Table of Contents

TL;DR:Qwen3-VL-8B — the newest member of the Qwen3-VL family — is now live on SiliconFlow. This compact vision-language model delivers full-scale multimodal reasoning in both Instruct and Thinking variants, with significantly lower VRAM consumption. Despite its 8B parameter size, it inherits the complete capabilities of the flagship Qwen3-VL-235B — from advanced text generation to spatial and video understanding — while outperforming larger models like Gemini 2.5 Flash Lite and GPT-5 Nano. Proving that efficiency meets performance, Qwen3-VL-8B is now available through SiliconFlow's production-ready API.
Expanding the Qwen3-VL ecosystem, SiliconFlow is excited to introduce **Qwen3-VL-8B series to our model catalog** — a compact yet powerful Dense vision-language model that redefines the balance between parameter size and multimodal capability. Available in both Instruct and Thinking variants, it inherits the full capabilities of its flagship siblings, Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-235B-A22B-Thinking, including superior text understanding and generation, deeper visual perception and reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent capabilities.
With SiliconFlow's Qwen3-VL-8B API, you can expect:
Budegt-Friendly Pricing:
Qwen3-VL-8B-Instruct: $0.18/M tokens (input) and $0.68/M tokens (output)
Qwen3-VL-8B-Thinking: $0.18/M tokens (input) and $2.00/M tokens (output)
262K Context Window: Supports long-form multimodal understanding across text, images, and video.
Seamless Integration: Instantly build with SiliconFlow's OpenAI**/Anthropic-compatible API**, or integrate into your existing workflow.
WhyQwen3-VL-8B Matters
Building on the Qwen3-VL family's foundation, the 8B variant introduces a comprehensive set of enhancements designed for real-world applications:
Visual Agent Capabilities: Operates PC/mobile GUIs — recognizes elements, understands functions, invokes tools, and completes tasks autonomously.
Advanced Spatial Perception: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
Visual Coding Boost: Generates Draw.io/HTML/CSS/JS from images and videos.
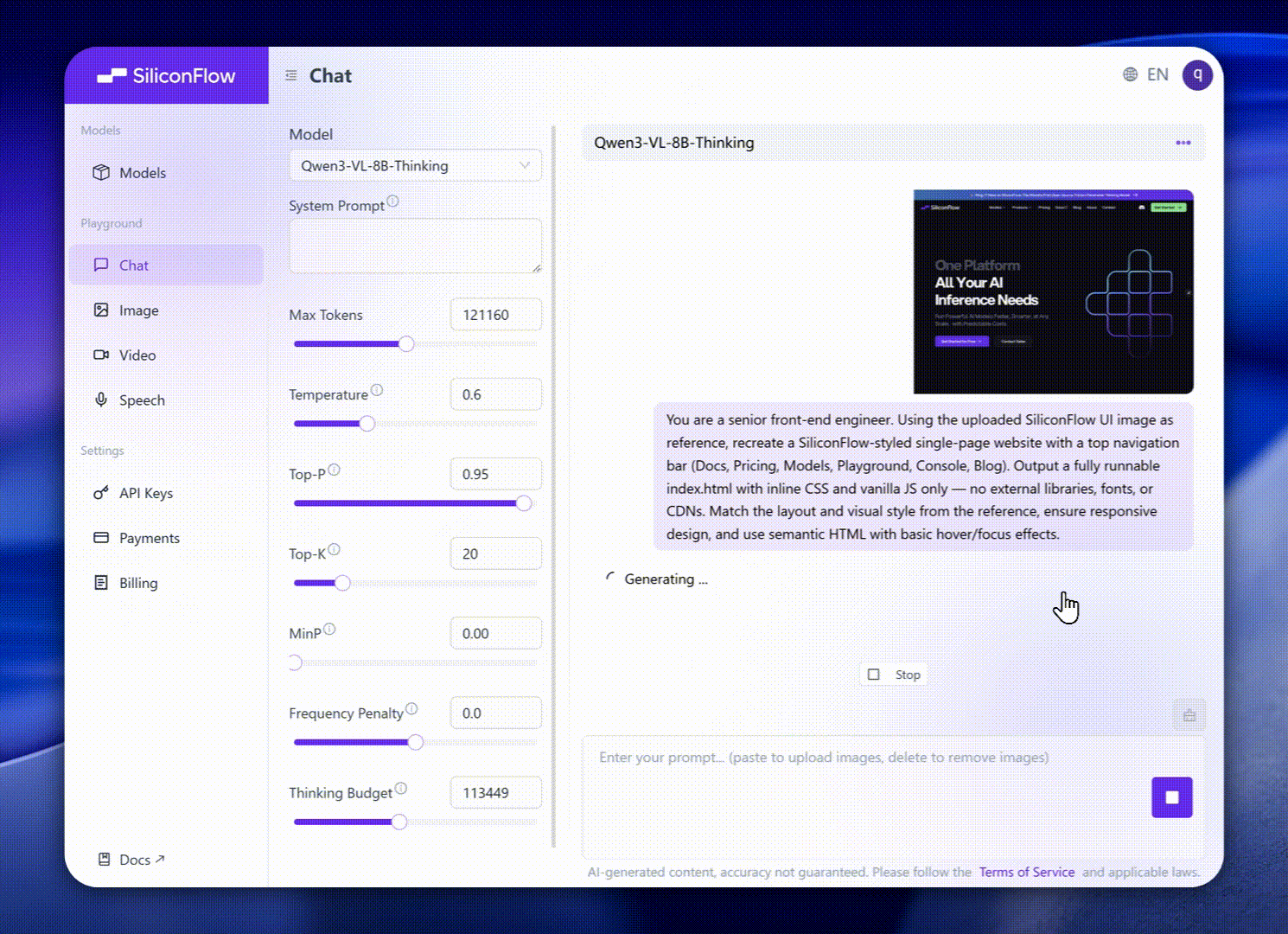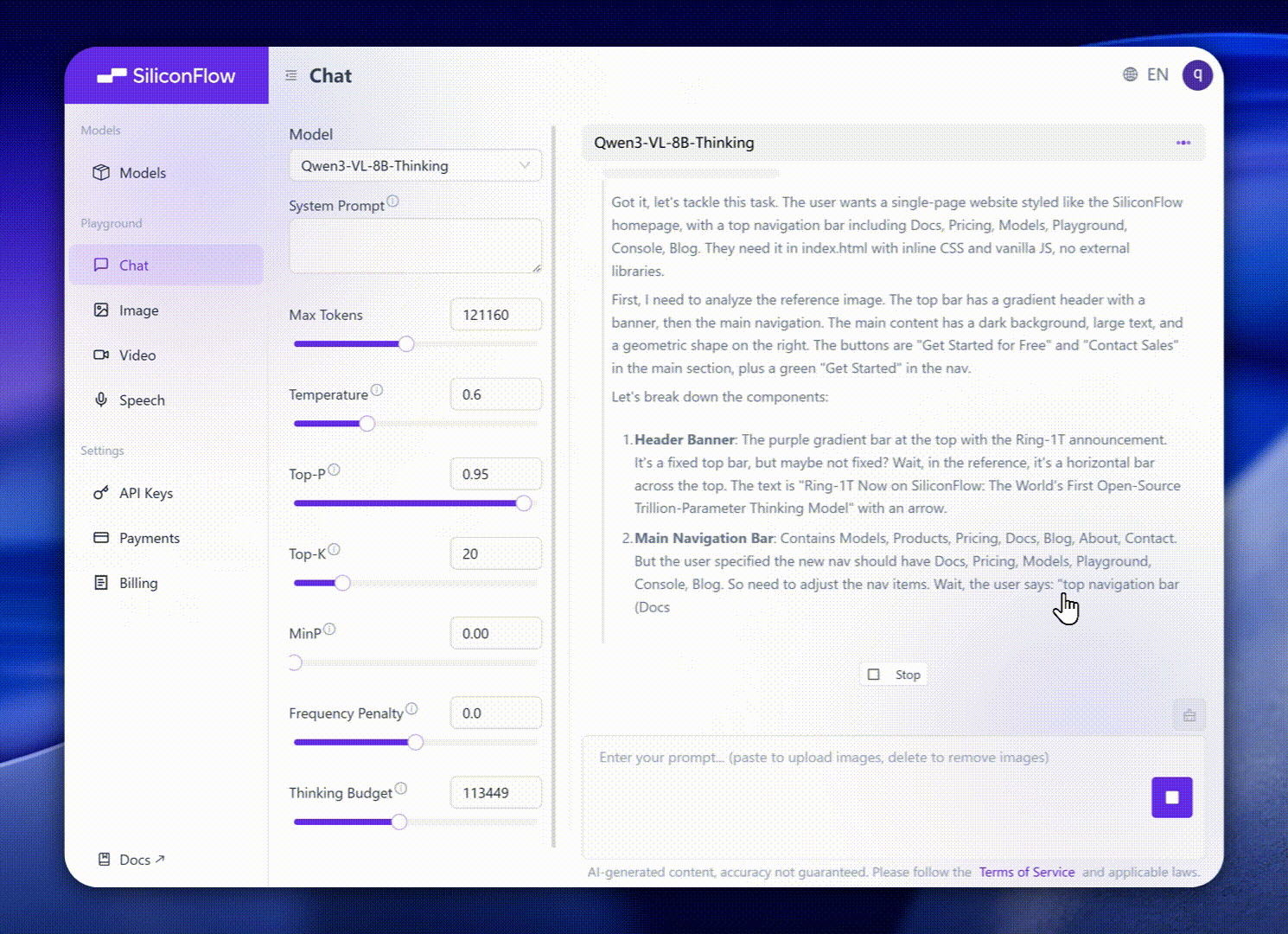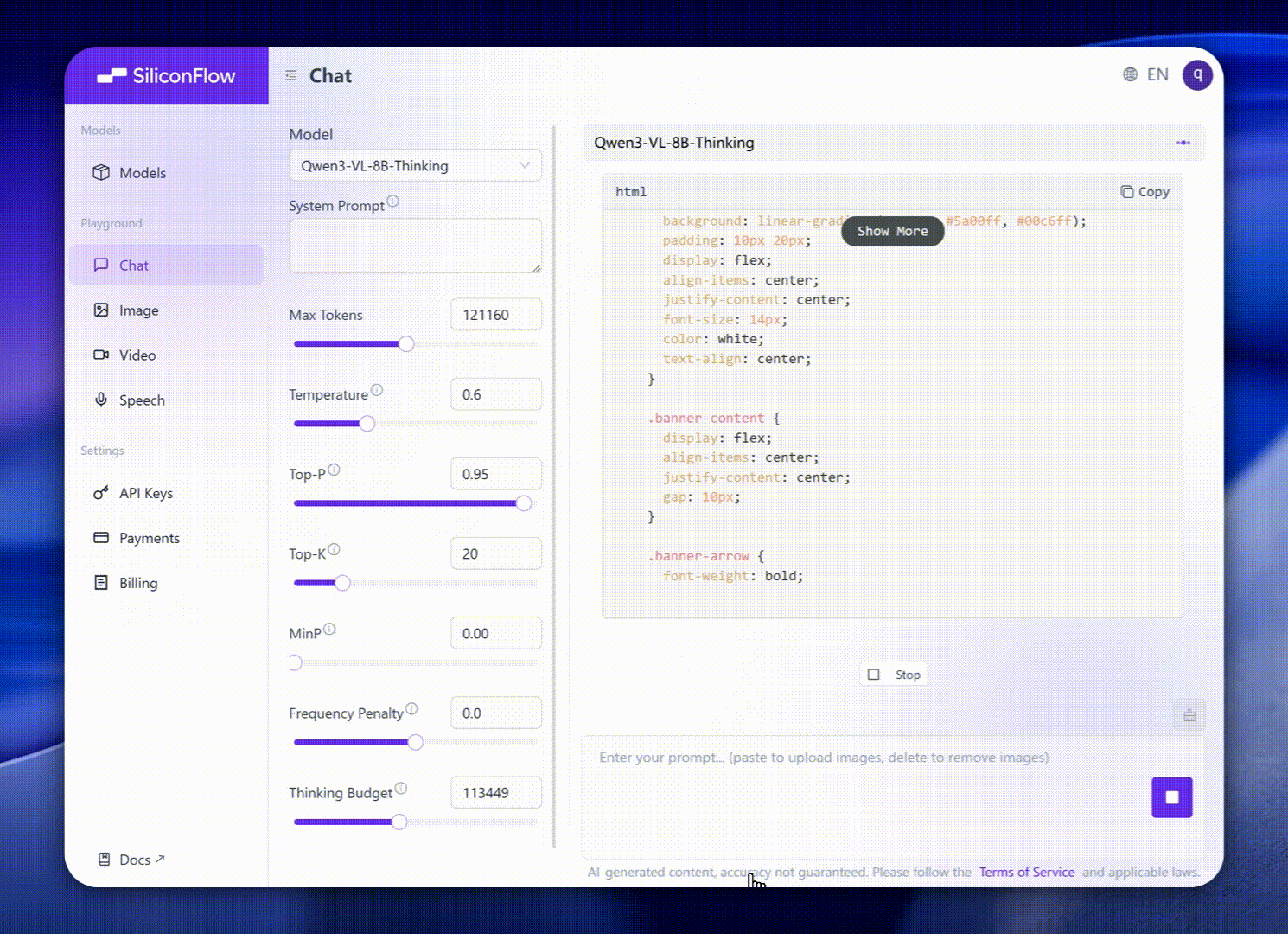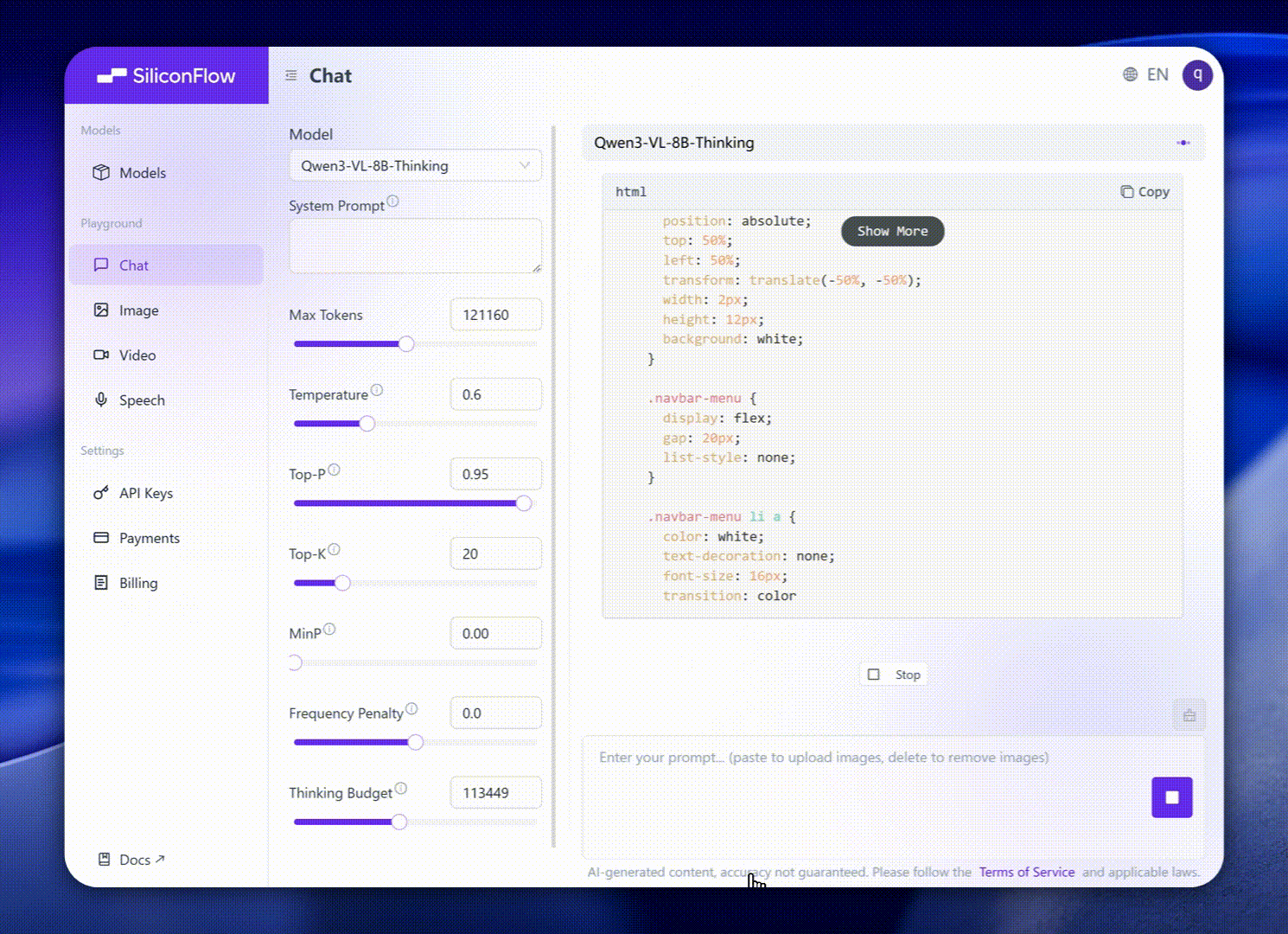
Long Context & Video Understanding: Native 256K context (expandable to 1M), handles books and hours-long video with full recall and second-level indexing.
Enhanced Multimodal Reasoning: Excels in STEM/Math with causal analysis and logical, evidence-based answers.
Expanded OCR: Supports 32 languages (up from 19), with enhanced robustness under low light, blur, and tilt conditions, improved handling of rare or ancient characters and technical jargon, and better long-document structure parsing.
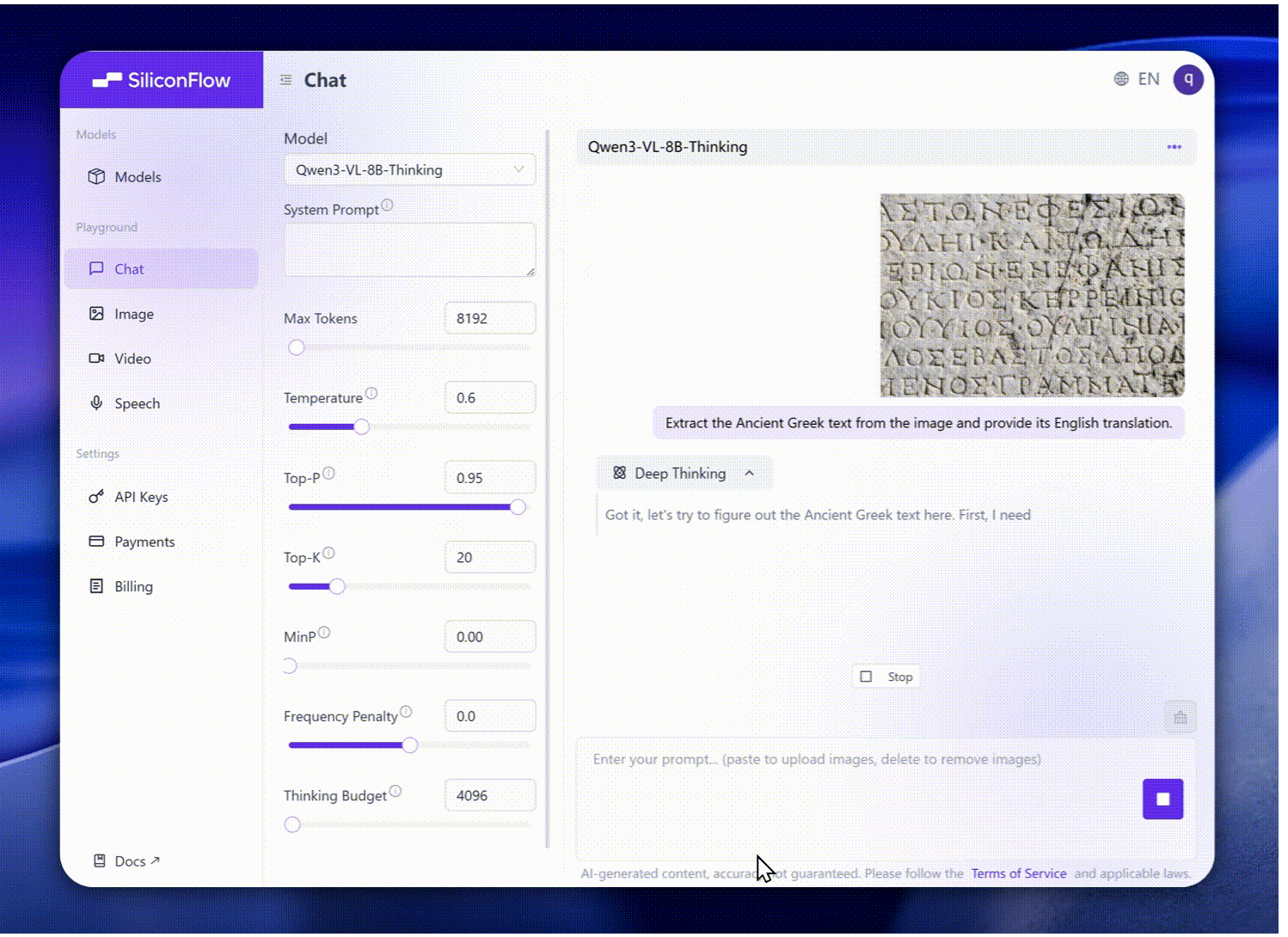
Upgraded Visual Recognition: Broader, higher-quality pretraining enables comprehensive recognition — celebrities, anime, products, landmarks, flora/fauna, and more.
Text Understanding on Par with Pure LLMs: Seamless text-vision fusion for lossless, unified comprehension.
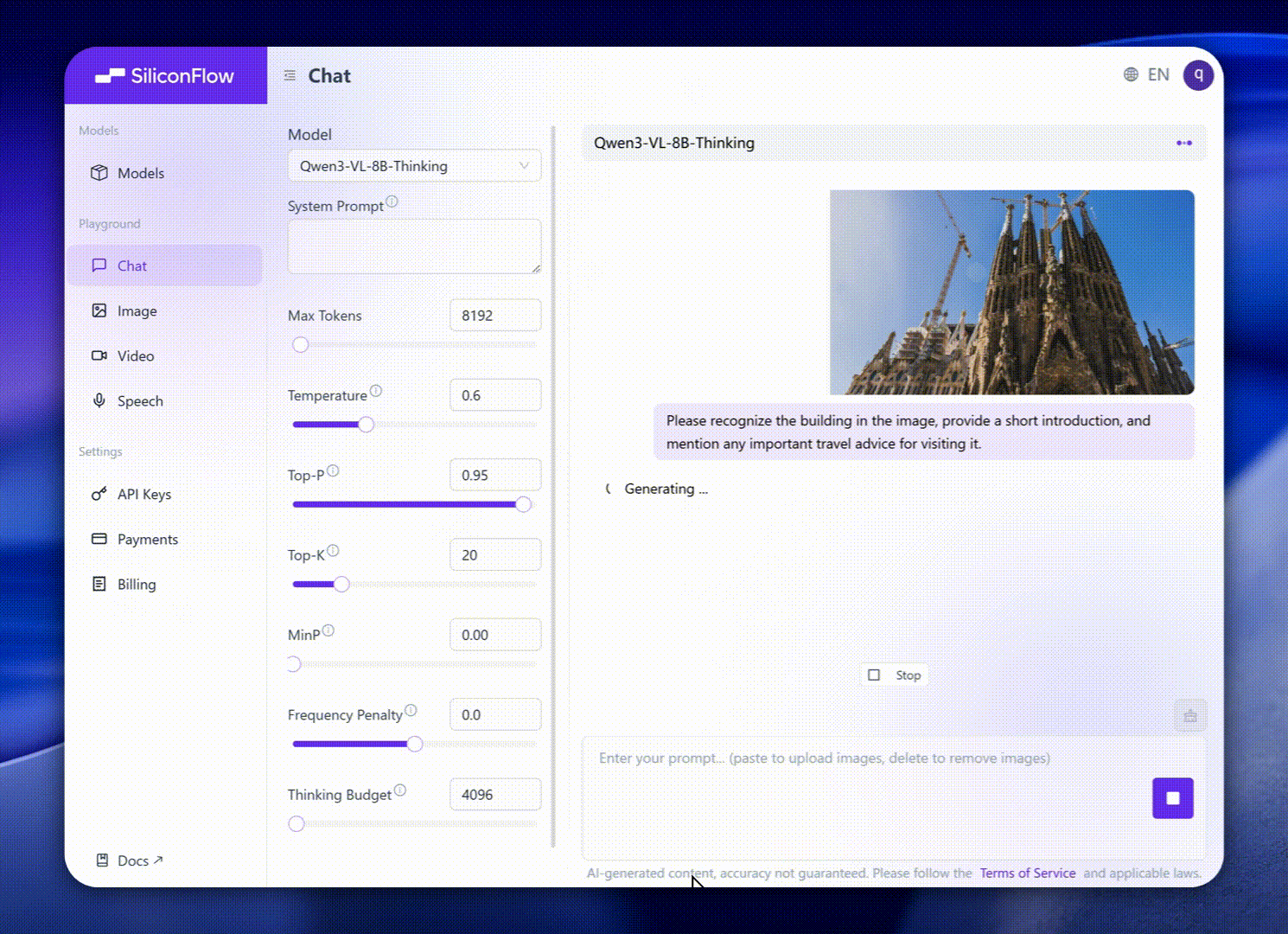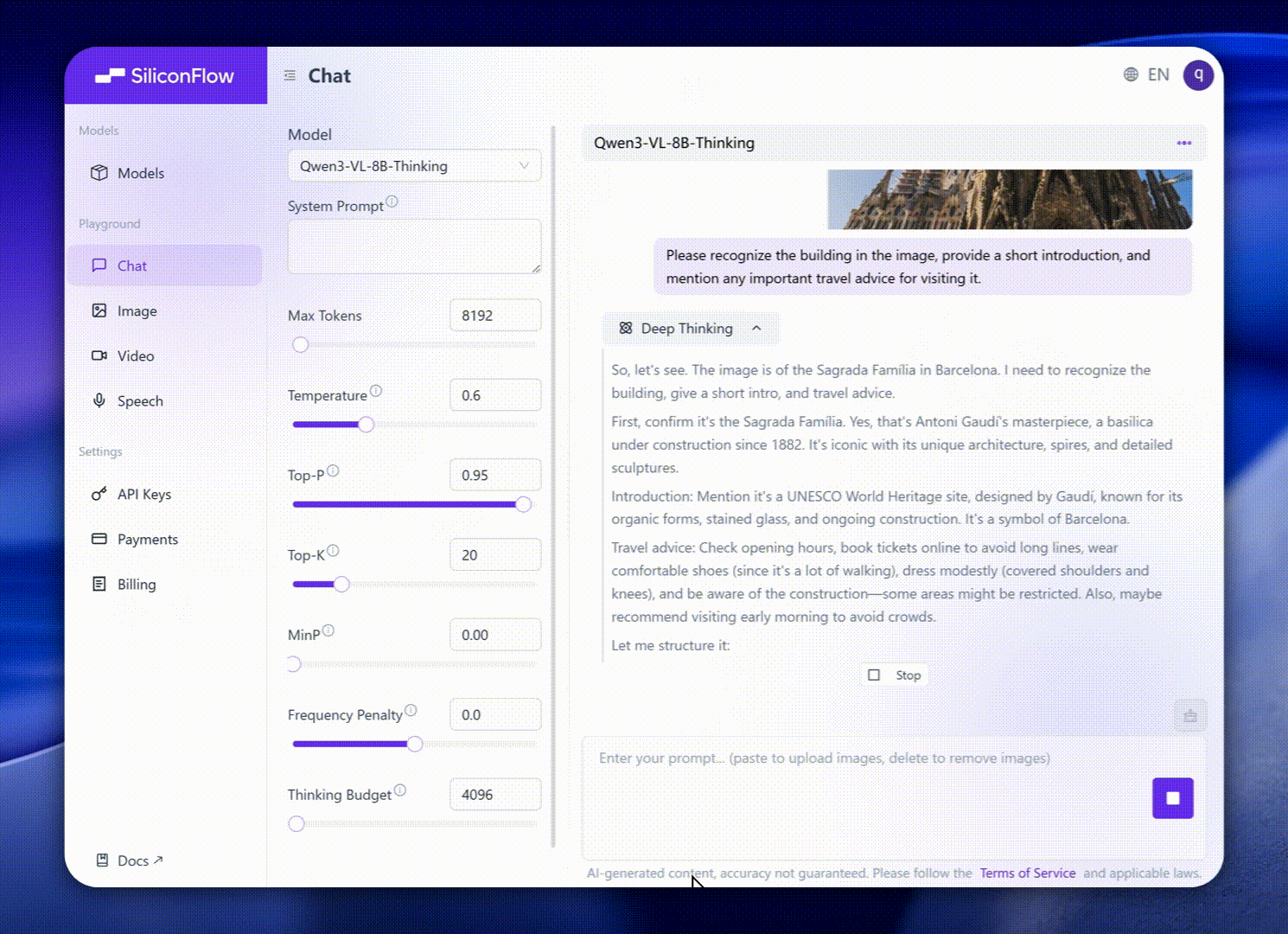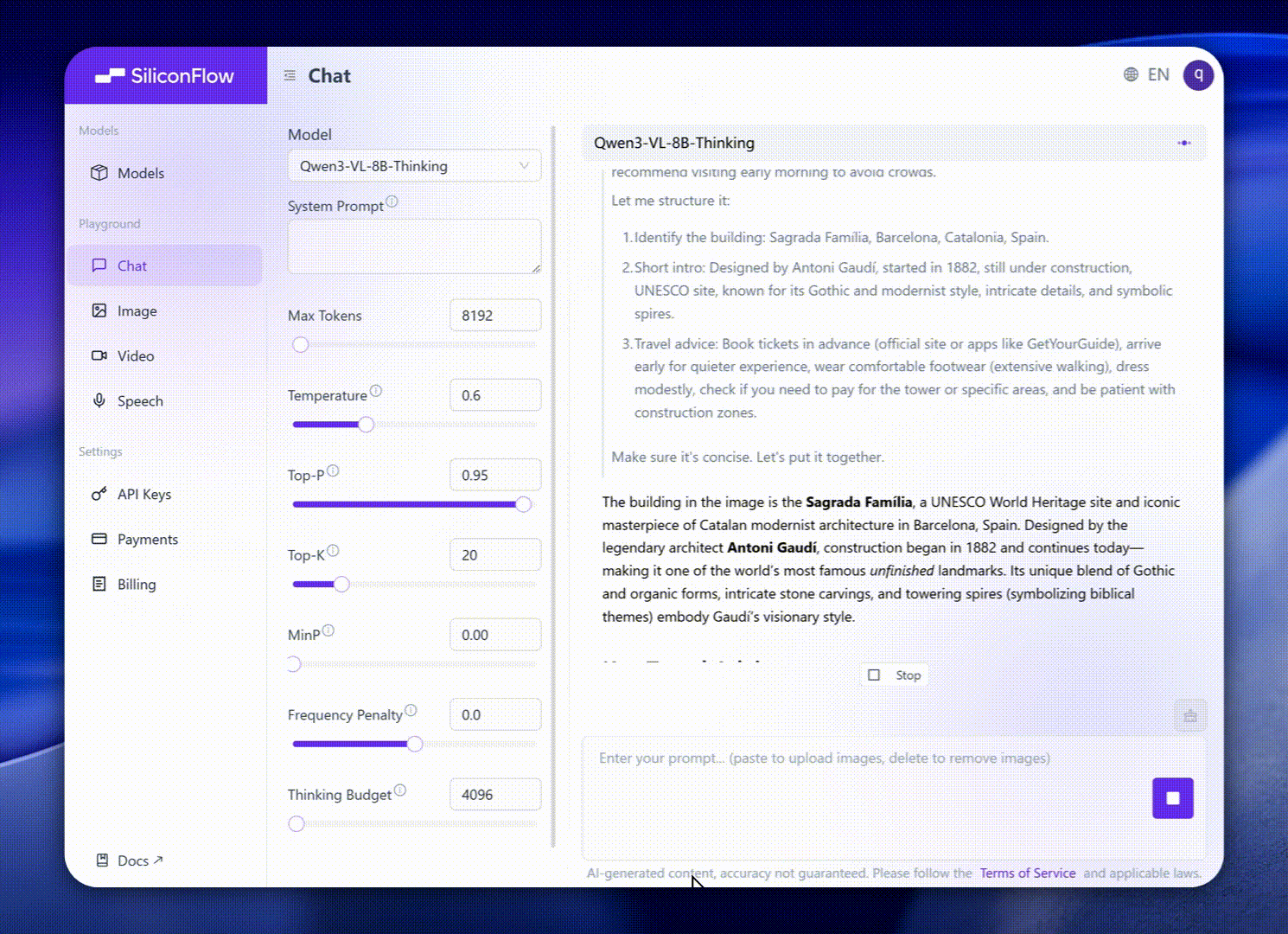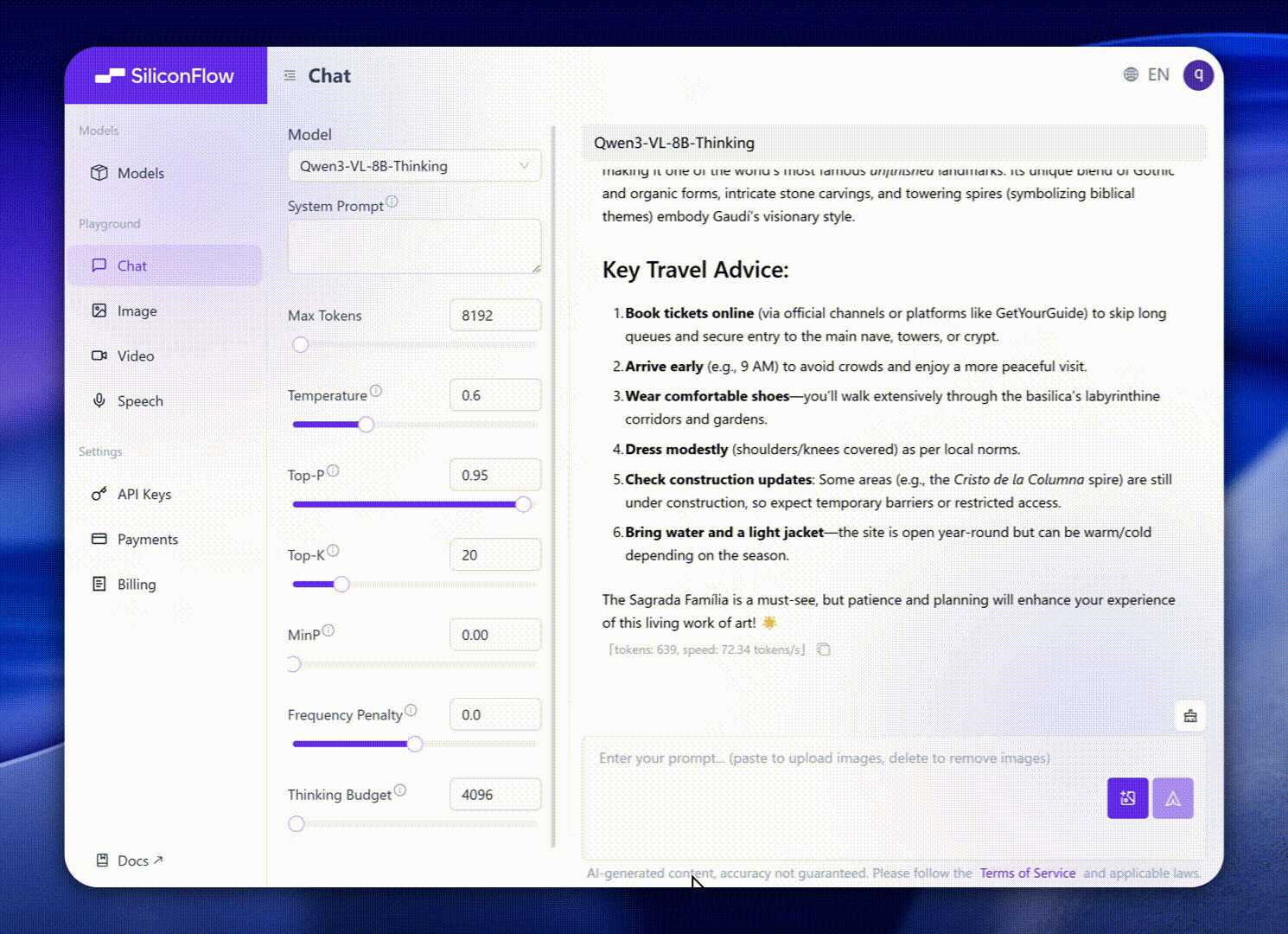
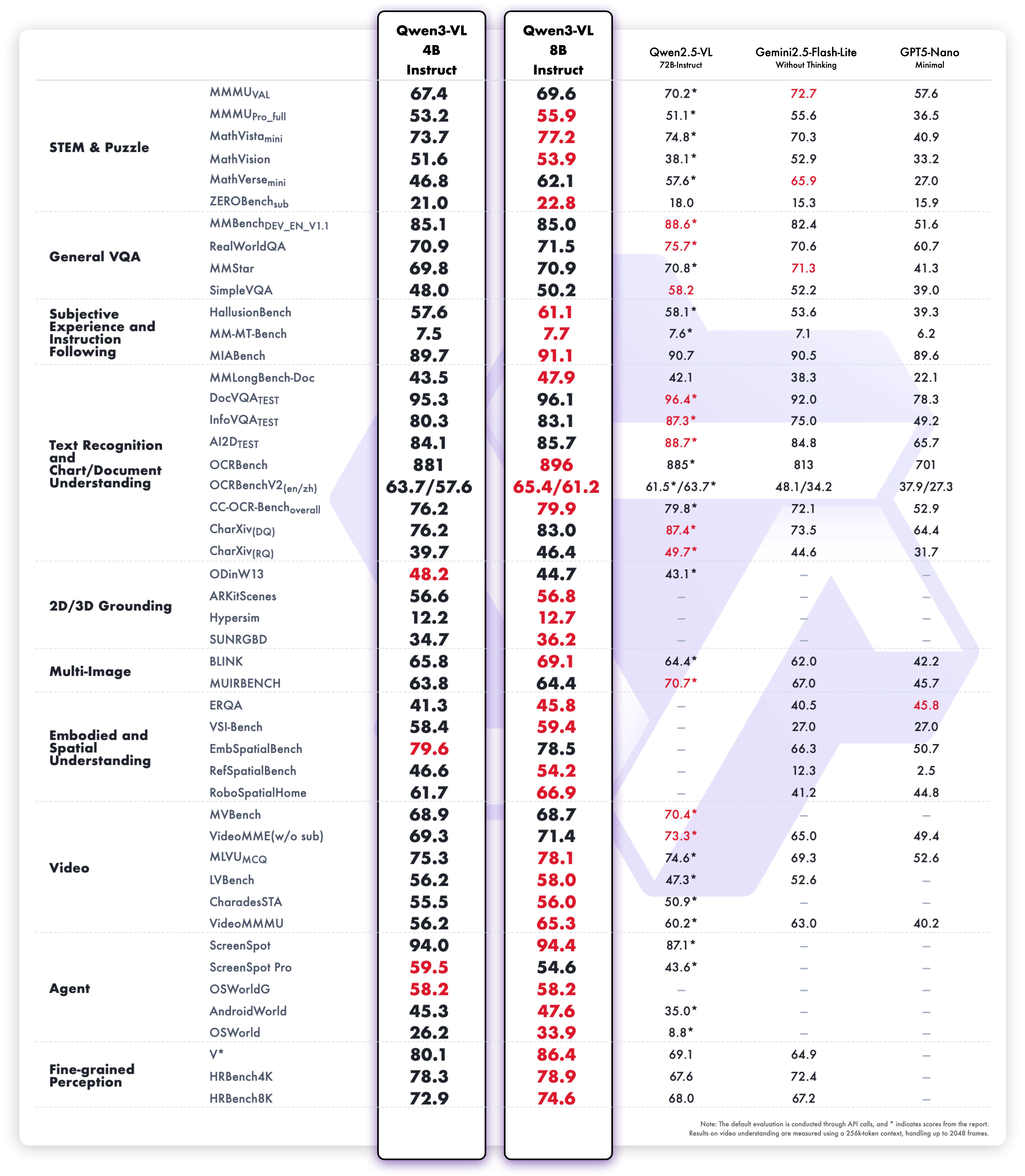
These enhancements translate into exceptional real-world benchmark performance. Qwen3-VL-8B delivers outstanding performance across public benchmarks in STEM, VQA, OCR, video understanding, and agent-based tasks — surpassing Gemini 2.5 Flash Lite and **GPT-5 Nano, and even rivaling the much larger Qwen2.5-VL-72B**.
Notably, it achieves impressive spatial reasoning performance, offering a strong foundation for advancing embodied intelligence applications.
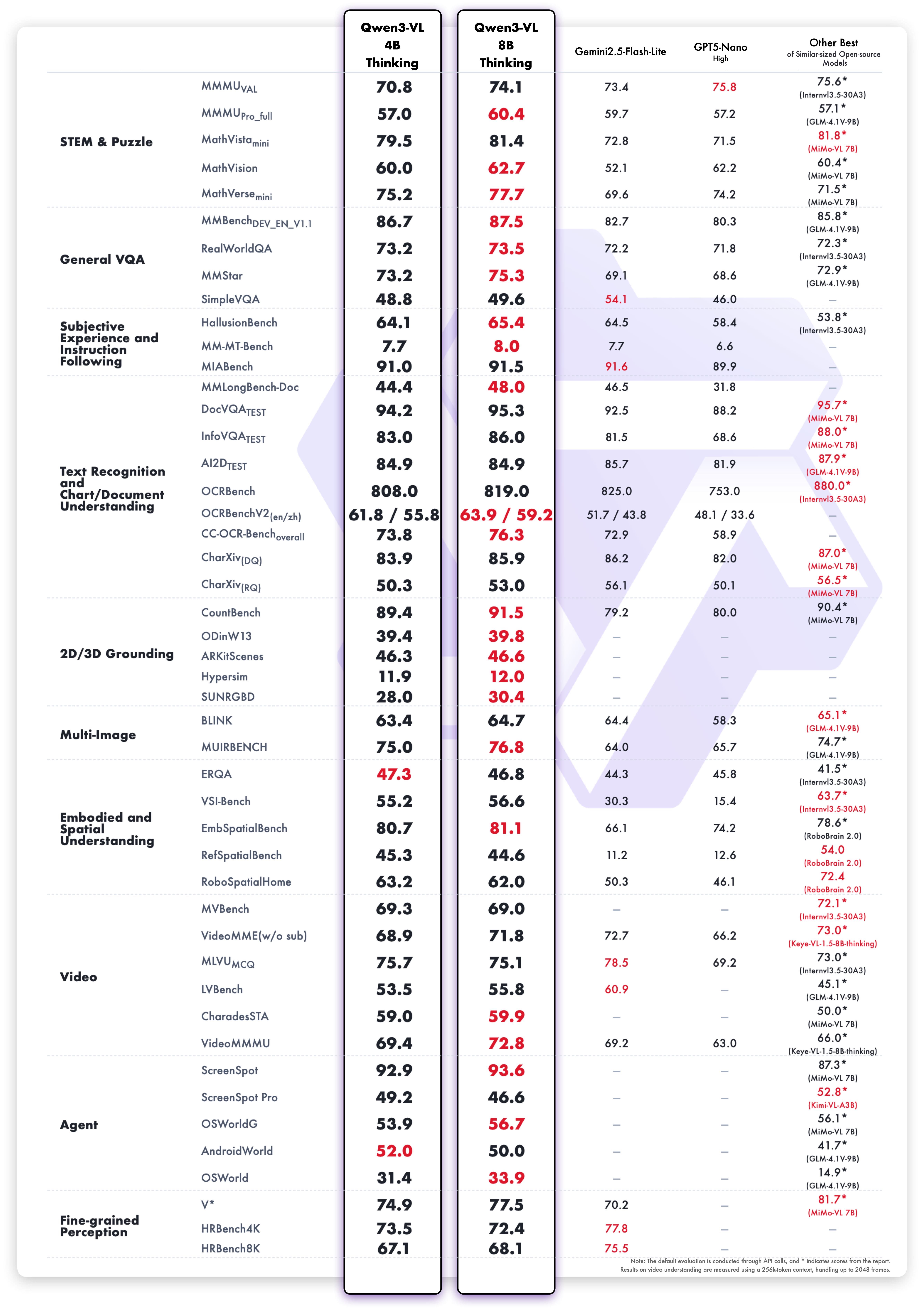
Also, smaller multimodal models always face a fundamental tradeoff: improving visual capabilities often compromises text understanding, and vice versa. This "seesaw effect" has long been a barrier to creating compact yet capable vision-language models. Qwen3-VL-8B overcomes this limitation through balanced co-optimization of vision precision and text robustness.
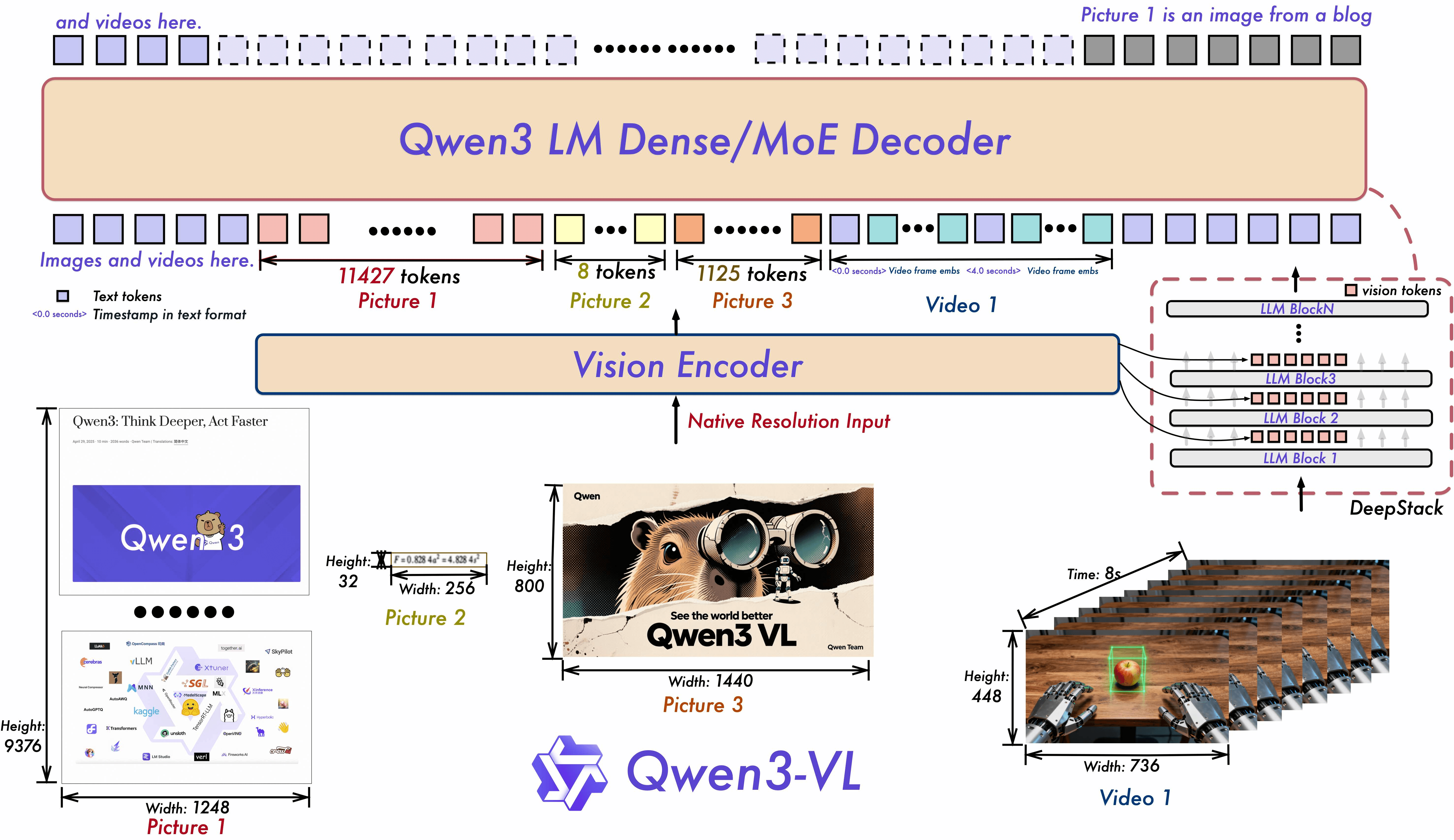
Through architectural innovations and technical optimization, the model significantly enhances multimodal perception while maintaining the powerful text comprehension demonstrated in the benchmarks below.
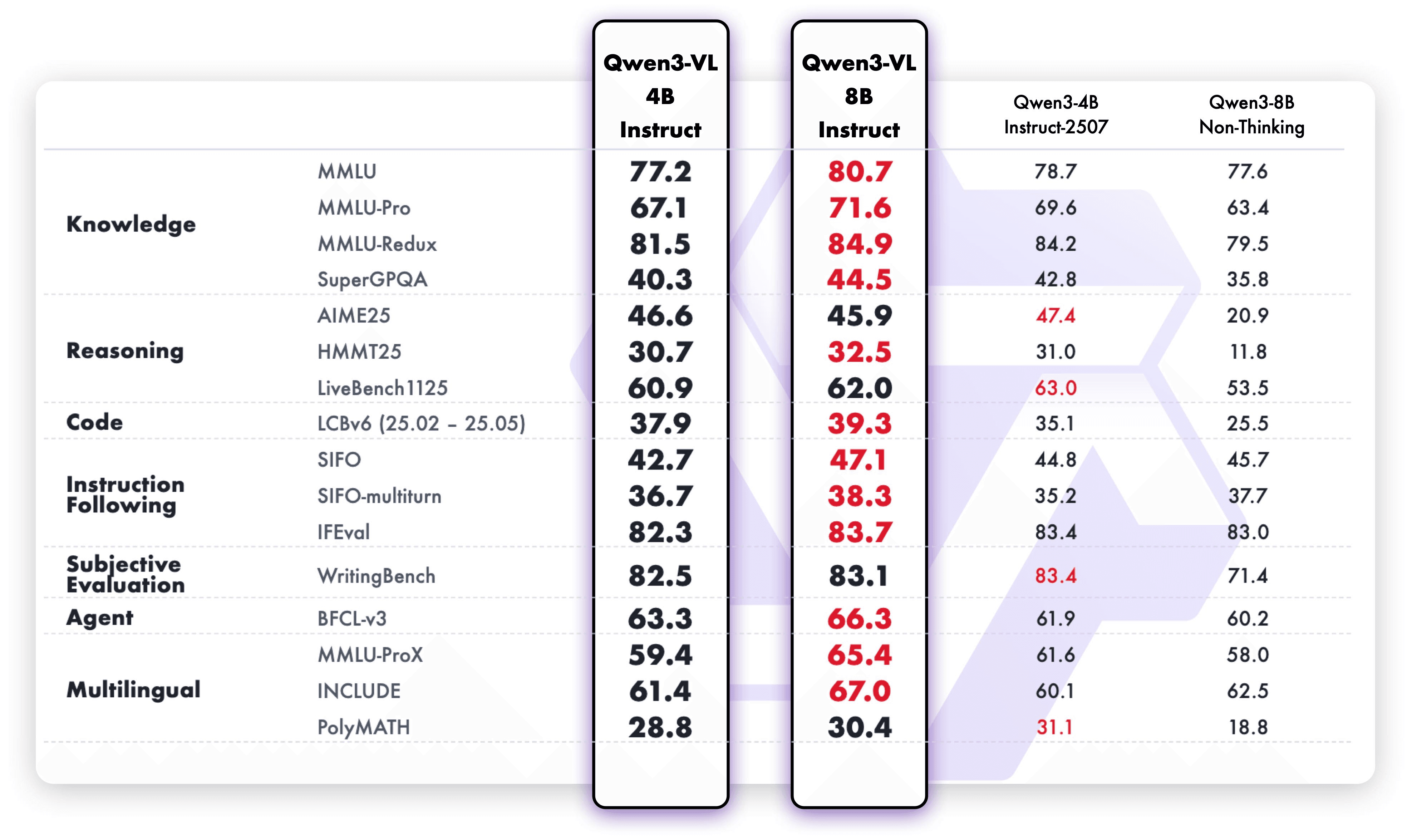
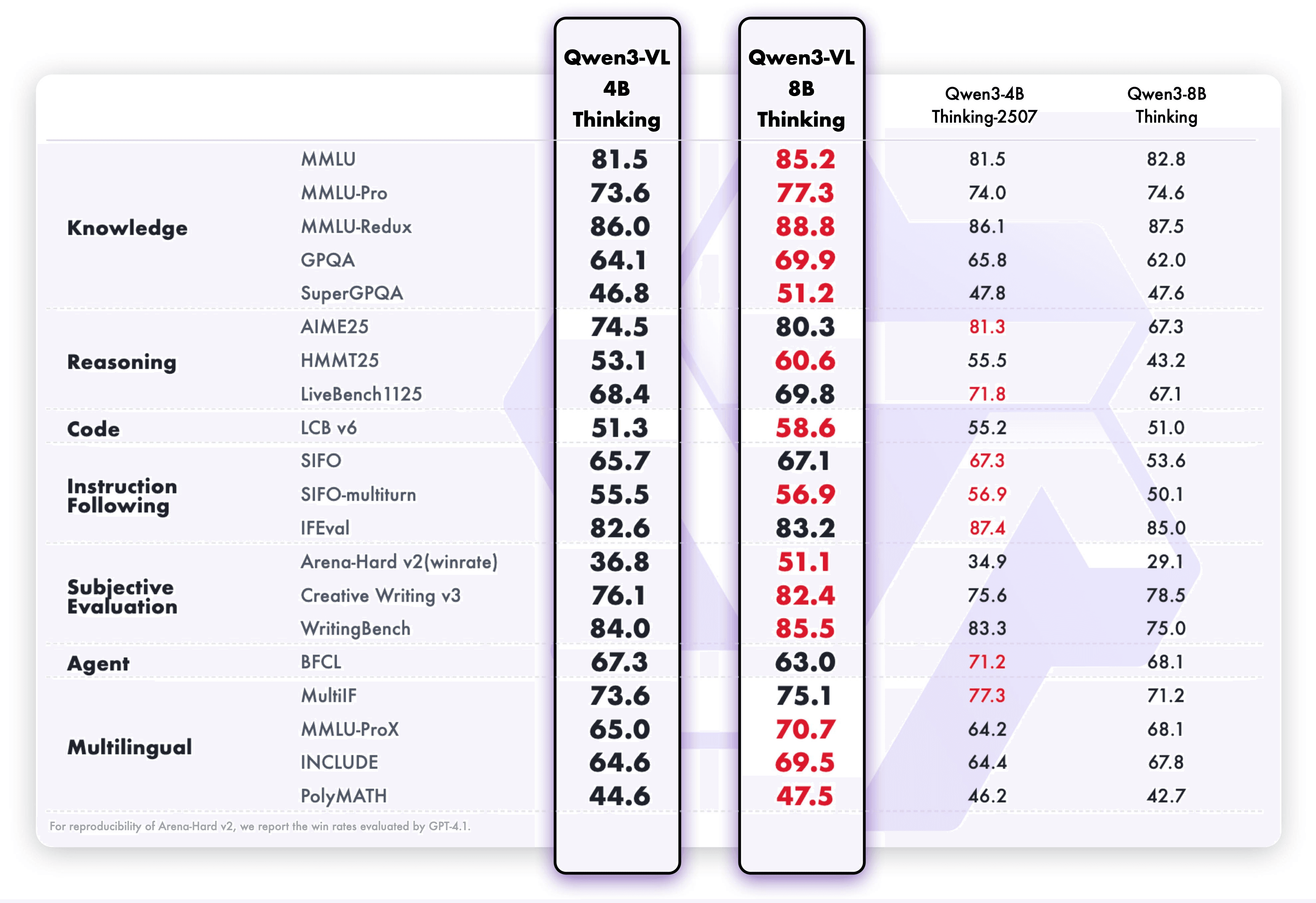
The result? More capability now fits into a smaller model — from recognition to reasoning, from text to images and videos.
Real-world Application Scenarios
With its compact 8B dense architecture and full-spectrum multimodal capability, Qwen3-VL-8B brings advanced visual intelligence to real-world workflows:
Visual Reasoning & STEM Tasks: Interpret diagrams, charts, and mathematical formulas to solve geometry, physics, or chemistry problems with clear logical explanations. Ideal for education, research, and AI tutoring systems.
Document Understanding & OCR: Extract and summarize information from scanned documents, receipts, or technical papers across 32 languages. Supports complex layout parsing, table recognition, and structured data conversion.
Dynamic Vision & Agent Interaction: Analyze video frames, recognize GUI elements, and simulate interactions within PC or mobile interfaces — enabling autonomous agents that can “see, reason, and act” in real-world environments.
Multimodal Creation: Convert visual inputs into creative or technical outputs, such as generating HTML/CSS/JS layouts from screenshots or writing descriptive narratives from images and clips.
Whether you're building intelligent assistants, document analysis systems, or creative multimodal tools, Qwen3-VL-8B brings flagship-level multimodal intelligence to your workflow via SiliconFlow's API services.
Get Started Immediately
Explore: Try Qwen3-VL-8B series in the SiliconFlow playground.
Integrate: Use our OpenAI-compatible API. Explore the full API specifications in the SiliconFlow API documentation.
Start building with Qwen3-VL-8B today and experience flagship-level multimodal intelligence through SiliconFlow's production-ready API!
