Table of Contents

TL; DR: Built on the new MiniMax Sparse Attention (MSA) architecture, MiniMax M3 unites frontier-grade coding and agentic capability, a 1M-token context window, and native multimodality in a single open-weight model. It scores 83.5 on BrowseComp — ahead of Opus 4.7 (79.3) — and tops GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro, while delivering up to 9.7× prefilling and 15.6× faster decoding at full context. Start building with SiliconFlow's API right now.
Try MiniMax M3 on SiliconFlow
Cost-effective Pricing: $0.12 / $0.60 / $2.40 per 1M tokens (Cached Input / Input / Output); and 50% off for 7 days through June 7th: $0.06 / $0.30 / $1.20 per 1M tokens (Cached Input / Input / Output).
Seamless Integration: Instant compatibility with your existing development ecosystem, deploy via SiliconFlow's OpenAI-Compatible API through Cline, Gen-CLI, Kilo Code, Roo Code ; Anthropic-Compatible API with Claude Code; plug into agents like OpenClaw, Hermes Agent; ready-to-use in Dify, Janitor AI, Chub AI, ChatHub, Chatbox, Sider; and also available through OpenRouter.
Key Features & Benchmark Performance
Overview
MiniMax M3, the first open-weight model with three frontier capabilities, pairs frontier-level software engineering and agentic performance with a 1M-token context window and multimodal understanding trained in from step zero, enabling developers to run long-horizon coding agents, whole-codebase analysis, and image & video grounded workflows with greater efficiency and reliability.
As a next-generation agentic foundation model, MiniMax M3 sets a new benchmark for what an open model can do at extreme context lengths — closing the gap with the small set of closed frontier systems that, until now, were the only ones to own all three capabilities at once.
Highlights
Frontier coding and agentic capability, with autonomous task decomposition, tool invocation, and multi-step reasoning.
A 1M-token context window powered by MSA, with a guaranteed minimum of 512K tokens.
Native multimodality across text, image, and video inputs — plus computer-use, baked into the model rather than bolted on.
The first open-weight model to combine all three frontier capabilities in one system.
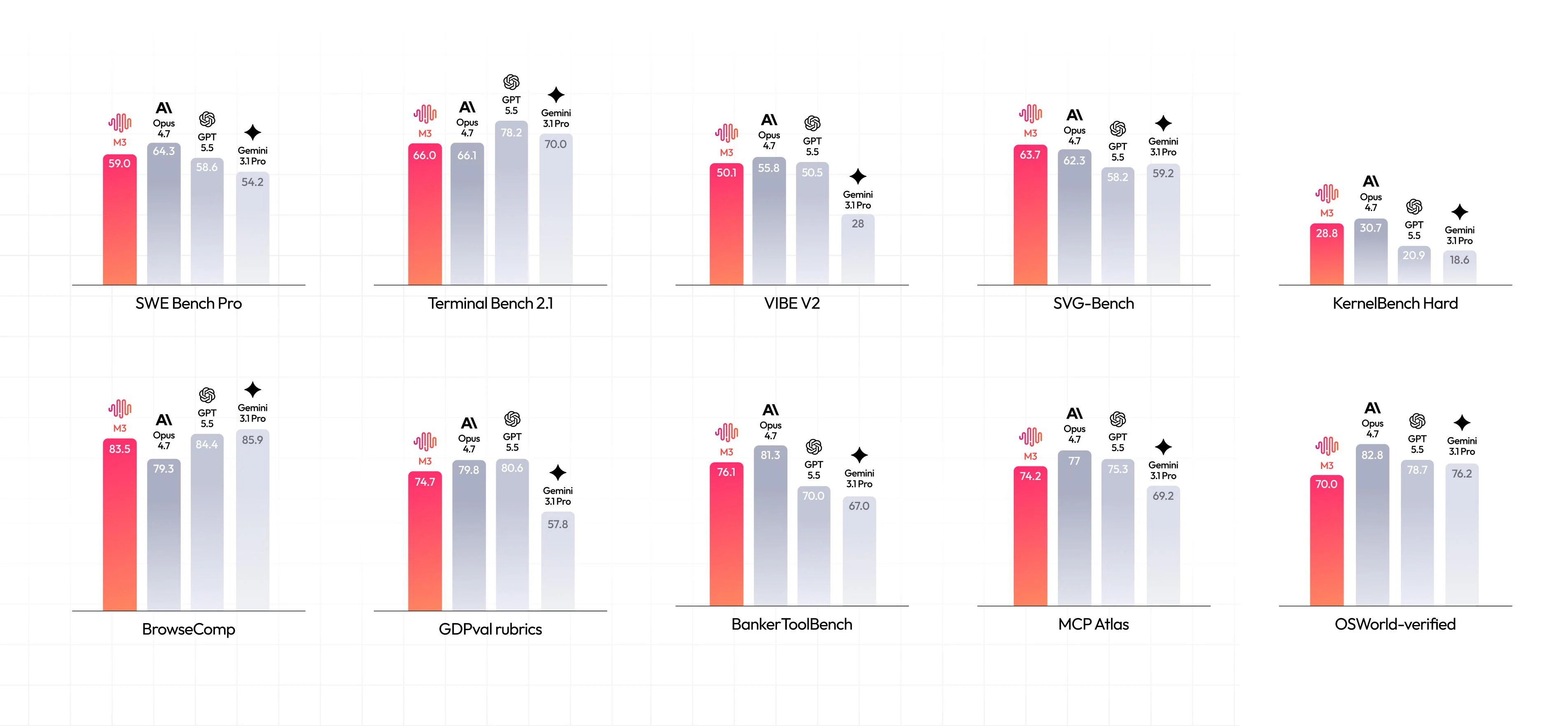
Benchmark Performance
Coding and agentic capabilities are key areas of improvement for MiniMax M3.
SWE-Bench Pro: Outperforms GPT-5.5 and Gemini 3.1 Pro on software-engineering tasks, approaching Opus 4.7.
BrowseComp: 83.5, surpassing Opus 4.7 (79.3) on autonomous browsing and information retrieval.
SVG-Bench: 63.7, edges out Opus 4.7 (62.3) , GPT-5.5 (58.2) and Gemini 3.1 Pro (59.2) on SVG generation performance.
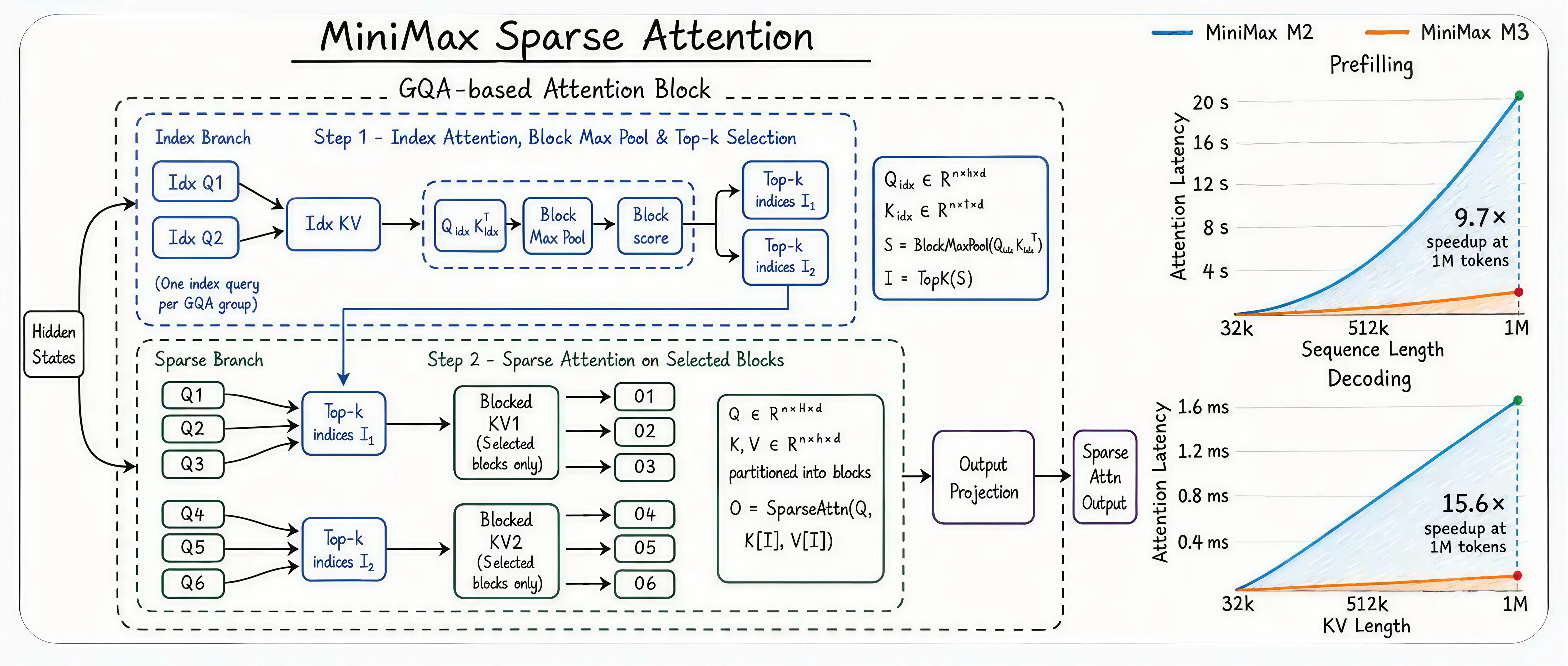
Architectural Innovations
MiniMax M3 introduces MiniMax Sparse Attention (MSA), a clean and scalable architecture that makes context a dimension can actually scale. Its enhancements include:
Precise KV-block selection: MSA adds a lightweight screening stage that chunks the KV cache more accurately than schemes like DSA and MoBA, giving higher effective context coverage instead of just cheaper attention.
Operator-level optimization: A KV-outer-gather-Q kernel reads each block once with contiguous memory access, running more than 4× faster than open implementations such as Flash-Sparse-Attention and flash-moba.
Order-of-magnitude efficiency at scale: At 1M tokens, M3 spends about 1/20 the per-token compute of the prior generation, with prefill accelerated more than 9× and decoding more than 15×.
Real-World Applications
MiniMax M3 empowers developers and businesses to create cutting-edge solutions for:
Autonomous research and paper reproduction: Handed an ICLR 2025 Outstanding Paper, M3 ran for nearly 12 hours on its own, producing 18 commits and 23 experimental figures and successfully replicating the core results — reading the paper's charts and formulas, holding paper, code, and logs in a single context window, and driving the whole long-horizon job to completion.
Long-horizon systems engineering: Starting from only a task description and a non-runnable Triton skeleton, M3 optimized an FP8 GEMM kernel on NVIDIA Hopper GPUs across 147 benchmark submissions and 1,959 tool calls, pushing hardware peak utilization from 7.6% to 71.3% — a 9.4× speedup with zero human intervention.
Self-improving ML pipelines: Given four pretrain-only base models, M3 autonomously ran data synthesis, training, evaluation, and iteration within 12 hours to make them usable for math, code, and knowledge tasks — no human in the loop.
From AI-native software development to scientific research, the model helps teams accelerate development and unlock new AI-driven possibilities.
Get Started Immediately
Bulid: Try MiniMax M3 in the SiliconFlow playground.
Explore: More models from MiniMax such as MiniMax-M2.5 on SiliconFlow.
Integrate: Use our OpenAI-compatible API. Explore the full API specifications in the SiliconFlow API documentation.
Join our Discord community now →
