今天,我們很高興介紹GLM-4.5V——世界上性能最佳的開源100B規模視覺推理模型——現已在SiliconFlow上推出。基於Z.ai的旗艦文本基礎模型GLM-4.5-Air,GLM-4.5V旨在賦能複雜問題解決、長程上下文理解和多模態代理。遵循GLM-4.1V-Thinking的技術方法,它還強調推動多模態推理和實際現實應用。
無論是準確解讀圖像和視頻,從複雜文檔中提取見解,還是通過智能代理自主地與圖形用戶界面交互,GLM-4.5V都能提供強大的性能。
使用SiliconFlow的GLM-4.5V API,您可以預期:
經濟實惠的定價:GLM-4.5V $0.14/百萬tokens(輸入)和$0.86/百萬tokens(輸出)。
上下文長度:66K-token多模態上下文窗口。
原生支持:工具使用和圖像輸入。
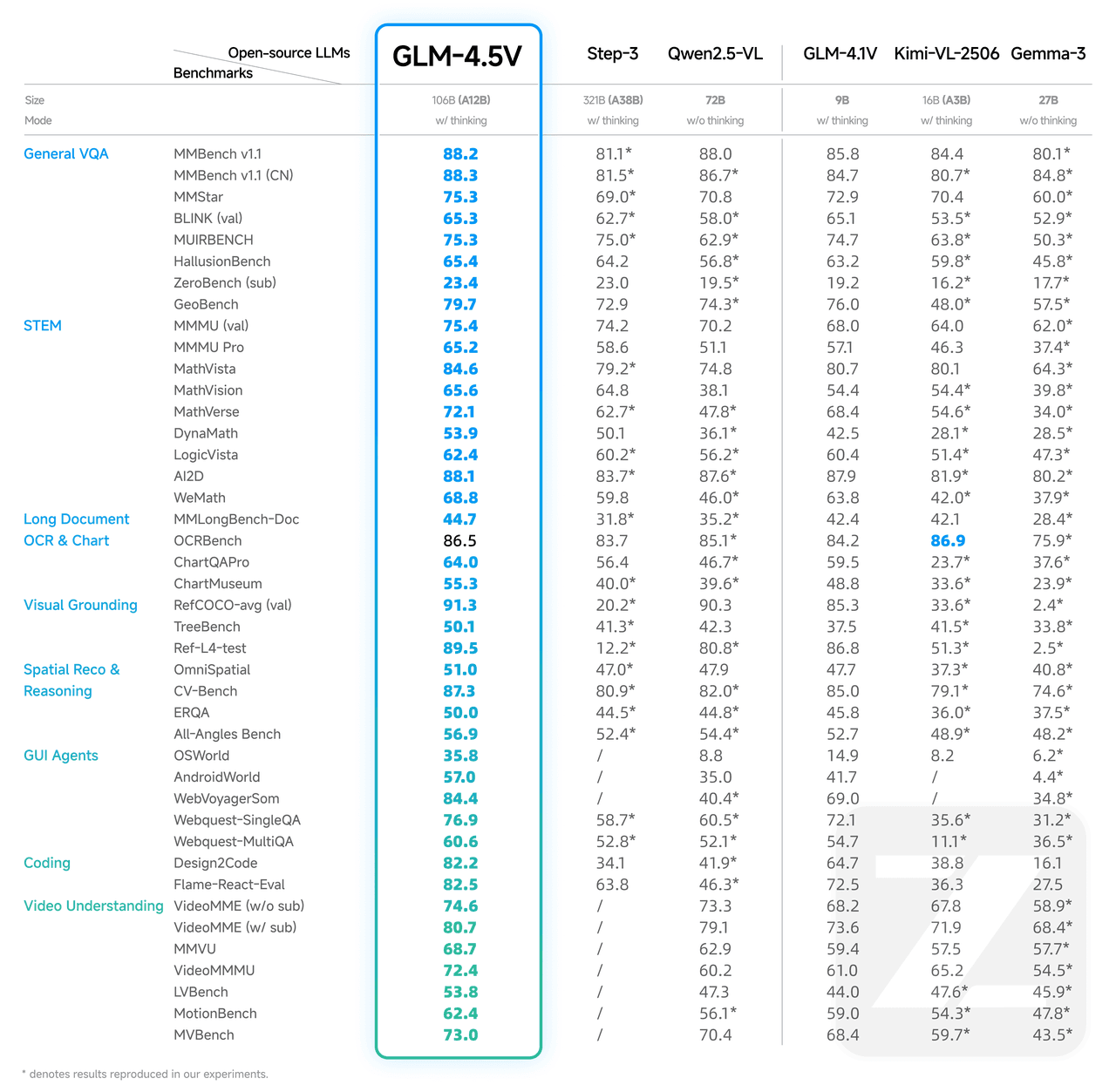
關鍵能力及基準性能
通過高效的混合訓練,它可以處理多種類型的視覺內容,實現綜合視覺推理,包括:
圖像推理:場景理解、複雜的多圖像分析、空間識別。
視頻理解:長視頻分段和事件識別。
GUI任務:屏幕讀取、圖標識別、桌面操作協助。
複雜圖表及長文檔解析:研究報告分析和信息提取。
定位:精確的視覺元素定位。
該模型還引入了思維模式開關,允許用戶在快速回應和深度推理之間取得平衡。
顯示出強大的能力,GLM-4.5V在42個公共視覺語言基準測試中達到最先進(SOTA)的性能水平,確認了其在該領域的領先地位。
技術亮點
該模型具備先進的多模態長上下文處理能力,並採用多項技術創新以增強圖像和視頻處理性能:
66K多模態長上下文處理:支持圖像和視頻輸入,並利用3D卷積提升視頻處理效率。
雙三次插值機制:提高處理高解析度和極端寬高比圖像的穩健性和能力。
3D旋轉位置編碼(3D-RoPE):加強模型對多模態信息中三維空間關係的感知和推理。
GLM-4.5V還遵循三階段訓練策略:預訓練、監督微調(SFT)和強化學習(RL):
預訓練階段:大規模交錯的多模態語料庫和長上下文數據被用來增強模型處理複雜圖像–文本和視頻內容的能力。
SFT階段:引入明確的思維鏈格式化訓練樣本,以改善GLM-4.5V的因果關係推理和多模態理解能力。
RL階段:透過構建多領域獎勵系統結合可驗證的獎勵為基礎的強化學習(RLVR)和從人類反饋中學習的強化學習(RLHF),應用於多領域多模態課程強化學習,使STEM問題、多模態定位及代理任務得以全面優化。

SiliconFlow上的現實表現
在提供展示多個產品的電子商務頁面時,GLM-4.5V能夠識別圖像中的折扣和原價,然後準確計算折扣率。

來自我們社區的開發者對GLM-4.5V的反饋非常正面。
現在加入社區探索更多使用案例,分享您的成果並獲得第一手支持!
立即開始
探索:在SiliconFlow體驗中心試用GLM-4.5V。
整合:使用我們與OpenAI相容的API。在SiliconFlow API文檔中探索完整的API規格。
import requests
url = "https://api.siliconflow.com/v1/chat/completions"
payload = {
"model": "zai-org/GLM-4.5V",
"max_tokens": 512,
"enable_thinking": True,
"thinking_budget": 4096,
"min_p": 0.05,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"messages": [
{
"content": "how are you",
"role": "user"
}
]
}
headers = {
"Authorization": "Bearer <token>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())import requests
url = "https://api.siliconflow.com/v1/chat/completions"
payload = {
"model": "zai-org/GLM-4.5V",
"max_tokens": 512,
"enable_thinking": True,
"thinking_budget": 4096,
"min_p": 0.05,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"messages": [
{
"content": "how are you",
"role": "user"
}
]
}
headers = {
"Authorization": "Bearer <token>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())import requests
url = "https://api.siliconflow.com/v1/chat/completions"
payload = {
"model": "zai-org/GLM-4.5V",
"max_tokens": 512,
"enable_thinking": True,
"thinking_budget": 4096,
"min_p": 0.05,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"messages": [
{
"content": "how are you",
"role": "user"
}
]
}
headers = {
"Authorization": "Bearer <token>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())準備好擴展規模了嗎?聯繫我們以進行企業部署、自訂整合和GLM-4.5V的大量定價。

