目錄

Qwen 剛剛發佈了 Qwen3-235B-A22B-Instruct-2507,這是其旗艦模型 Qwen3-235B-A22B 不思考的升級版。這代表在開源領域的一大進步,帶來加強的通用能力和卓越的推理性能,現在可以在SiliconFlow上獲得。
這款尖端模型在指令跟隨、邏輯推理、數學、編程和工具使用上提供顯著的改進。根據綜合基準測試,它的性能超過 Kimi-K2 和 DeepSeek-V3-0324 等領先的開源模型,以及 Claude-Opus4-不思考等專有模型。無論您是構建企業應用程序、進行高級研究、創建多語言內容還是開發智能助手,這款模型都能以卓越的性能處理這些任務。
使用 SiliconFlow 的 Qwen3-235B-A22B-Instruct-2507 API,您可以期待:
高速推理:優化的低延遲和高通量。
成本效益定價: $0.35/M tokens(輸入)和 $1.42/M tokens(輸出)。
擴展上下文窗口: 256K 上下文窗口以處理複雜任務。
增強能力與卓越性能
更新的 Qwen3-235B-A22B-Instruct-2507 現在在 SiliconFlow 上提供,具有以下主要增強功能:
增強的通用能力:改善了指令跟隨、邏輯推理、文本理解、數學、科學、編程和工具使用。
更好的用戶對齊:在主觀和開放性任務上更加精確地符合用戶偏好,提供更有幫助和更高質量的回應。
擴展的多語言知識:在涵蓋多種語言的長尾知識方面取得了重大進展,包括專門的領域特定和不常見的信息。
擴展的上下文理解:256K 長上下文理解能力。
這些能力在綜合基準評估中得到了充分展示,其中 Qwen3 在領先競爭對手中表現出色:
先進的科學推理: GPQA 為 77.5,超過 Kimi K2(75.1)和 Claude Opus 4 不思考(74.9),展示了在研究生級別科學推理和複雜問題解決能力中的卓越表現。
數學問題解決: AIME25 為 70.3,顯著領先於 Kimi K2(49.5)和 DeepSeek-V3-0324(46.6),證明了高級競賽數學技能。
實際編程性能: LiveCodeBench v6 為 51.8,超過 Kimi K2(48.9)和 DeepSeek-V3-0324(45.2),驗證了在實際場景中強大的編程能力。
優越的對話性能: Arena-Hard v2 為 79.2,超越 DeepSeek-V3(66.1)和 Qwen3-235B-A22B 不思考(52.0),確認了在複雜的開放性任務中卓越能力及強有人偏好對齊能力。
工具使用和功能調用: BFCL-v3 為 70.9,領先於 Qwen3-235B-A22B 不思考(68.0)和 Kimi K2(65.2),展示了在外部工具整合和 API 使用上的高級能力。
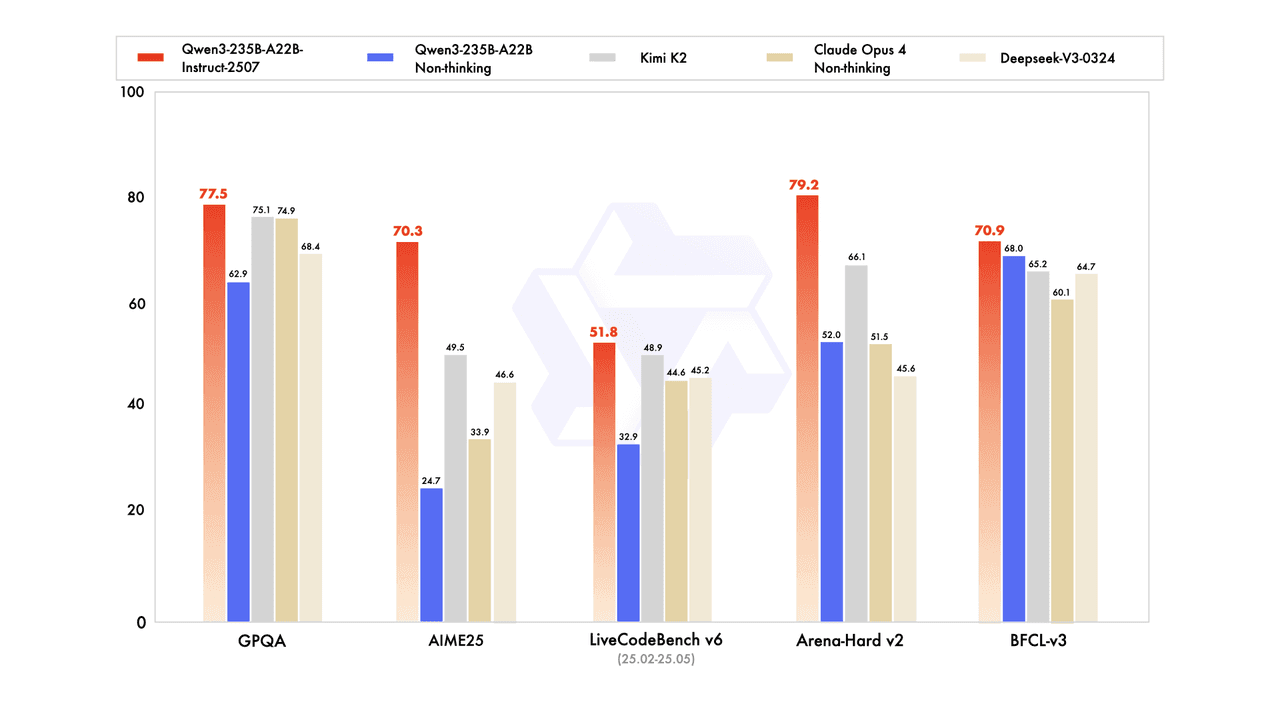
這些令人印象深刻的結果強調了開源 AI 開發中的重要里程碑。Qwen3-235B-A22B-Instruct-2507 不僅在多個基準測試中匹敵而且超過了 Claude Opus 4 不思考等專有模型,展示了開源模型在能力上達到了新高度。
立即開始
整合: 使用我們的 OpenAI 兼容 API。在SiliconFlow API 文檔中探索完整的 API 規格。
立即在 SiliconFlow 上嘗試並親身探索這些強大能力!
