不保证解决问题。
Qwen3-VL通过双版本方法解决了这一问题:
Instruct:优化用于广泛的日常视觉语言任务,表现可靠。
Thinking:增强了高级推理能力,能在STEM和数学方面解决复杂问题。
它们在三个关键领域共同解锁了能力:
1. 主动性
视觉代理:让AI为您导航应用程序和网站!识别UI元素,理解它们的功能,并自主执行多步任务。它还在全球基准测试中获得最高表现,例如OS World,使用工具显著提高其对精细感知任务的表现。
更好的空间理解:从绝对坐标到相对坐标的2D定位。它可以判断物体位置、视点变化和遮挡关系。它还支持3D定位,为复杂空间推理和具象AI应用铺平了道路。
设计至代码:上传截图或视频,生成可用于生产的Draw.io图表、HTML、CSS或JavaScript——让“所见即所得”的可视化编程成为现实。

2. 感知与理解
长时间段和长视频理解:所有模型本地支持262K上下文窗口,可扩展至1百万tokens。这意味着您可以输入数百页的技术文档、整本教科书,甚至是长达数小时的视频——模型会记住所有内容并准确检索细节。
扩展的OCR:支持32种语言,支持模糊/倾斜/低光图像的强劲表现,更好地处理罕见字符、古代文本和技术术语,以及改进了长文档的结构解析。
强化视觉感知与识别:通过提高预训练数据的质量和多样性,模型现在可以识别更广泛的对象——从名人、动漫角色、产品、地标,到动物和植物——覆盖了日常生活和专业“识别任何事物”的需求。
3. 数学与语言
更强的多模态推理(Thinking版本):Thinking模型特为STEM和数学推理优化。应对复杂学科问题,它能注意细节,逐步分解问题,分析因果关系,并给出合乎逻辑、有依据的答案。在推理基准测试如MathVision、MMMU和MathVista上取得不错表现。
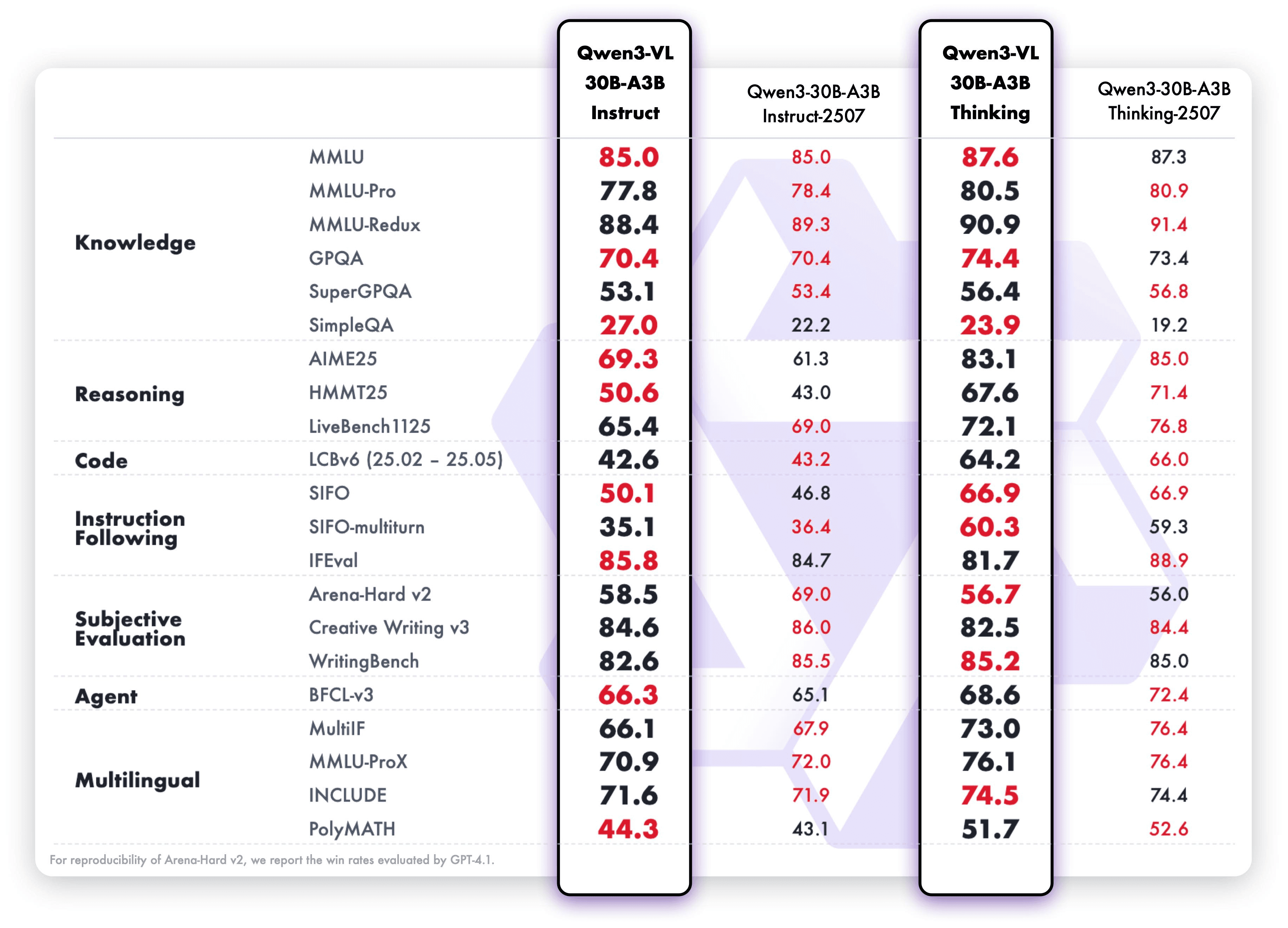
卓越的文本中心表现:Qwen3-VL在文本和视觉模态早期联合预训练中不断增强其语言能力。在文本任务上的表现可与Qwen3-235B-A22B-2507——旗舰语言模型相媲美——使其成为下一个世代的视觉语言模型的真正“文本基础,多模态强者”。

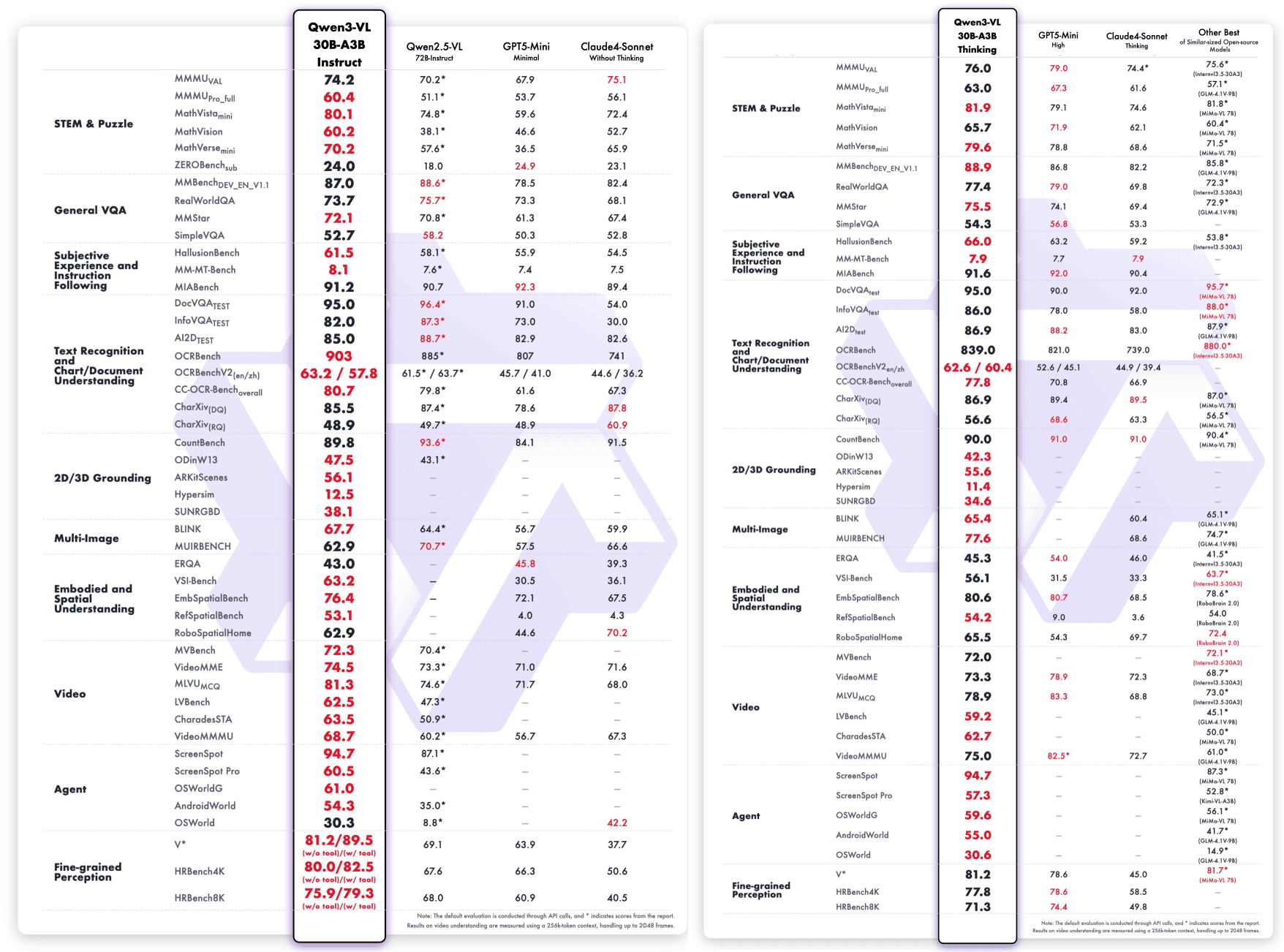
基準表現與技術架構更新
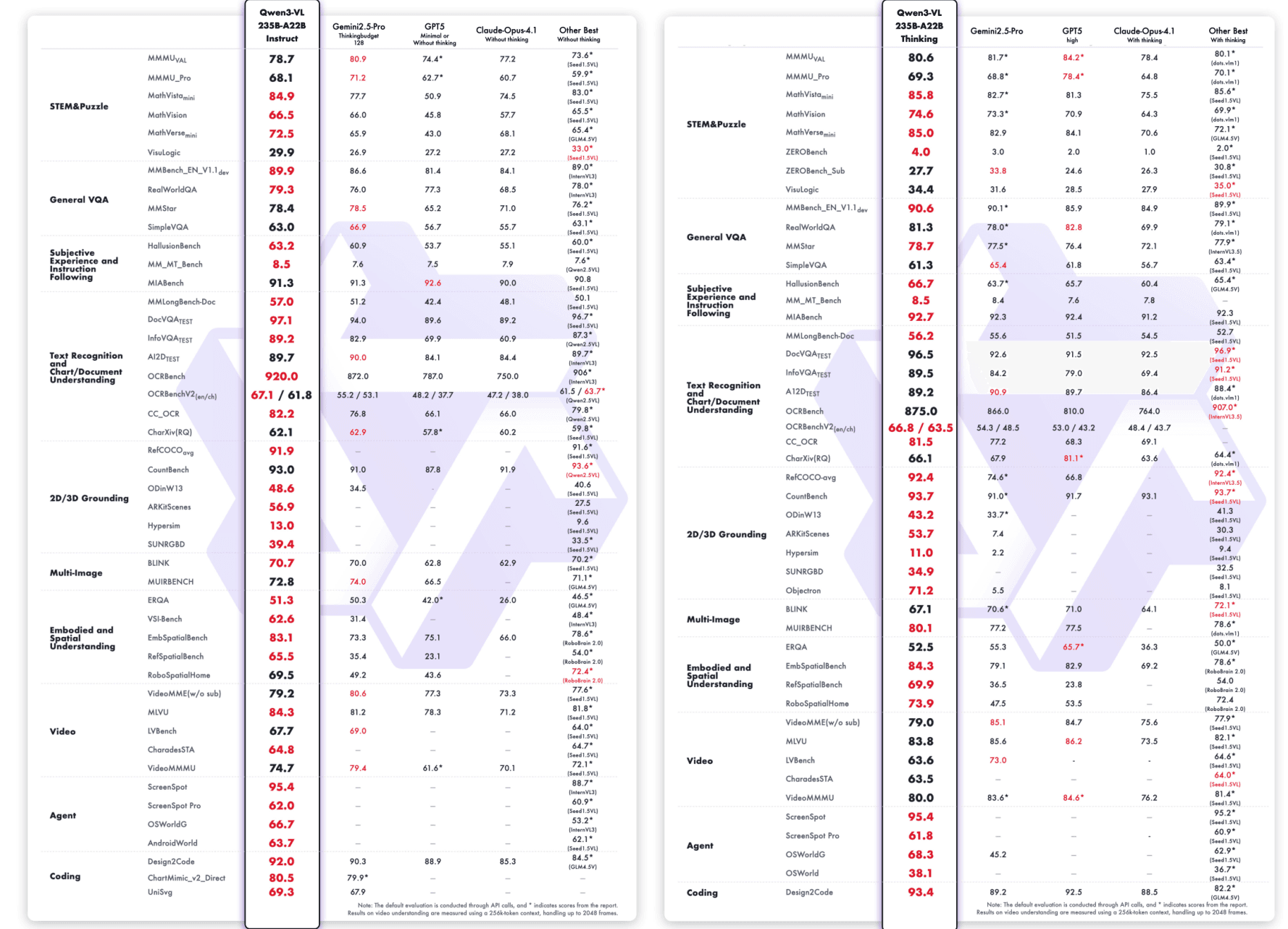
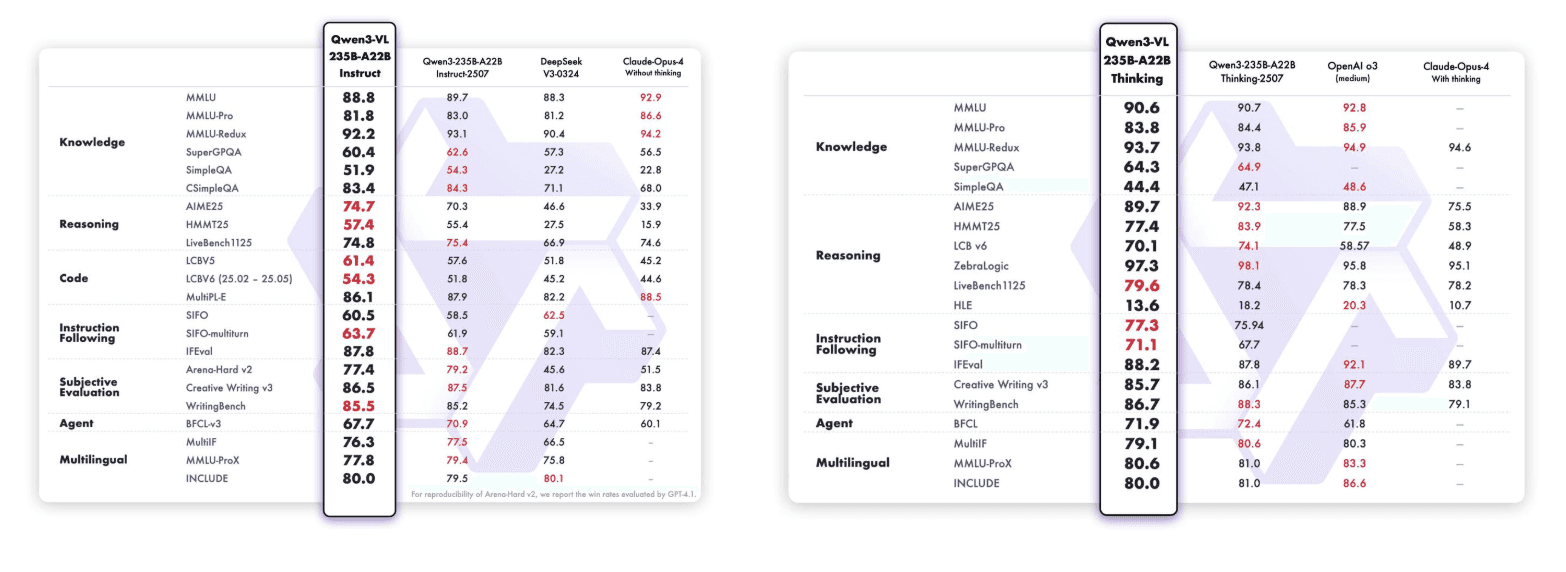
Qwen3-VL不仅展示了广泛的视觉语言技能,还在多模态和纯文本评估中表现出色。
Qwen3-VL-235B-A22B-Instruct & Qwen3-VL-235B-A22B-Thinking:
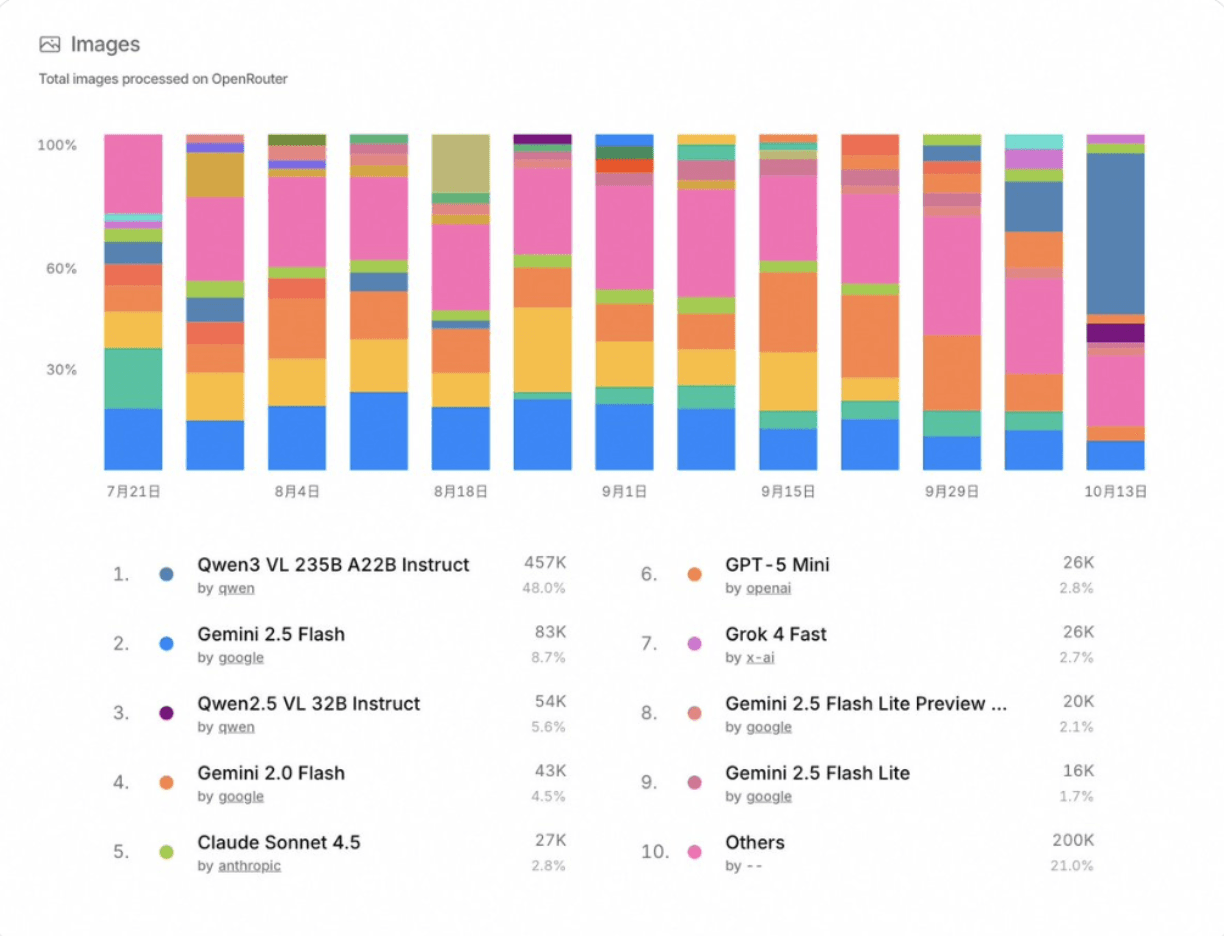
除了基準表現,Qwen3-VL-235B-A22B-Instruct也在開源社群中取得了顯著的吸引力。根据OpenRouter的最新统计(2025年10月),它在图像处理方面排名#1,占48%的市场份额,超过其他领先的多模态模型如Gemini 2.5 Flash和Claude Sonnet 4.5。
特别地,SiliconFlow还作为提供商出现在OpenRouter上,提供Qwen3-VL-235B-A22B-Instruct和其他领先模型例如DeepSeek-V3.2-Exp、GLM-4.6、Kimi K2-0905和GPT-OSS-120B,给开发者统一接入广泛的尖端模型。
Qwen3-VL-30B-A3B-Instruct & Qwen3-VL-30B-A3B-Thinking:
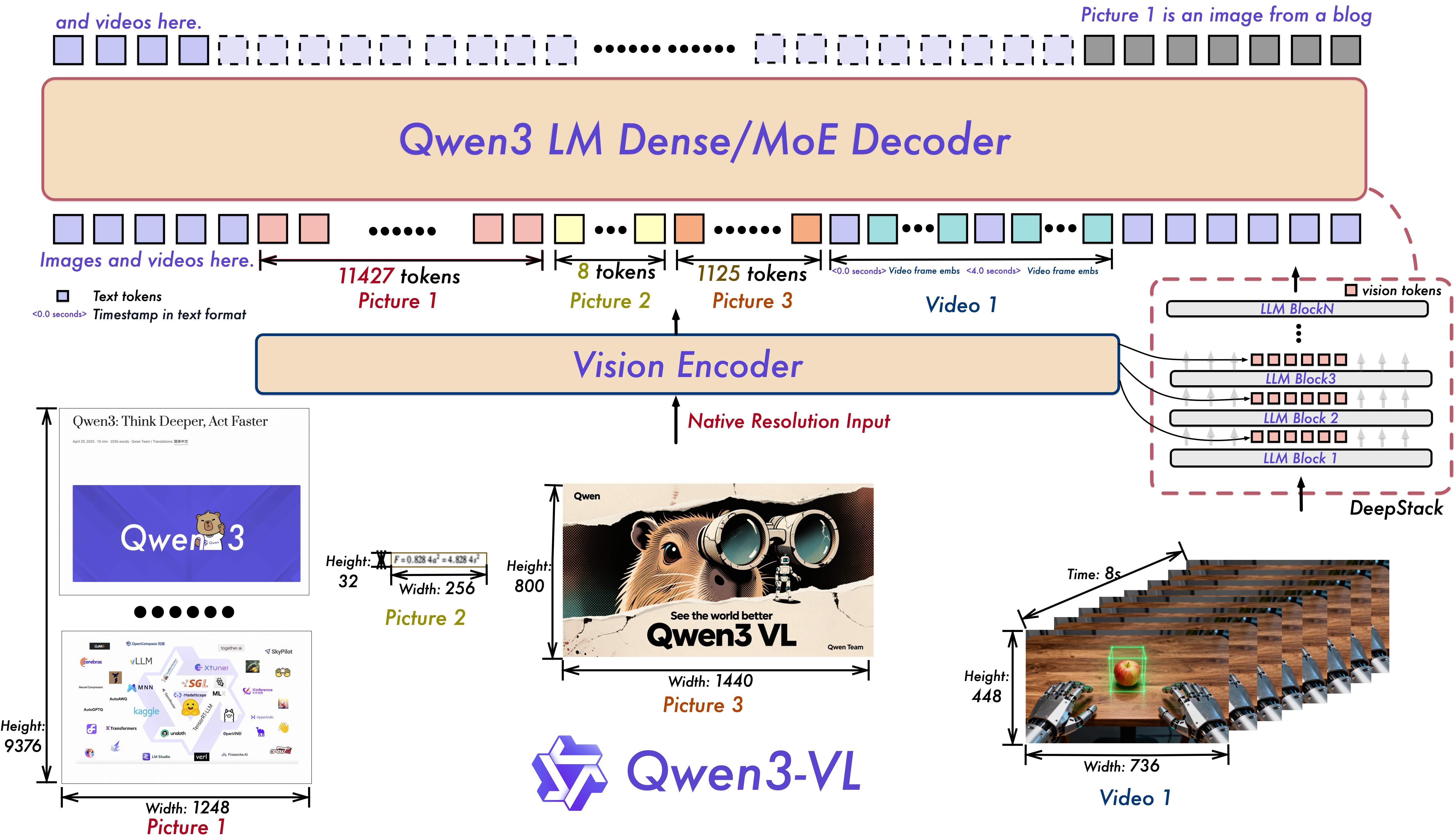
架构创新
三项核心突破推动Qwen3-VL的能力:
Interleaved-MRoPE:通过强固的位置信息嵌入,增强长时间视频推理的时间、宽度和高度的全频段分配。
DeepStack:融合多层ViT特征以捕捉细粒度细节并加强图像-文本匹配。
文本-时间戳对齐:超越T-RoPE,实现精确的时间戳事件定位,以增强视频时间建模。
实际应用场景
视频内容分析与索引:对数小时的视频进行帧准确的理解——询问“在第15分钟发生了什么?”或“总结穿红色衣服的演讲者讨论的关键主题。”适用于媒体公司、教育平台、需要高效长篇分析的内容审核。
智能文件处理:从复杂文件中提取结构化信息,支持32种语言——包括历史档案、技术手册和模糊扫描。处理整个书籍(最高可达1百万tokens),用于法律研究、学术分析或企业知识管理。
无代码开发和UI自动化:上传设计草图生成可用于生产的代码,或让视觉代理自行导航应用程序——填写表单、测试流程、执行多步骤任务。加速原型设计、QA自动化,减少人工编码时间。
STEM教育与研究:分析科学图表和数学方程,提供逐步推理。Thinking版分解复杂问题,解释因果关系,并为学生、研究人员和教育者提供有依据的答案。
立即开始
1. 探索:在Qwen3-VL系列SiliconFlow遊樂場中試用。
2. 整合:使用我們的OpenAI兼容API。在SiliconFlow API文檔中查看完整API規範。
無論您是在構建多模態代理、自動化UI工作流程,還是在分析數小時的视频,Qwen3-VL賦予您看、理解和推理的能力。
立即開始使用SiliconFlow的生產就緒API,立即將視覺智能引入您的工作流程!
